Off the Top: Web apps Entries
New Adoption Points
One of those things where, yet again, realize you have a really quick personal adoption threshold when a new device fills in and you start wondering why everything can’t be logged into with a fingerprint. Then there is the, “why are you calling me on my payment device?”
It has been over 30 years of having new devices arrive at semi-regular pace and quickly disrupting things for workflows around devices and interactions, which is followed often by relatively quick adoption and getting used to a new mental model that makes things a little easier. This is really true for software that is buggy and never really fixed and where I (as well as other humans are the human affordance system).
The Software Counter Model to Quick Change Adoption
As much as new physical hardware and software interaction model shifts largely causes little difficulty with changing for more ease of use, the counter to this with software with a lot of human need for grasping mental models. It is particularly difficult when structuring mental models and organization structure before using software is something required.
There have been some good discounts on Tinderbox across podcasts I listen to or websites around Mac productivity I read, so I nabbed a copy. I have had long discussion around Tinderbox for over a decade and it has been on my want list for large writing and research projects. I have had quite a few friends who have been long time users (longer than I have been a DevonThink user), but I don’t seem to have one in my current circle of colleagues (I you are one and would love to chat, please reach out).
I have a few projects that I think would make great sense to put into Tinderbox, but not really grokking the structure and mental model and flows - particularly around what I wish I would know when I have a lot of content in it. It is feeling a lot like trying to read Japanese and not having learned the characters. I also wish I had kept better notes a few years back when I was deeply sold on a need for Tinderbox, but didn’t capture a detailed why and how I thought it would work into workflow.
Some Tools are Nearly There as a Continual State
I have some software and services that I use a fair amount with hope that they will get much much better with a few relatively small things. Evernote is nearly always in this category. Evernote is a good product, but never gets beyond just good. The search always falls apart at scale (it was around 2,000 objects and had about doubled that scaling threshold pain point) and I can’t sort out how to script things easily or remotely drop content into the correct notebook from email or other easy entry model. There are a lot of things I wish Evernote would become with a few minor tweaks to support a scalable solid no (or very few faults tool), but it never quite takes those steps.
Their business tool offering is good for a few use cases, which are basic, but getting some smart and intelligence uses with better search (search always seems to be a pain point and something that DevonThink has nailed for 10 years) would go a really long way. Evernote’s Context is getting closer, but is lacking up front fuzzy, synonym, and narrowing search with options (either the “did you mean” or narrowing / disambiguation hints / helps).
We will get there some day, but I just wish the quick adoption changes with simple hardware interaction design and OS changes would become as normal as quickly with new other knowledge and information tools for personal use (always better than) or business.
Changing Hosts and Server Locations
I’ve been in the midst of thinking through a web host / server move for vanderwal.net for a while. I started running a personal site in 1995 and was running it under vanderwal.net since 1997. During this time it has gone through six of 7 different hosts. The blog has been on three different hosts and on the same host since January 2006.
I’ve been wanting better email hosting, I want SSH access back, more current updates to: OS; scripting for PHP, Ruby, and Python; MySQL; and other smaller elements. A lot has changed in the last two to three years in web and server hosting.
The current shift is the 4th generation that started with simple web page hosting with limited scripting options, but often had some SSH and command line access to run cron jobs. The second was usually had a few scripting options and database to run light CMS or other dynamic pages, but the hosting didn’t give you access to anything below the web directory (problematic when trying to set your credentials for login out of the web directory, running more than one version of a site (dev, production, etc.), and essential includes that for security are best left out of the web directory). The second generation we often lost SSH and command line as those coming in lacked skills to work at the command line and could cripple a server with ease with a minor accident. The third has been more robust hosting with proper web directory set up and access to sub directories, having multiple scripting resources, having SSH and command line back (usually after proven competence), having control of setting up your own databases at will, setting up your own subdomains at will, and more. The third generation was often still hosting many sites on one server and a run away script or site getting hammered with traffic impacted the whole server. These hosts also often didn’t have the RAM to run current generations of tools (such as Drupal which can be a resource hog if not using command line tools like drush that thankfully made Drupal easier to configure in tight constraints from 2006 forward).
Today’s Options
Today we have a fourth generation of web host that replicates upgraded services like your own private server or virtual private server, but at lighter web hosting prices. I’ve been watching Digital Ocean for a few months and a couple months back I figured for $5 per month it was worth giving it a shot for some experiments and quick modeling of ideas. Digital Ocean starts with 512 MB or RAM, 20GB of SSD space (yes, your read that right, SSD hard drive), and 1TB of transfer. The setup is essentially a virtual private server, which makes experimentation easier and safer (if you mess up you only kill your own work not the work of others - to fix it wipe and rebuild quickly if it is that bad). Digital Ocean also lets you setup your server as you wish in about a minute of creation time with OS, scripting, and database options there for your choosing.
In recently Marco Arment has written up the lay of the land for hosting options from his perspective, which is a great overview. I’ve also been following Phil Gyford’s change of web hosting and like Phil I am dealing with a few domains and projects. I began looking at WebFaction and am liking what is there too. WebFaction adds in email into the equation and 100GB of storage on RAID 10 storage. Like Digital Ocean it has full shell scripting and a wide array of tools to select from to add to your server. This likely would be a good replacement for my core web existence here at vanderwal.net and its related services. WebFaction provides some good management interfaces and smoothing some of the rough edges.
There are two big considerations in all of this: 1) Email; 2) Server location.
Email is a huge pain point for me. It should be relatively bullet proof (as it was years ago). To get bullet proof email the options boil down to going to a dedicated mail service like exchange or something like FastMail, a hosted Exchange server, or Google Apps. Having to pester the mail host to kick a server isn’t really acceptable and that has been a big reason I am considering moving my hosting. Also sitting on servers that get their IP address in blocks of blacklisted email servers (or potentially blacklisted) makes things really painful as well. I have ruled out Exchange as an option due to cost, many open scripts I rely on don’t play well with Exchange, and the price related to having someone maintain it.
Google Apps is an option, but my needs for all the other pieces that Google Apps offers aren’t requirements. I am looking at about 10 email addresses with one massive account in that set along with 2 or 3 other domains with one or two email accounts that are left open to catch the stray emails that drift in to those (often highly important). The cost of Google for this adds up quickly, even with using of aliases. I think having one of my light traffic domains on Google Apps would be good, the price of that and access to Google Apps to have access to for experimentation (Google Apps always arise in business conversations as a reference).
FastMail pricing is yearly and I know a lot of people who have been using it for years and rave about it. Having my one heavy traffic email there, as well as tucking the smaller accounts with lower traffic hosted there would be a great setup. Keeping email separate from hosting give uptime as well. FastMail is also testing calendar hosting with CalDAV, which is really interesting as well (I ran a CalDAV server for a while and it was really helpful and rather easy to manage, but like all things calendar it comes with goofy headaches, often related timezone and that bloody day light savings time, that I prefer others to deal with).
Last option is bundled email with web hosting. This has long been my experience. This is mostly a good solution, but rarely great. Dealing with many domains and multitudes of accounts email bundled with web hosting is a decent option. Mail hosting is rarely a deep strength of a web hosting company and often it is these providers that you have to pester to kick the mail server to get your mail flowing again (not only my experience, but darned near everybody I know has this problem and it should never work this way). I am wondering with the benefits of relatively inexpensive mail hosting bundled into web hosting is worth the pain.
I am likely to split my mail hosting across different solutions (the multiple web hosts and email hosts would still be less than my relatively low all in one web hosting I currently have).
Server Location
I have had web hosting in the US, UK, and now Australia and at a high level, I really don’t care where the the servers are located as the internet is mostly fast and self healing, so location and performance is a negligible distance for me (working with live shell scripting to a point that is nearly at the opposite side of the globe is rather mind blowing in how instantaneous this internet is).
My considerations related to where in the globe the servers are hosted comes down to local law (or lack of laws that are enforced). Sites sitting on European hosts require cookie notifications. The pull down / take down laws in countries are rather different. As a person with USA citizenship paperwork and hosting elsewhere, the laws that apply and how get goofy. The revelations of USA spying on its own people and servers has me not so keen to host in the US again, not that I ever have had anything that has come close to running afoul of laws or could ever be misconstrued as something that should draw attention. I have no idea what the laws are in Australia, which has been a bit of a concern for a while, but the host also has had servers in the US as well.
My options seem to be US, Singapore, UK, Netherlands, and Nordic based hosting. Nearly all the hosting options for web, applications, and mail provide options for location (the non-US options have grown like wildfire in the post Edward Snowden era). Location isn’t a deciding point, but it is something I will think through. I chose Australia as the host had great highly recommended hosting that has lived up to that for that generation of hosting options. It didn’t matter where the server was hosted eight years ago as the laws and implications were rather flat. Today the laws and implications are far less flat, so it will require some thinking through.
Non-UNIX Timestamping has Me Stamping in Frustration
In the slow process of updating things here on this site I have nearly finished with the restructuring the HTML (exception is the about page, which everytime I start on it the changes I start to make lead quickly to a bigger redesign).
Taking a break from the last HTML page restructuring I was looking at finally getting to correctly timestamping and listing the post times based on blog posting location. Everything after the 1783rd blog post currently picks up the server time stamp and that server is sitting in Eastern Australia, so everything (other than blog posts from Sydney) are not correctly timestamped. Most things are 14 to 15 hours ahead of when they were posted - yes, posted from the future.
Looking at my MySQL tables I didn’t use a Unix timestamp, but a SQL datetime as the core date stored and then split the date and time into separate varables created with parsing timestamp in PHP. This leaves 3 columns to convert. It is a few scripts to write, but not bad, but just a bit of a pain. Also in this change is setting up time conversions that are built into the post location, but shifts in time for day light savings starts adding pain that I don’t want to introduce. I’ve been considering posting in GMT / UTC and on client side showing the posting time with relative user local time with a little JavaScript.
I would like to do this before a server / host move I’ve been considering. At this point I may set up a move and just keep track of the first post on the new server, then at some point correct the time for the roughly 500 posts while the server was in Eastern Australia.
Brett Terpstra Focusses on His Work Full-time
I have been a fan of Brett Terpstra for some time. I found his site through a few buds who focus on productivity and personal workflows (including scripting). I have followed his Systematic podcast since the first episode and have found it is the one podcast I listen to when my weekly listening dwindles to just one podcast. His nvALT became an app that is always running and where a lot of writing snippets get stored on my Mac (that content I also reach on my iOS devices to edit and extend). His Marked2 app not only is my Markedown viewer, but a rather good writing analysis tool.
Not only all of this but Brett is a tagger and not only tags, belives tagging is helpful for personal filtering and workflow, but has built tools to greater extend tagging in and around Mac and iOS. If you talk folksonomy and pull the third leg of it, person / identity back into just your own perspective and keep the tag and objects in place you have the realm that Brett focusses and pushes farther for our own personal benefit.
Brett Steps Out to Focus on His Work
This week I have been incredibly happy to learn that Brett moved out of his daytime job to and his new job is to focus on his products, podcast, writing, and new projects and products. This is great news for all of us. Brett took this step before, but we can help him keep these tools and services flowing by supporting him.
If you have benefitted from Brett’s free products of want to ensure the great services and tools that Bret has created you paid for keep improving go help him out.
HTML5 Demo Watch
Thanks to the Berg Friday Links I found the Suit up or Die Magazine and Cut the Rope HTML5 demo sites.
Both have me thinking this is really close, then I remember one of my favorite periodical apps, Financial Times went HTML5 more than a year ago. FT went HTML5 to better manage the multi-platform development process needed for iOS and the multitude of Android versions. While many have said the development is roughly 1.5x what it would take for just one platform development it does same incredible amount of time building an app across all platforms. Since all the major smart phone platforms have their native browsers built on webkit, there is some smart thinking in that approach.
Personally, my big niggle with the FT app is while it is browser based doesn’t have Instapaper built-in and it moves me out of the app to send a link of an article (often to myself because lacking Instapaper) rather than natively in the app, or exposing browser chrome so that I can do that while still remaining in the app and in reading their content mode. It would be really smart for FT to sort this out and fix these as it would keep me in the site and service reading, which I am sure they would love. If they could treat both of those like they do with Twitter and Facebook sharing out all within the app it would be brilliant.
The Data Journalism Handbook is Available
The Data Journalism Handbook is finally available online and soon as the book Data Journalism Handbook - from Amazon or The Data Journalism Handbook - from O’Reilly, which is quite exciting. Why you ask?
In the October of 2010 the Guardian in the UK posted a Data Journalism How To Guide that was fantastic. This was a great resource not only for data journalists, but for anybody who has interest in finding, gathering, assessing, and doing something with the data that is shared found in the world around us. These skill are not the sort of thing that many of us grew up with nor learned in school, nor are taught in most schools today (that is another giant problem). This tutorial taught me a few things that have been of great benefit and filled in gaps I had in my tool bag that was still mostly rusty and built using the tool set I picked up in the mid-90s in grad school in public policy analysis.
In the Fall of 2011 at MozFest in London many data journalist and others of like mind got together to share their knowledge. Out of this gathering was the realization and starting point for the handbook. Journalists are not typically those who have the deep data skills, but if they can learn (not a huge mound to climb) and have it made sensible and relatively easy in bite sized chunk the journalists will be better off.
All of us can benefit from this book in our own hands. Getting to the basics of how gather and think through data and the questions around it, all the way through how to graphically display that data is incredibly beneficial. I know many people who have contributed to this Handbook and think the world of their contributions. Skimming through the version that is one the web I can quickly see this is going to be an essential reference for all, not just journalists, nor bloggers, but for everybody. This could and likely should be the book used in classes in high schools and university information essentials taught first semester first year.
Traits of Blogs with Highly Valued Content for Me
I was going through my inbound feeds of blogs, news, and articles and catching up on the week. In doing so I open things that are of potential interest in an external browser (as mentioned before in As if Had Read) and realized most have some common traits. Most don't have Twitter feed (most Twitter feeds run at a vastly different information velocity and with very different content areas that distract from the content at hand). As well, many do not have comments on them any more or have moderated comments using built-in commenting service/tool (very rarely is Disqus used).
Strong Content is the Draw
The thing in common is all are focused on the that blog post's content. The content and the focus on the idea at hand is the strength of the attraction.
Some of the blogs are back to their old ways of posting short ideas and things that flow through their lives the want to hold on to, but as also comfortable enough to share out for other's with similar interest.
Ancillary Content Can Easily Distract Attention and Value
Sorting out what the focus of a blog (personal or professional) is essential. The focus is the content and the main pieces on the page. It is good to help keep the focus there without any swirling tag cloud (these seem to be the brunt of the fun poking sticks at conferences these days as they add no value and are completely and utterly unusable, so much so those with the mike continually question what understanding somebody has to add them to their page or site) or any other moving updating object. When talking with readers most say they do not notice these objects, just like web ads have taught us to ignore their blinking and flashing and twirling. As is often said personal sites begin to look like entries in a NASCAR race, where the most anticipated outcomes are the wrecks.
I have seen many attempts at personal homepages and personal aggregation pages, which are of big interest to me (for personal archiving, searching, and review), which are a better place for pulling together the Twitter feed, Flickr, Instagram, Tumblr, etc. Aggregation of this content in a feed option is good too, but keeping the blog page content to a main focus on content is good for the reader and attention on the written word.
Yes, over on the right I have my social bookmarked links. It has been my intention to pull recent items with tags related to content tags, but that has yet to happen.
Closing Delicious? Lessons to be Learned
There was a kerfuffle a couple weeks back around Delicious when the social bookmarking service Delicious was marked for end of life by Yahoo, which caused a rather large number I know to go rather nuts. Yahoo, has made the claim that they are not shutting the service down, which only seems like a stall tactic, but perhaps they may actually sell it (many accounts from former Yahoo and Delicious teams have pointed out the difficulties in that, as it was ported to Yahoos own services and with their own peculiarities).
Redundancy
Never the less, this brings-up an important point: Redundancy. One lesson I learned many years ago related to the web (heck, related to any thing digital) is it will fail at some point. Cloud based services are not immune and the network connection to those services is often even more problematic. But, one of the tenants of the Personal InfoCloud is it is where you keep your information across trusted services and devices so you have continual and easy access to that information. Part of ensuring that continual access is ensuring redundancy and backing up. Optimally the redundancy or back-up is a usable service that permits ease of continuing use if one resource is not reachable (those sunny days where there's not a cloud to be seen). Performing regular back-ups of your blog posts and other places you post information is valuable. Another option is a central aggregation point (these are long dreamt of and yet to be really implemented well, this is a long brewing interest with many potential resources and conversations).
With regard to Delicious Ive used redundant services and manually or automatically fed them. I was doing this with Ma.gnol.ia as it was (in part) my redundant social bookmarking service, but I also really liked a lot of its features and functionality (there were great social interaction design elements that were deployed there that were quite brilliant and made the service a real gem). I also used Diigo for a short while, but too many things there drove me crazy and continually broke. A few months back I started using Pinboard, as the private reincarnation of Ma.gnol.ia shut down. I have also used ZooTool, which has more of a visual design community (the community that self-aggregates to a service is an important characteristic to take into account after the viability of the service).
Pinboard has been a real gem as it uses the commonly implemented Delicious API (version 1) as its core API, which means most tools and services built on top of Delicious can be relatively easily ported over with just a change to the URL for source. This was similar for Ma.gnol.ia and other services. But, Pinboard also will continually pull in Delicious postings, so works very well for redundancy sake.
There are some things I quite like about Pinboard (some things I dont and will get to them) such as the easy integration from Instapaper (anything you star in Instapaper gets sucked into your Pinboard). Pinboard has a rather good mobile web interface (something I loved about Ma.gnol.ia too). Pinboard was started by co-founders of Delicious and so has solid depth of understanding. Pinboard is also a pay service (based on an incremental one time fee and full archive of pages bookmarked (saves a copy of pages), which is great for its longevity as it has some sort of business model (I dont have faith in the underpants - something - profit model) and it works brilliantly for keeping out spammer (another pain point for me with Diigo).
My biggest nit with Pinboard is the space delimited tag terms, which means multi-word tag terms (San Francisco, recent discovery, etc.) are not possible (use of non-alphabetic word delimiters (like underscores, hyphens, and dots) are a really problematic for clarity, easy aggregation with out scripting to disambiguate and assemble relevant related terms, and lack of mainstream user understanding). The lack of easily seeing who is following my shared items, so to find others to potentially follow is something from Delicious I miss.
For now I am still feeding Delicious as my primary source, which is naturally pulled into Pinboard with no extra effort (as it should be with many things), but I'm already looking for a redundancy for Pinboard given the questionable state of Delicious.
The Value of Delicious
Another thing that surfaced with the Delicious end of life (non-official) announcement from Yahoo was the incredible value it has across the web. Not only do people use it and deeply rely on it for storing, contextualizing links/bookmarks with tags and annotations, refinding their own aggregation, and sharing this out easily for others, but use Delicious in a wide variety of different ways. People use Delicious to surface relevant information of interest related to their affinities or work needs, as it is easy to get a feed for not only a person, a tag, but also a person and tag pairing. The immediate responses that sounded serious alarm with news of Delicious demise were those that had built valuable services on top of Delicious. There were many stories about well known publications and services not only programmatically aggregating potentially relevant and tangential information for research in ad hoc and relatively real time, but also sharing out of links for others. Some use Delicious to easily build related information resources for their web publications and offerings. One example is emoted by Marshall Kirkpatrick of ReadWriteWeb wonderfully describing their reliance on Delicious
It was clear very quickly that Yahoo is sitting on a real backbone of many things on the web, not the toy product some in Yahoo management seemed to think it was. The value of Delicious to Yahoo seemingly diminished greatly after they themselves were no longer in the search marketplace. Silently confirmed hunches that Delicious was used as fodder to greatly influence search algorithms for highly potential synonyms and related web content that is stored by explicit interest (a much higher value than inferred interest) made Delicious a quite valued property while it ran its own search property.
For ease of finding me (should you wish) on Pinboard I am http://pinboard.in/u:vanderwal
----
Good relevant posts from others:
Nokia to Nip Its Ecosystem?
First off, I admit it I like Nokia and their phones (it may be a bit more than like, actually). But, today's news regarding Nokia further refines development strategy to unify environments for Symbian and MeeGo is troubling, really troubling. Nokia is stating they are moving toward more of an app platform than software. It is a slight nuance in terms, but the app route is building light applications on a platform and not having access to underlying functionality, while software gets to dig deeper and put hooks deeper in the foundations to do what it needs. Simon Judge frames it well in his The End of Symbian for 3rd Party Development.
Killing A Valued Part of the Ecosystem
My love for Nokia is one part of great phone (voice quality is normally great, solidly built, etc.) and the other part is the software third party developers make. Nokia has had a wonderfully open platform for developers to make great software and do inventive things. Many of the cool new things iPhone developers did were done years prior for Nokia phones because it was open and hackable. For a while there was a python kit you could load to hack data and internal phone data, so to build service you wanted. This is nice and good, but my love runs deeper.
When my last Nokia (E61i) died after a few years, its replacement was a Nokia E72. I could have gone to iPhone (I find too many things that really bug me about iPhone to do that and it is still behind functionality I really like in the Nokia). But, the big thing that had me hooked on Nokia were two pieces of 3rd party software. An email application called ProfiMail and a Twitter client called Gravity. Both of these pieces of software are hands down my favorites on any mobile platform (BTW, I loathe the dumbed down Apple mail on iPhone/iPod Touch). But, I also get to use my favorite mobile browser Opera Mobile (in most cases I prefer Opera over Safari on iPhone platform as well). This platform and ecosystem, created the perfect fit for my needs.
Nearly every Nokia user I know (they are hard to find in the US, but most I know are in Europe) all have the same story. It is their favorite 3rd party applications that keep them coming back. Nearly everybody I know loves Gravity and hasn't found another Twitter client they would switch to on any other mobile platform. The Nokia offerings for email and browser are good, but the option to use that best meets your needs is brilliant and always has been, just as the unlocked phone choice rather than a carrier's mangled and crippled offering. If Nokia pulls my ability to choose, then I may choose a phone that doesn't.
Understanding Ecosystems is Important
Many people have trashed Nokia for not having a strong App Store like Apple does for iPhone. Every time I hear this I realize not only do people not understand the smartphone market that has existed for eight years or more prior to iPhone entering the market, but they do not grasp ecosystems. Apple did a smart thing with the App Store for iPhone and it solved a large problem, quality of applications and secondarily created a central place customers could find everything (this really no longer works well as the store doesn't work well at all with the scale it has reached).
While Apple's ecosystem works well, most other mobile platforms had a more distributed ecosystem, where 3rd party developers could build the applications and software, sell it directly from their site or put it in one or many of the mobile application/software stores, like Handango. This ecosystem is distributed hoards of people have been using it and the many applications offered up. When Nokia opened Ovi, which includes an app store with many offerings, many complained it didn't grow and have the mass of applications Apple did. Many applications that are popular for Nokia still are not in Ovi, because a prior ecosystem existed and still exists. That prior ecosystem is central what has made Nokia a solid option.
Most US mobile pundits only started paying attention to mobile when the iPhone arrived. The US has been very very late to the mobile game as a whole and equally good, if not better options for how things are done beyond Apple exist and have existed. I am really hoping this is not the end of one of those much better options (at least for me and many I know).
Social Design for the Enterprise Workshop in Washington, DC Area
I am finally bringing workshop to my home base, the Washington, DC area. I am putting on a my Social Design for the Enterprise half-day workshop on the afternoon of July 17th at Viget Labs (register from this prior link).
Yes, it is a Friday in the Summer in Washington, DC area. This is the filter to sort out who really wants to improve what they offer and how successful they want their products and solutions to be.
Past Attendees have Said...
A few hours and a few hundred dollar saved us tens of thousands, if not well into six figures dollars of value through improving our understanding (Global insurance company intranet director)
From an in-house workshop
We are only an hour in, can we stop? We need to get many more people here to hear this as we have been on the wrong path as an organization (National consumer service provider)
Can you let us know when you give this again as we need our [big consulting firm] here, they need to hear that this is the path and focus we need (Fortune 100 company senior manager for collaboration platforms)
In the last 15 minutes what you walked us through helped us understand a problem we have had for 2 years and a provided manner to think about it in a way we can finally move forward and solve it (CEO social tool product company)
Is the Workshop Only for Designers?
No, the workshop is aimed at a broad audience. The focus of the workshop gets beyond the tools features and functionality to provide understanding of the other elements that make a giant difference in adoption, use, and value derived by people using and the system owners.
The workshop is for user experience designers (information architects, interaction designers, social interaction designers, etc.), developers, product managers, buyers, implementers, and those with social tools running already running.
Not Only for Enterprise
This workshop with address problems for designing social tools for much better adoption in the enterprise (in-house use in business, government, & non-profit), but web facing social tools.
The Workshop will Address
Designing for social comfort requires understanding how people interact in a non-mediated environment and what realities that we know from that understanding must we include in our design and development for use and adoption of our digital social tools if we want optimal adoption and use.
- Tools do not need to be constrained by accepting the 1-9-90 myth.
- Understanding the social build order and how to use that to identify gaps that need design solutions
- Social comfort as a key component
- Matrix of Perception to better understanding who the use types are and how deeply the use the tool so to build to their needs and delivering much greater value for them, which leads to improved use and adoption
- Using the for elements for enterprise social tool success (as well as web facing) to better understand where and how to focus understanding gaps and needs for improvement.
- Ways user experience design can be implemented to increase adoption, use, and value
- How social design needs are different from Web 2.0 and what Web 2.0 could improve with this understanding
More info...
For more information and registration to to Viget Lab's Social Design for the Enterprise page.
I look forward to seeing you there.
![Reblog this post [with Zemanta]](http://img.zemanta.com/reblog_e.png?x-idÃ67bb8b-4652-46bc-bc0d-996c1a2d5205)
Catching Up On Personal InfoCloud Blog Posts
Things here are a little quiet as I have been in writing mode as well as pitching new work. I have been blogging work related items over at Personal InfoCloud, but I am likely only going to be posting summaries of those pieces here from now on, rather than the full posts. I am doing this to concentrate work related posts, particularly on a platform that has commenting available. I am still running my own blogging tool here at vanderwal.net I wrote in 2001 and turned off the comments in 2006 after growing tired of dealing comment spam.
The following are recently posted over at Personal InfoCloud
SharePoint 2007: Gateway Drug to Enterprise Social Tools
SharePoint 2007: Gateway Drug to Enterprise Social Tools focusses on the myriad of discussions I have had with clients of mine, potential clients, and others from organizations sharing their views and frustrations with Microsoft SharePoint as a means to bring solid social software into the workplace. This post has been brewing for about two years and is now finally posted.
Optimizing Tagging UI for People & Search
Optimizing Tagging UI for People and Search focuses on the lessons learned and usability research myself and others have done on the various input interfaces for tagging, particularly tagging with using multi-term tags (tags with more than one word). The popular tools have inhibited adoption of tagging with poor tagging interaction design and poor patterns for humans entering tags that make sense to themselves as humans.
LinkedIn: Social Interaction Design Lessons Learned (not to follow)
I have a two part post on LinkedIn's social interaction design. LinkedIn: Social Interaction Design Lessons Learned (not to follow) - 1 of 2 looks at what LinkedIn has done well in the past and had built on top. Many people have expressed the new social interactions on LinkedIn have decreased the value of the service for them.
The second part, LinkedIn: Social Interaction Design Lessons Learned (not to follow) - 2 of 2 looks at the social interaction that has been added to LinkedIn in the last 18 months or so and what lessons have we as users of the service who pay attention to social interaction design have learned. This piece also list ways forward from what is in place currently.
Optimizing Tagging UI for People & Search
Overview/Intro
One of my areas of focus is around social tools in the workplace (enterprise 2.0) is social bookmarking. Sadly, is does not have the reach it should as it and wiki (most enterprise focused wikis have collective voice pages (blogs) included now & enterprise blog tools have collaborative document pages (wikis). I focus a lot of my attention these days on what happens inside the organizations firewall, as that is where their is incredible untapped potential for these tools to make a huge difference.
One of the things I see on a regular basis is tagging interfaces on a wide variety of social tools, not just in social bookmarking. This is good, but also problematic as it leads to a need for a central tagging repository (more on this in a later piece). It is good as emergent and connective tag terms can be used to link items across tools and services, but that requires consistency and identity (identity is a must for tagging on any platform and it is left out of many tagging instances. This greatly decreases the value of tagging - this is also for another piece). There are differences across tools and services, which leads to problems of use and adoption within tools is tagging user interface (UI).
Multi-term Tag Intro
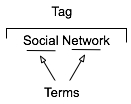 The multi-term tag is one of the more helpful elements in tagging as it provides the capability to use related terms. These multi-term tags provide depth to understanding when keeping the related tag terms together. But the interfaces for doing this are more complex and confusing than they should be for human, as well as machine consumption.
The multi-term tag is one of the more helpful elements in tagging as it provides the capability to use related terms. These multi-term tags provide depth to understanding when keeping the related tag terms together. But the interfaces for doing this are more complex and confusing than they should be for human, as well as machine consumption.
In the instance illustrated to the tag is comprised or two related terms: social and network. When the tool references the tag, it is looking at both parts as a tag set, which has a distinct meaning. The individual terms can be easily used for searches seeking either of those terms, but knowing the composition of the set, it is relatively easy for the service to offer up "social network" when a person seeks just social or network in a search query.
One common hindrance with social bookmarking adoption is those familiar with it and fans of it for enterprise use point to Delicious, which has a couple huge drawbacks. The compound multi-term tag or disconnected multi-term tags is a deep drawback for most regular potential users (the second is lack of privacy for shared group items). Delicious breaks a basic construct in user focussed design: Tools should embrace human methods of interaction and not humans embracing tech constraints. Delicious is quite popular with those of us malleable in our approach to adopt a technology where we adapt our approach, but that percentage of potential people using the tools is quite thin as a percentage of the population.. Testing this concept takes very little time to prove.
So, what are the options? Glad you asked. But, first a quick additional excursion into why this matters.
Conceptual Models Missing in Social Tool Adoption
One common hinderance for social tool adoption is most people intended to use the tools are missing the conceptual model for what these tools do, the value they offer, and how to personally benefit from these values. There are even change costs involved in moving from a tool that may not work for someone to something that has potential for drastically improved value. The "what it does", "what value it has", and "what situations" are high enough hurdles to cross, but they can be done with some ease by people who have deep knowledge of how to bridge these conceptual model gaps.
What the tools must not do is increase hurdles for adoption by introducing foreign conceptual models into the understanding process. The Delicious model of multi-term tagging adds a very large conceptual barrier for many & it become problematic for even considering adoption. Optimally, Delicious should not be used alone as a means to introduce social bookmarking or tagging.
We must remove the barriers to entry to these powerful offerings as much as we can as designers and developers. We know the value, we know the future, but we need to extend this. It must be done now, as later is too late and these tools will be written off as just as complex and cumbersome as their predecessors.
If you are a buyer of these tools and services, this is you guideline for the minimum of what you should accept. There is much you should not accept. On this front, you need to push back. It is your money you are spending on the products, implementation, and people helping encourage adoption. Not pushing back on what is not acceptable will greatly hinder adoption and increase the costs for more people to ease the change and adoption processes. Both of these costs should not be acceptable to you.
Multi-term Tag UI Options
Compound Terms
I am starting with what we know to be problematic for broad adoption for input. But, compound terms also create problems for search as well as click retrieval. There are two UI interaction patterns that happen with compound multi-term tags. The first is the terms are mashed together as a compound single word, as shown in this example from Delicious.
The problem here is the mashing the string of terms "architecture is politics" into one compound term "architectureispolitics". Outside of Germanic languages this is problematic and the compound term makes a quick scan of the terms by a person far more difficult. But it also complicates search as the terms need to be broken down to even have LIKE SQL search options work optimally. The biggest problem is for humans, as this is not natural in most language contexts. A look at misunderstood URLs makes the point easier to understand (Top Ten Worst URLs)
The second is an emergent model for compound multi-term tags is using a term delimiter. These delimiters are often underlines ( _ ), dots ( . ), or hyphens ( - ). A multi-term tag such as "enterprise search" becomes "enterprise.search", "enterprise_search" and "enterprise-search".
While these help visually they are less than optimal for reading. But, algorithmically this initially looks to be a simple solution, but it becomes more problematic. Some tools and services try to normalize the terms to identify similar and relevant items, which requires a little bit of work. The terms can be separated at their delimiters and used as properly separated terms, but since the systems are compound term centric more often than not the terms are compressed and have similar problems to the other approach.
Another reason this is problematic is term delimiters can often have semantic relevance for tribal differentiation. This first surface terms when talking to social computing researchers using Delicious a few years ago. They pointed out that social.network, social_network, and social-network had quite different communities using the tags and often did not agree on underlying foundations for what the term meant. The people in the various communities self identified and stuck to their tribes use of the term differentiated by delimiter.
The discovery that these variations were not fungible was an eye opener and quickly had me looking at other similar situations. I found this was not a one-off situation, but one with a fair amount of occurrence. When removing the delimiters between the terms the technologies removed the capability of understanding human variance and tribes. This method also breaks recommendation systems badly as well as hindering the capability of augmenting serendipity.
So how do these tribes identify without these markers? Often they use additional tags to identity. The social computing researchers add "social computing", marketing types add "marketing", etc. The tools then use their filtering by co-occurrence of tags to surface relevant information (yes, the ability to use co-occurrence is another tool essential). This additional tag addition help improve the service on the whole with disambiguation.
Disconnected Multi-term Tags
The use of distinct and disconnected term tags is often the intent for space delimited sites like Delicious, but the emergent approach of mashing terms together out of need surfaced. Delicious did not intend to create mashed terms or delimited terms, Joshua Schachter created a great tool and the community adapted it to their needs. Tagging services are not new, as they have been around for more than two decades already, but how they are built, used, and platforms are quite different now. The common web interface for tagging has been single terms as tags with many tags applied to an object. What made folksonomy different from previous tagging was the inclusion of identity and a collective (not collaborative) voice that intelligent semantics can be applied to.
The downside of disconnected terms in tagging is certainty of relevance between the terms, which leads to ambiguity. This discussion has been going on for more than a decade and builds upon semantic understanding in natural language processing. Did the tagger intend for a relationship between social & network or not. Tags out of the context of natural language constructs provide difficulties without some other construct for sense making around them. Additionally, the computational power needed to parse and pair potential relevant pairings is somethings that becomes prohibitive at scale.
Quoted Multi-term Tags
One of the methods that surfaced early in tagging interfaces was the quoted multi-term tags. This takes becomes #&039;research "social network" blog' so that the terms social network are bound together in the tool as one tag. The biggest problem is still on the human input side of things as this is yet again not a natural language construct. Systematically the downside is these break along single terms with quotes in many of the systems that have employed this method.
What begins with a simple helpful prompt...:
Still often can end up breaking as follows (from SlideShare):
Comma Delimited Tags
Non-space delimiters between tags allows for multi-term tags to exist and with relative ease. Well, that is relative ease for those writing Western European languages that commonly use commas as a string separator. This method allows the system to grasp there are multi-term tags and the humans can input the information in a format that may be natural for them. Using natural language constructs helps provide the ability ease of adoption. It also helps provide a solid base for building a synonym repository in and/or around the tagging tools.
While this is not optimal for all people because of variance in language constructs globally, it is a method that works well for a quasi-homogeneous population of people tagging. This also takes out much of the ambiguity computationally for information retrieval, which lowers computational resources needed for discernment.
Text Box Per Tag
Lastly, the option for input is the text box per tag. This allows for multi-term tags in one text box. Using the tab button on the keyboard after entering a tag the person using this interface will jump down to the next empty text box and have the ability to input a term. I first started seeing this a few years ago in tagging interfaces tools developed in Central Europe and Asia. The Yahoo! Bookmarks 2 UI adopted this in a slightly different implementation than I had seen before, but works much the same (it is shown here).
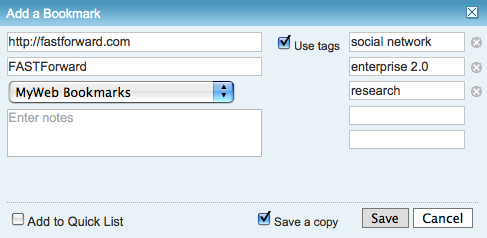
There are many variations of this type of interface surfacing and are having rather good adoption rates with people unfamiliar to tagging. This approach tied to facets has been deployed in Knowledge Plaza by Whatever s/a and works wonderfully.
All of the benefits of comma delimited multi-term tag interfaces apply, but with the added benefit of having this interface work internationally. International usage not only helps build synonym resources but eases language translation as well, which is particularly helpful for capturing international variance on business or emergent terms.
Summary
This content has come from more than four years of research and discussions with people using tools, both inside enterprise and using consumer web tools. As enterprise moves more quickly toward more cost effective tools for capturing and connecting information, they are aware of not only the value of social tools, but tools that get out the way and allow humans to capture, share, and interact in a manner that is as natural as possible with the tools getting smart, not humans having to adopt technology patterns.
This is a syndicated version of the same post at Optimizing Tagging UI for People & Search :: Personal InfoCloud that has moderated comments available.
Stewart Mader is Now Solo and One to Watch and Hire
There seems to be many people that are joining the ranks of solo service providers around social tools. Fortunately there are some that are insanely great people taking these steps. Stewart Mader is one of these insanely great people now fully out on his own. Stewart Mader's Wiki Adoption Services are the place to start for not only initial stages of thinking through and planning successful wiki projects, but also for working through the different needs and perspectives that come with the 6 month and one year realizations.
Those of you not familiar with Stewart, he wrote the best book on understanding wikis and adoption, Wikipatterns and is my personal favorite speaker on the subject of wikis. Others may have more broadly known names, but can not come close to touching his breadth nor depth of knowledge on the subject. His understandings of wikis and their intersection with other forms and types of social tools is unsurpassed.
I welcome Stewart to the realm of social tool soloists experts. I look forward to one day working on a project with Stewart.
"Building the social web" Full-day Workshop in Copenhagen on June 30th
Through the wonderful cosponsoring of FatDUX I am going to be putting on a full-day workshop Building the Social Web on June 30th in Copenhagen, Denmark (the event is actually in Osterbro). This is the Monday following Reboot, where I will be presenting.
I am excited about the workshop as it will be including much of my work from the past nine months on setting social foundations for successful services, both on the web and inside organizations on the intranet. The workshop will help those who are considering, planning, or already working on social sites to improve the success of the services by providing frameworks that help evaluating and guiding the social interactions on the services.
Space is limited for this workshop to 15 seats and after its announcement yesterday there are only 10 seats left as of this moment.
Lasting Value of Techmeme?
Tristan Louis has a post looking at Is Techmeme Myopic, which is a good look at the lasting value that Techmeme surfaces. This mirrors my use of Techmeme, which is mostly to have a glance at what is being discussed each day. Techmeme has a very temporal value for me as it is a zeitgeist tool that tracks news and memes as they flow and ebb through the technology news realm of the web.
Personally, I like Techmeme as it aggregates the news and conversations, which makes it really easy to skip the bits I do not care about (this is much of what flows through it), but I can focus on the few things that do resonate with me. I can also see a view of who is providing content and I can select sources of information whose viewpoint I value over perspectives I personally place less respect.
Enterprise 2.0 Boston - After Noah: What to do After the Flood (of Information)
I am looking forward to being at the Enterprise 2.0 Conference in Boston from June 10 to June 12, 2008. I am going to be presenting on June 10, 2008 at 1pm on After Noah: Making Sense of the Flood (of Information). This presentation looks at what to expect with social bookmarking tools inside an organization as they scale and mature. It also looks at how to manage the growth as well as encourage the growth.
Last year at the same Enterprise 2.0 conference I presented on Bottom-up Tagging (the presentation is found at Slideshare, Bottom-up All the Way Down: How Tags Help Businesses Organize, which has had over 8,800 viewing on Slideshare), which was more of a foundation presentation, but many in the audience were already running social bookmarking services in-house or trying them in some manner. This year my presentation is for those with an understanding of what social bookmarking and folksonomy are and are looking for what to expect and how to manage what is happening or will be coming along. I will be covering how to manage heavy growth as well as how to increase adoption so there is heavy usage to manage.
I look forward to seeing you there. Please say hello, if you get a chance.
Enterprise Social Tools: Components for Success
One of the things I continually run across talking with organizations deploying social tools inside their organization is the difficultly getting all the components to mesh. Nearly everybody is having or had a tough time with getting employees and partners to engage with the services, but everybody is finding out it is much more than just the tools that are needed to consider. The tools provide the foundation, but once service types and features are sorted out, it get much tougher. I get frustrated (as do many organizations whom I talk with lately) that social tools and services that make up enterprise 2.0, or whatever people want to call it, are far from the end of the need for getting it right. There is great value in these tools and the cost of the tools is much less than previous generations of enterprise (large organization) offerings.
Social tools require much more than just the tools for their implementation to be successful. Tool selection is tough as no tool is doing everything well and they all are focussing on niche areas. But, as difficult as the tool selection can be, there are three more elements that make up what the a successful deployment of the tools and can be considered part of the tools.
Four Rings of Enterprise Social Tools
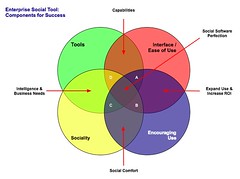 The four elements really have to work together to make for a successful services that people will use and continue to use over time. Yes, I am using a venn diagram for the four rings as it helps point out the overlaps and gaps where the implementations can fall short. The overlaps in the diagram is where the interesting things are happening. A year ago I was running into organizations with self proclaimed success with deployments of social tools (blogs, wikis, social bookmarking, forums, etc.), but as the desire for more than a simple set of blogs (or whichever tool or set of tools was selected) in-house there is a desire for greater use beyond some internal early adopters. This requires paying close attention to the four rings.
The four elements really have to work together to make for a successful services that people will use and continue to use over time. Yes, I am using a venn diagram for the four rings as it helps point out the overlaps and gaps where the implementations can fall short. The overlaps in the diagram is where the interesting things are happening. A year ago I was running into organizations with self proclaimed success with deployments of social tools (blogs, wikis, social bookmarking, forums, etc.), but as the desire for more than a simple set of blogs (or whichever tool or set of tools was selected) in-house there is a desire for greater use beyond some internal early adopters. This requires paying close attention to the four rings.
Tools
The first ring is rather obvious, it is the tools. The tools come down to functionality and features that are offered, how they are run (OS, rack mount, other software needed, skills needed to keep them running, etc.), how the tools are integrated into the organization (authentication, back-up, etc.), external data services, and the rest of the the usual IT department checklist. The tools get a lot of attention from many analysts and tech evangelists. There is an incredible amount of attention on widgets, feeds, APIs, and elements for user generated contribution. But, the tools do not get you all of the way to a successful implementation. The tools are not a mix and match proposition.
Interface & Ease of Use
One thing that the social software tools from the consumer web have brought is ease of use and simple to understand interfaces. The tools basically get out of the way and bring in more advanced features and functionality as needed. The interface also needs to conform to expectations and understandings inside an organization to handle the flow of interaction. What works for one organization may be difficult for another organization, largely due to the tools and training, and exposure to services outside their organization. Many traditional enterprise tools have been trying to improve the usability and ease of use for their tools over the last 4 to 5 years or so, but those efforts still require massive training and large binders that walk people through the tools. If the people using the tools (not administering the tools need massive amounts of training or large binders for social software the wrong tool has been purchased).
Sociality
Sociality is the area where people manage their sharing of information and their connections to others. Many people make the assumption that social tools focus on everything being shared with everybody, but that is not the reality in organizations. Most organizations have tight boundaries on who can share what with whom, but most of those boundaries get in the way. One of the things I do to help organizations is help them realize what really needs to be private and not shared is often much less than what they regulate. Most people are not really comfortable sharing information with people they do not know, so having comfortable spaces for people to share things is important, but these spaces need to have permeable walls that encourage sharing and opening up when people are sure they are correct with their findings.
Sociality also includes the selective groups people belong to in organizations for project work, research, support, etc. that are normal inside organizations to optimize efficiency. But, where things get really difficult is when groups are working on similar tasks that will benefit from horizontal connections and sharing of information. This horizontal sharing (as well as diagonal sharing) is where the real power of social tools come into play as the vertical channels of traditional organization structures largely serve to make organizations inefficient and lacking intelligence. The real challenge for the tools is the capability to surface the information of relevance from selective groups to other selective groups (or share information more easily out) along the way. Most tools are not to this point yet, largely because customers have not been asking for this (it is a need that comes from use over time) and it can be a difficult problem to solve.
One prime ingredient for social tool use by people is providing a focus on the people using the tools and their needs for managing the information they share and the information from others that flow through the tool. Far too often the tools focus on the value the user generated content has on the system and information, which lacks the focus of why people use the tools over time. People use tools that provide value to them. The personal sociality elements of whom are they following and sharing things with, managing all contributions and activities they personally made in a tool, ease of tracking information they have interest in, and making modifications are all valuable elements for the tools to incorporate. The social tools are not in place just to serve the organization, they must also serve the people using the tools if adoption and long term use important.
Encouraging Use
Encouraging use and engagement with the tools is an area that all organizations find they have a need for at some point and time. Use of these tools and engagement by people in an organization often does not happen easily. Why? Normally, most of the people in the organization do not have a conceptual framework for what the tools do and the value the individuals will derive. The value they people using the tools will derive needs to be brought to the forefront. People also usually need to have it explained that the tools are as simple as they seem. People also need to be reassured that their voice matters and they are encouraged to share what they know (problems, solutions, and observations).
While the egregious actions that happen out on the open web are very rare inside an organization (transparency of who a person is keeps this from happening) there is a need for a community manager and social tool leader. This role highlights how the tools can be used. They are there to help people find value in the tools and provide comfort around understanding how the information is used and how sharing with others is beneficial. Encouraging use takes understanding the tools, interface, sociality, and the organization with its traditions and ways of working.
The Overlaps
The overlaps in the graphic are where things really start to surface with the value and the need for a holistic view. Where two rings over lap the value is easy to see, but where three rings overlap the missing element or element that is deficient is easier to understand its value.
Tools and Interface
Traditional enterprise offerings have focussed on the tools and interface through usability and personalization. But the tools have always been cumbersome and the interfaces are not easy to use. The combination of the tools and interface are the core capabilities that traditionally get considered. The interface is often quite flexible for modification to meet an organizations needs and desires, but the capabilities for the interface need to be there to be flexible. The interface design and interaction needs people who have depth in understanding the broad social and information needs the new tools require, which is going to be different than the consumer web offerings (many of them are not well thought through and do not warrant copying).
Tools and Sociality
Intelligence and business needs are what surface out of the tools capabilities and sociality. Having proper sociality that provides personal tools for managing information flows and sharing with groups as well as everybody as it makes sense to an individual is important. Opening up the sharing as early as possible will help an organization get smarter about itself and within itself. Sociality also include personal use and information management, which far few tools consider. This overlap of tools and sociality is where many tools are needing improvement today.
Interface and Encouraging Use
Good interfaces with easy interaction and general ease of use as well as support for encouraging use are where expanding use of the tools takes place, which in turn improves the return on investment. The ease of use and simple interfaces on combined with guidance that provides conceptual understanding of what these tools do as well as providing understanding that eases fears around using the tools (often people are fearful that what they share will be used against them or their job will go away because they shared what they know, rather than they become more valuable to an organization by sharing as they exhibit expertise). Many people are also unsure of tools that are not overly cumbersome and that get out of the way of putting information in to the tools. This needs explanation and encouragement, which is different than in-depth training sessions.
Sociality and Encouraging Use
The real advantages of social tools come from the combination of getting sociality and encouraging use correct. The sociality component provides the means to interact (or not) as needed. This is provided by the capabilities of the product or products used. This coupled with a person or persons encouraging use that show the value, take away the fears, and provide a common framework for people to think about and use the tools is where social comfort is created. From social comfort people come to rely on the tools and services more as a means to share, connect, and engage with the organization as a whole. The richness of the tools is enabled when these two elements are done well.
The Missing Piece in Overlaps
This section focusses on the graphic and the three-way overlaps (listed by letter: A; B; C; and D). The element missing in the overlap or where that element is deficient is the focus.
Overlap A
This overlap has sociality missing. When the tool, interface, and engagement are solid, but sociality is not done well for an organization there may be strong initial use, but use will often stagnate. This happens because the sharing is not done in a manner that provides comfort or the services are missing a personal management space to hold on to a person's own actions. Tracking one's own actions and the relevant activities of others around the personal actions is essential to engaging socially with the tools, people, and organization. Providing comfortable spaces to work with others is essential. One element of comfort is built from know who the others are whom people are working with, see Elements of Social Software and Selective Sociality and Social Villages (particularly the build order of social software elements) to understand the importance.
Overlap B
This overlap has tools missing, but has sociality, interface, and encouraging use done well. The tools can be deficient as they may not provide needed functionality, features, or may not scale as needed. Often organizations can grow out of a tool as their needs expand or change as people use the tools need more functionality. I have talked with a few organizations that have used tools that provide simple functionality as blogs, wikis, or social bookmarking tools find that as the use of the tools grows the tools do not keep up with the needs. At times the tools have to be heavily modified to provide functionality or additional elements are needed from a different type of tool.
Overlap C
Interface and ease of use is missing, while sociality, tool, and encouraging use are covered well. This is an area where traditional enterprise tools have problems or tools that are built internally often stumble. This scenario often leads to a lot more training or encouraging use. Another downfall is enterprise tools are focussed on having their tools look and interact like consumer social web tools, which often are lacking in solid interaction design and user testing. The use of social tools in-house will often not have broad use of these consumer services so the normal conventions are not understood or are not comfortable. Often the interfaces inside organizations will need to be tested and there many need to be more than one interface and feature set provided for depth of use and match to use perceptions.
Also, what works for one organization, subset of an organization, or reviewer/analyst will not work for others. The understanding of an organization along with user testing and evaluation with a cross section of real people will provide the best understanding of compatibility with interface. Interfaces can also take time to take hold and makes sense. Interfaces that focus on ease of use with more advanced capabilities with in reach, as well as being easily modified for look and interactions that are familiar to an organization can help resolve this.
Overlap D
Encouraging use and providing people to help ease people's engagement is missing in many organizations. This is a task that is often overlooked. The tools, interface, and proper sociality can all be in place, but not having people to help provide a framework to show the value people get from using the tools, easing concerns, giving examples of uses for different roles and needs, and continually showing people success others in an organization have with the social tool offerings is where many organization find they get stuck. The early adopters in an organization may use the tools as will those with some familiarity with the consumer web social services, but that is often a small percentage of an organization.
Summary
All of this is still emergent and early, but these trends and highlights are things I am finding common. The two areas that are toughest to get things right are sociality and encouraging use. Sociality is largely dependent on the tools, finding the limitations in the tools takes a fair amount of testing often to find limitations. Encouraging use is more difficult at the moment as there are relatively few people who understand the tools and the context that organizations bring to the tools, which is quite different from the context of the consumer social web tools. I personally only know of a handful or so of people who really grasp this well enough to be hired. Knowing the "it depends moments" is essential and knowing that use is granular as are the needs of the people in the organization. Often there are more than 10 different use personas if not more that are needed for evaluating tools, interface, sociality, and encouraging use (in some organizations it can be over 20). The tools can be simple, but getting this mix right is not simple, yet.
[Comments are open and moderated at Enterprise Social Tools: Components for Success :: Personal InfoCloud
Getting Info into the Field with Extension
This week I was down in Raleigh, North Carolina to speak at National Extension Technology Conference (NETC) 2008, which is for the people running the web and technology components for what used to be the agricultural extension of state universities, but now includes much more. This was a great conference to connect with people trying to bring education, information, and knowledge services to all communities, including those in rural areas where only have dial-up connectivity to get internet access. The subject matter presented is very familiar to many other conferences I attend and present at, but with a slightly different twist, they focus on ease of use and access to information for everybody and not just the relatively early adopters. The real values of light easy to use interfaces that are clear to understand, well structured, easy to load, and include affordance in the initial design consideration is essential.
I sat in on a few sessions, so to help tie my presentation to the audience, but also listen to interest and problems as they compare to the organizations I normally talk to and work with (mid-size member organizations up to very large global enterprise). I sat in on a MOSS discussion. This discussion about Sharepoint was indiscernible from any other type of organization around getting it to work well, licensing, and really clumsy as well as restrictive sociality. The discussion about the templates for different types of interface (blogs and wikis) were the same as they they do not really do or act like the template names. The group seemed to have less frustration with the wiki template, although admitted it was far less than perfect, it did work to some degree with the blog template was a failure (I normally hear both are less than useful and only resemble the tools in name not use). [This still has me thinking Sharepoint is like the entry drug for social software in organizations, it looks and sounds right and cool, but is lacking the desired kick.]
I also sat down with the project leads and developers of an eXtension wide tool that is really interesting to me. It serves the eXtension community and they are really uncoupling the guts of the web tools to ease greater access to relevant information. This flattening of the structures and new ways of accessing information is already proving beneficial to them, but it also has brought up the potential to improve ease some of the transition for those new to the tools. I was able to provide feedback that should provide a good next step. I am looking forward to see that tool and the feedback in the next three to six months as it has incredible potential to ease information use into the hands that really need it. It will also be a good example for how other organizations can benefit from similar approaches.
Comments are open (with usual moderation) at this post at Getting Info into the Field with Extension :: Personal InfoCloud.
Explaining the Granular Social Network
This post on Granular Social Networks has been years in the making and is a follow-up to one I previously made in January 2005 on Granular Social Networks as a concept I had been presenting and talking about for quite some time at that point. In the past few years it has floated in and out of my presentations, but is quite often mentioned when the problems of much of the current social networking ideology comes up. Most of the social networking tools and services assume we are broadline friends with people we connect to, even when we are just "contacts" or other less than "friend" labels. The interest we have in others (and others in us) is rarely 100 percent and even rarer is that this 100 percent interest and appreciation is equal in both directions (I have yet to run across this in any pairing of people, but I am open to the option that it exists somewhere).
Social Tools Need to Embrace Granularity
What we have is partial likes in others and their interests and offerings. Our social tools have yet to grasp this and the few that do have only taken small steps to get there (I am rather impressed with Jaiku and their granular listening capability for their feed aggregation, which should be the starting point for all feed aggregators). Part of grasping the problem is a lack of quickly understanding the complexity, which leads to deconstructing and getting to two variables: 1) people (their identities online and their personas on various services) and 2) interests. These two elements and their combinations can (hopefully) be seen in the quick annotated video of one of my slides I have been using in presentations and workshops lately.
Showing Granular Social Network
Granular Social Network from Thomas Vander Wal on Vimeo.
The Granular Social Network begins with one person, lets take the self, and the various interest we have. In the example I am using just five elements of interest (work, music, movies, food, and biking). These are interest we have and share information about that we create or find. This sharing may be on one service or across many services and digital environments. The interests are taken as a whole as they make up our interests (most of us have more interests than five and we have various degrees of interest, but I am leaving that out for the sake of simplicity).
Connections with Others
Our digital social lives contain our interests, but as it is social it contains other people who are our contacts (friends is presumptive and gets in the way of understanding). These contacts have and share some interests in common with us. But, rarely do the share all of the same interest, let alone share the same perspective on these interests.
Mapping Interests with Contacts
But, we see when we map the interests across just six contacts that this lack of fully compatible interests makes things a wee bit more complicated than just a simple broadline friend. Even Facebook and their touted social graph does not come close to grasping this granularity as it is still a clumsy tool for sharing, finding, claiming, and capturing this granularity. If we think about trying a new service that we enjoy around music we can not easily group and capture then try to identify the people we are connected to on that new service from a service like Facebook, but using another service focussed on that interest area it could be a little easier.
When we start mapping our own interest back to the interest that other have quickly see that it is even more complicated. We may not have the same reciprocal interest in the same thing or same perception or context as the people we connect to. I illustrate with the first contact in yellow that we have interest in what they share about work or their interest in work, even though they are not stating or sharing that information publicly or even in selective social means. We may e-mail, chat in IM or talk face to face about work and would like to work with them in some manner. We want to follow what they share and share with them in a closer manner and that is what this visual relationship intends to mean. As we move across the connections we see that the reciprocal relationships are not always consistent. We do not always want to listen to all those who are sharing things, with use or the social collective in a service or even across services.
Focus On One Interest
Taking the complexity and noise out of the visualization the focus is placed on just music. We can easily see that there are four of our six contacts that have interest in music and are sharing their interest out. But, for various reasons we only have interests in what two of the four contacts share out. This relationship is not capturing what interest our contacts have in what we are sharing, it only captures what they share out.
Moving Social Connections Forward
Grasping this as a relatively simple representation of Granular Social Networks allows for us to begin to think about the social tools we are building. They need to start accounting for our granular interests. The Facebook groups as well as listserves and other group lists need to grasp the nature of individuals interests and provide the means to explicitly or implicitly start to understand and use these as filter options over time. When we are discussing portable social networks this understanding has be understood and the move toward embracing this understanding taken forward and enabled in the tools we build. The portable social network as well as social graph begin to have a really good value when the who is tied with what and why of interest. We are not there yet and I have rarely seen or heard these elements mentioned in the discussions.
One area of social tools where I see this value beginning to surface in through tagging for individuals to start to state (personally I see this as a private or closed declaration that only the person tagging see with the option of sharing with the person being tagged, or at least have this capability) the reasons for interest. But, when I look at tools like Last.fm I am not seeing this really taking off and I hear people talking about not fully understanding tagging as as it sometimes narrows the interest too narrowly. It is all an area for exploration and growth in understanding, but digital social tools, for them to have more value for following and filtering the flows in more manageable ways need to more in grasping this more granular understanding of social interaction between people in a digital space.
Social Tools for Mergers and Acquisitions
The announcement yesterday of Delta and Northwest airlines merging triggered a couple thoughts. One of the thoughts was sadness as I love the unusually wonderful customer service I get with Northwest, and loathe the now expected poor and often nasty treatment by Delta staff. Northwest does not have all the perks of in seat entertainment, but I will go with great customer service and bags that once in nearly 50 flights did not arrive with me.
But, there is a second thing. It is something that all mergers and large organization changes trigger...
Social Tools Are Great Aids for Change
Stewart Mader brought this to mind again in his post Onboarding: getting your new employees cleared for takeoff, which focusses on using wikis (he works for Atlassian and has been a strong proponent of wikis for years and has a great book on Wiki Patterns) as a means to share and update the information that is needed for transitions and the joining of two organizations.
I really like his write-up and have been pushing the social tools approach for a few years. The wiki is one means of gathering and sharing information. It is a good match with social bookmarking, which allows organizations that are coming together have their people find and tag things in their own context and perspective. This provides finding common objects that exist, but also sharing and learning what things are called from the different perspectives.
Communication Build Common Ground
Communication is a key cornerstone to any organization working with, merging with, or becoming a part of another. Communication needs common ground and social bookmarking that allows for all context and perspectives to be captured is essential to making this a success.
This is something I have presented on and provided advice in the past and really think and have seen that social tools are essentials in these times of transition. It is really rewarding when I see this working as I have been through organization mergers, going public, and major transitions in the days before these tools existed. I can not imaging thinking of transitioning with out these tools and service today. I have talked to many organizations after the fact that wished they had social bookmarking, blogs, and wikis to find and annotate items, provide the means to get messages out efficiently (e-mail is becoming a poor means of sharing valuable information), and working toward common understanding.
One large pain point in mergers and other transitions is the cultural change that brings new terms, new processes, new workflow, and disruption to patterns of understanding that became natural to the people in the organization. The ability to map what something was called and the way it was done to what it is now called and the new processes and flows is essential to success. This is exactly what the social tools provide. Social bookmarking is great for capturing terms, context, and perspectives and providing the ability to refind these new items using prior understanding with low cognitive costs. Blogs help communicate people's understanding as they are going through the process as well as explain the way forward. Wikis help map these individual elements that have been collectively provided and pull them together in one central understanding (while still pointing out to the various individual contributions to hold on to that context) in a collaborative (working together with one common goal) environment.
Increasing Speed and Lowering Cost of Transition
Another attribute of the social tools is the speed and cost at which the information is shared, identified, and aggregated. In the past the large consulting firms and the slow and expensive models for working were have been the common way forward for these times of change. Seeing social tools along with a few smart and nimble experts on solid deployments and social engagement will see similar results in days and a handful of weeks compared to many weeks and months of expensive change management plodding. The key is the people in the organizations know their concerns and needs, while providing them the tools to map their understanding and finding information and objects empowers the individuals while giving them knowledge and the means to share with others. This also helps the individuals grasp that are essential to the success and speed to the change. Most people resent being pushed and prodded into change and new environments, giving them the tools to understand and guide their own change management is incredibly helpful. This decreases the time for transition (for processes and emotionally) while also keeping the costs lower.
[Comments are open and moderated as always in the post at: Social Tools to Efficiently Build Common Ground :: Personal InfoCloud]
YouTube New Interface and Social Interaction Design Santiy Check
YouTube has released a new design for the site and its individual video pages. This gets shared in Google Operating System :: User Inferface Updates at YouTube and TechCrunch :: YouTube Updates Layout, Now with Tabs and Statistics. While the new design looks nice and clean, it has one design bug that is horribly annoying it has mixed interaction design metaphors for its tabs or buttons.
Broken Interaction Design on Buttons or Tabs
 As the image shows the Share, Favorite, Playlists, and Flag buttons or tabs all have similar design treatment, but they do not have the same actions when you click on them. Three of the items (Share, Playlists, and Flag) all act as tabs that open up a larger area below them to provide more options and information. But, the Favorites acts like a button that when clicked it marks the item as a favorite.
As the image shows the Share, Favorite, Playlists, and Flag buttons or tabs all have similar design treatment, but they do not have the same actions when you click on them. Three of the items (Share, Playlists, and Flag) all act as tabs that open up a larger area below them to provide more options and information. But, the Favorites acts like a button that when clicked it marks the item as a favorite.
This is incredibly poor interaction design as all the items should act in the same manner. If the items do not have the same action properties they really should not look the same and be in the same action space. Favorites should be a check box or a binary interface for on and off. That interaction patter more closely matches the Rate section and seems like it should have been there rather than showing a lack of understanding interaction design basics and confusing people using the site/service.
Social Sites Seem to Share a Lack of Interaction Understanding
This should have been a no brainer observation for a design manager or somebody with a design sanity check. YouTube is far from the the only site/service doing this. Nearly all of the services are not grasping the basics or are broadly applying design patterns to all user scenarios when they really do not fit all scenarios and user types (nearly every service I talk to know exactly the use type a person fits into but never takes this into account in optimization of design patterns that match that use need). Facebook really falls into this hole badly and never seems to grasp they are really making a mess of things the more features and functionality they are bringing into their service without accounting for the design needs in the interface.
My seemingly favorite site to nit pick is LinkedIn which I use a lot and has been a favorite, but their social interaction additions and interactive interfaces really need much better sanity checks and testing before they go into production (even into the beta interface). LinkedIn is really trying to move forward and they are moving in the right direction, but they really need better design thinking with their new features and functionality. Their new design is ready to handle some of the new features, but the features need a lot more refining. The new design shows they have a really good grasp that the interface needs to be a flexible foundation to be used as a framework for including new features, which could benefit from treating them as options for personalization. LinkedIn has pulled back many of the social features and seems to be rethinking them and refining them, but they really need some good sanity checks before rolling them out again.
Social Interaction in Enterprise Tools
The befuddled interaction understanding is not germane to commercial or consumer public social web sites, but it also plagues tools aimed at the enterprise. This is not overly surprising as many of the social enterprise (enterprise 2.0) tools and services are copying the public web tools and services to a large degree. This is a good thing, as it puts the focus on ease of use, which has been horribly missing in business focussed tools for far too long. But, the down side for enterprise focussed tools is they are not for the public web they are for business users, who most often do not have familiarity with the conventions on the public web and they have a large cognitive gap in understanding what the tools do and their value. There is less time for playing and testing in most business people's worklife. This means the tools need to get things right up front with clear understanding of the use needs of the people they are building for in business. This seems to be lacking in many tools as there is much copying of poor design that really needs to be tested thoroughly before launching. Business focussed tools are not hitting the same people as are on the web, which will work through poor design and functionality to see what things do. It is also important to consider that there are a wide variety of types of people using these tools with varying needs and varying interaction understandings (this will be another blog post, actually a series of posts that relate to things I have been including in workshops the last six months and presenting the last couple).
[Comments are available and moderated as usual at: YouTube New Interface and Social Interaction Design Santiy Check :: Personal InfoCloud]
Denning and Yaholkovsky on Real Collaboration
The latest edition of the Communications of the ACM (Volume 51, Issue 4 - April 2008) includes an article on Getting to "we", which starts off by pointing out the misuse and mis-understanding of the term collaboration as well as the over use of the practice of collaboration when it is not proper for the need. The authors Peter Denning and Peter Yaholkovsky break down the tools needed for various knowledge needs into four categories: 1) Information sharing; 2) Coordination; 3) Cooperation; and Collaboration. The authors define collaboration as:
Collaboration generally means working together synergistically. If your work requires support and agreement of others before you can take action, you are collaborating.
The article continues on to point out that collaboration is often not the first choice of tools we should reach for, as gathering information, understanding, and working through options is really needed in order to get to the stages of agreement. Their article digs deeply into the resolving "messy problems" through proper collaboration methods. To note, the wiki - the usual darling of collaboration - is included in their "cooperation" examples and not Collaboration. Most of the tools many businesses consider in collaboration tools are in the lowest level, which is "information sharing". But, workflow managment falls into the coordination bucket.
This is one of the better breakdowns of tool sets I have seen. The groupings make a lot of sense and their framing of collaboration to take care of the messiest problems is rather good, but most of the tools and services that are considered to be collaborations tools do not even come close to that description or to the capabilities required.
[Comments are open at Denning and Yaholkovsky on Real Collaboration :: Personal InfoCloud]
Selective Sociality and Social Villages
The web provides wonderful serendipity on many fronts, but in this case it brought together two ideas I have been thinking about, working around, and writing about quite a bit lately. The ideas intersect at the junction of the pattern of building social bonds with people and comfort of know interactions that selective sociality brings.
The piece that struck me regarding building and identifying a common bond with another person came out of Robert Paterson's "Mystery of Attraction" post (it is a real gem). Robert describes his introduction and phases of getting to know and appreciate Luis Suarez (who I am a huge fan of and deeply appreciate the conversations I have with him). What Robert lays out in his introduction (through a common friend on-line) is a following of each other's posts and digital trail that is shared out with others. This builds an understanding of each others reputation in their own minds and the shared interest. Upon this listening to the other and joint following they built a relationship of friendship and mutual appreciation (it is not always mutual) and they began to converse and realized they had a lot more in common.
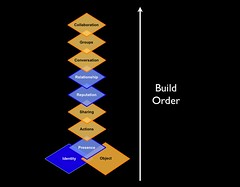 What Robert echos is the Elements in Social Software and its build order. This build order is common in human relationships, but quite often social software leaves out steps or expects conversations, groups, and collaboration to happen with out accounting for the human elements needed to get to this stage. Quite often the interest, ideas, and object (all social objects) are the stimulus for social interaction as they are the hooks that connect us. This is what makes the web so valuable as it brings together those who are near in thought and provides a means to connect, share, and listen to each other. I really like Robert's analogy of the web being like university.
What Robert echos is the Elements in Social Software and its build order. This build order is common in human relationships, but quite often social software leaves out steps or expects conversations, groups, and collaboration to happen with out accounting for the human elements needed to get to this stage. Quite often the interest, ideas, and object (all social objects) are the stimulus for social interaction as they are the hooks that connect us. This is what makes the web so valuable as it brings together those who are near in thought and provides a means to connect, share, and listen to each other. I really like Robert's analogy of the web being like university.
Selective Sociality of Villages
The piece that resonated along similar threads to Robert's post is Susan Mernit's "Twitter & Friend Feed: The Pleasure of Permissions". Susan's post brings to light the value of knowing who you are sharing information with and likes the private or permission-based options that both Twitter and FriendFeed offer. This selective sociality as known Local InfoCloud of people and resources that are trusted and known, which we use as resources. In this case it is not only those with whom we listen to and query, but those with whom we share. This knowing who somebody is (to some degree) adds comfort, which is very much like Robert Patterson and Luis Suarez#039; villages where people know each other and there is a lot of transparency. Having pockets where our social armor is down and we can be free to share and participate in our lives with others we know and are familiar to us is valuable.
I am found these two pieces quite comforting as they reflect much of what I see in the physical community around me as well as the work environments I interact with of clients and collaborators. The one social web service I have kept rather private is Twitter and I really want to know who someone is before I will accept them as a connection. This has given me much freedom to share silly (down right stupid - in a humorous way) observations and statements. This is something I hear from other adults around kids playgrounds and practices of having more select social interactions on line in the services and really wanting to connect with people whom they share interests and most often have known (or followed/listened to) for sometime before formally connecting. Most often these people want to connect with the same people on various services they are trying out, based on recommendation (and often are leaving a service as their friends are no longer there or the service does not meet their needs) of people whom they trust. This is the core of the masses who have access and are not early adopters, but have some comfort with the web and computers and likely make up 80 to 90 percent of web users.
[Comments are open (with moderation as always) on this post at Selective Sociality and Social Villages :: Personal InfoCloud]
Understanding Collective and Collaborative
I have finally blogged about the different between the two terms of collaborative and collective, which has been something bugging me for some time. Comments there are open, but are moderated (as they always have been). Those who have been to any of my workshops in the past year or so will see familiar information. Hopefully, the post will help those discussing and crafting social tools for the general web (or mobile) or large organizations will read and work to grasp the difference. I have had plenty of academics, researchers, and service developers push me to make this public for far too long so to start getting the misunderstanding around the two terms corrected.
6th Internet Identity Workshop Coming Up
The other event that I am finding to be fantastic is also in the Bay Area the week of May 12th is the 6th Internet Identity Workshop. This is the event for people working around identity related issues (any social application or service) that are now the core of nearly all products on the web and intranet. I have found that those who attend this event really grasp the meaning and deep impact of identity along with the needed tools and services around identity. It is really rare that I find somebody talking or writing about identity related issues in a smart manner that has not been part of one of the past IIW events.
As the discussion around the social graph has become hot identity (and the issue of privacy) has come to the forefront even more. Most services are not dealing with identity in an intelligent manner that is recognizable by a huge majority of people who are using these digital services. Much of the mangled discussion around social graph is missing solid understanding from a digital identity perspective and the use and reuse of statements of relationship that do not transcend various services.
Discussions around persona (not the IA persona variety) and identity abound and the need for services that grasp these differences are worked through. The need for better understanding the incredible value the role of identity in tagging services has also been discussed here, which is something many services do not grasp and are doing a dis-service to the people who want to tag items in their own perspective and context to ease their own refinding of the object (Twine really needs a much better understanding of tagging as their automated tagging is incredibly poor and missing many tangents for understanding that need to be applied for full and proper understanding of the objects in their service).
I am really hoping to get to part of the IIW event this time around my workshop in Las Vegas to continue with the great identity conversations from the past IIW events.
Data Sharing Summit Announced
The Bay Area the week of May 12 has a couple great events that many who read this blog should be attending. I will be in Las Vegas (putting on a Enterprise 2.0 Jumpstart workshop with Jevon MacDonald) for part of the week, but should be in the Bay Area for the remainder of the time (at least that is the plan at the moment).
Data Sharing Summit
Following on the success and interest from the event last year is the Data Sharing Summit held April 15th at the Computer History Museum in Mountain View. Data sharing is getting to be the next hot spot that social web services and enterprise tool makers really much deal with as people are not satisfied living in their single walled gardens that inhibit their ability to share, find, hold on to, and refind information, media, and knowledge that is of interest or needed by them. Understanding the limits of the partitioned spaces and embracing more open (particularly securely open) uses of the contributions made by the tools and services participants is vitally important as the participants and system owners are realizing there is rich value to be gained from a much better understanding of these interactions with participants and other services.
We are living in a digital sharing realm that was dreamed up by designers and developers scratching their own itch and in doing so the tools are self contained and not living in a social ecosystem that is based on intelligent interactions. This will likely be the focus of the discussion as people on all sides are working to vastly improve the value of their services and tools and the value that people get from using them with other tools. This is not an event to sell products, but an event for smart people to discuss where things are, where they are going (or went when we were not looking), how to progress with opening up in a manner that all the parties gain value (understanding what and where the value resides is critical), and how we can all move forward.
I will see you there, right?
Remote Presentation and Perception Matrix for Social Tools
This post is also found at: Remote Presentation and Perceptions Matrix for Social Tools :: Personal InfoCloud with moderated comments turned on.]
Today I did something I had never done before (actually a few things) I sat in my office in my home and gave a live web video presentation to a conference elsewhere on the globe. I presented my nearly all new presentation, Keeping Up With Social Tagging to the Expert Workshop in: Social Tagging and Knowledge Organization - Perspectives and Potential that was put on by the Knowledge Media Research Center in Tübingen, Germany.
Remote Presentation Feelings
While the remote video presentation is normal for many people inside their large organizations and I have presented at meetings and conferences where my presentation was provided to other location on live video feed (my recent Ann Arbor trip to present at STIET was HD broadcast to Wayne State in Detroit), this home office to conference presentation was new to me. The presentation and video link used Adobe Connect, which allowed me to see whom I was talking to, manage my slides, text chat, and see myself. This worked quite well, much better than I expected. I did have my full slide presentation in lightroom view set up in Keynote on my external monitor on the side and used Awaken on the side monitor as well to help with timing.
The ability to get feedback and watch the attendees body language and non-verbal responses was insanely helpful. I have given webinars and done phone presentations where I had not visual cues to the audience responses, which I find to be a horrible way to present (I often will expand on subjects or shorten explanations based on non-verbal feedback from the audience). Adobe Connect allowed this non-verbal feedback to be streamed back to me, which completely allows me to adjust the presentation as I normally do.
One thing that was a wee bit difficult was having to change focus (I suppose that comes with use and experience), but I would watch audience feedback while presenting, peek to the side to see where I was with time and slides (to work in the transitions), but would then try to look at the camera to "connect". Watching myself on the video feedback the moments I would try to connect through the camera I would open my eyes wide as if trying to see through my iSight and boy does that come across looking strange on a close range camera. I also (unknown to myself until recently watching a video of another presentation I had done) use a similar facial expression to add emphasis, I am realizing with a camera as close as it is for web presentation also really looks odd. I am sort of used to listening to myself (normally to write out new analogies I use or responses to questions), but watching myself in playback from that close of a range is really uncomfortable.
One thing I really missed in doing this web video presentation was extended interaction with the attendees. I rather enjoy conferences, particularly ones with this focussed a gathering as it makes for great socializing with people passionate about the same subjects I am passionate about. I like comparing note, perceptions, and widely differing views. It helps me grow my knowledge and understandings as well as helps change my perceptions. Live face-to-face conversation and sharing of interests is an incredibly value part of learning, experiencing, and shaping views and it is something I greatly enjoy attending conferences in person. I am not a fan of arriving at a conference just prior to a presentation, giving the presentation, and then leaving. The personal social interaction is valuable. The video presentation does not provide that and I really missed it, particularly with the people who are so closely tied to my deep interest areas as this workshop was focused.
New Content in Presentation
This presentation included a lot of new content, ideas, and concepts that I have not really presented or written about in as open of a forum. I have received really strong positive feedback from the Faces of Perception, Depth of Perception, and Perception Matrix when I have talked about it with people and companies. I have included this content in the book on social bookmarking and folksonomy I am writing for O&Reilly and pieces have been in public and private workshops I have given, but it was long past time to let the ideas out into the open.
The components of perception came about through reading formal analysis and research from others as well as not having a good models myself to lean on to explain a lot of what I find from social computing service providers (web tools in the Web 2.0 genre as well as inside the firewall Enterprise 2.0 tools) as tool makers or service owners. The understandings that are brought to the table on a lot of research and analysis is far too thin and far too often badly confuses the roles and faces of the tool that are being reviewed or analyzed. In my working with tool makers and organizations implementing social tools the analysis and research is less than helpful and often makes building products that meet the user needs and desires really difficult. I am not saying that this conceptual model fixes it, but from those who have considered what it shows almost all have had realizations they have had a less than perfect grasp and have lacked the granularity they have needed to build, analyze, or research these social tools.
I am hoping to write these perspectives up in more depth at some point in the not too distant future, but the video and slides start getting the ideas out there. As I have been walking people through how to use the tools I have been realizing the content needed to best us the model and matrix may take more than a day of a workshop of even a few days to get the most complete value from it. These tools have helped me drastically increase my value in consulting and training in the very short time I have used them. Some are finding that their copying of features and functionality in other social services has not helped them really understand what is best for their user needs and are less than optimal for the type of service they are offering or believe they are offering.
Challenges as Opportunities for Social Networks and Services
Jeremiah Owyang posts "The Many Challenges of Social Network Sites" that lays out many of the complaints that have risen around social networking sites (and other social computing services). He has a good list of complaints, which all sounded incredibly familiar from the glory days of 1990 to 1992 for IT in the enterprise (tongue firmly planted in cheek). We have been through these similar cycles before, but things are much more connected now, but things also have changed very little (other than many of the faces). His question really needs addressing when dealing with Enterprise 2.0 efforts as these are the things I hear initially when talking with organizations too. Jeremiah asked for responses and the following is what I posted...
Response to Challenges of Social Network/Services
The past year or two, largely with Facebook growing the social networks and social computing tools have grown into the edges of mainstream. Nearly every argument made against these tools and services was laid down against e-mail, rich UI desktops (people spent hours changing the colors and arranging the interfaces), and IM years ago.
Where these tools are "seemingly" not working is mostly attributed to a severe lack of defining the value derived from using the tools. These news tools and services, even more so those of us working around them, need to communicate how to use the tools effectively and efficiently (efficiently is difficult as the many of the tools are difficult to use or the task flows are not as simple as they should be). The conceptual models & frameworks for those of us analyzing the tools have been really poor and missing giant perspectives and frameworks.
One of the biggest problems with many of these tools and services is they have yet to move out of early product mode. The tools and services are working on maturity getting features in the tools that people need and want, working on scaling, and iterating based on early adopters (the first two or three waves of people), which is not necessarily how those who follow will use the tools or need the tools to work.
Simplicity and limited options on top of tools that work easily and provide good derived value for the worklife and . As the tools that were disrupters to work culture in the past learned the focus needs to be on what is getting done and let people do it. Friending people, adding applications, tweaking the interface, etc. are not things that lead to easy monetization. Tools that help people really be social, interact, and get more value in their life (fun, entertainment, connecting with people near in thought, filtering information from the massive flow, and using the information and social connections in context where people need it) from the tools is there things must head. We are building the platforms for this, but we need to also focus on how to improve use of these platforms and have strong vision of what this is and how to get there.
[This is also posted at Challenges as Oppotunities for Social Networks and Services :: Personal InfoCloud with moderated comments turned on.]
Yahoo! Makes Good Call on Microsoft Purchase
The Wall Street Journal article about Yahoo! Rejecting Microsoft Bid (many more stories on TechMeme) was one that restored my faith in Yahoo! (not that it was really lost). I am proud of the Yahoo! board, but not for the reasons most are talking about. Since hearing about the Microsoft bid to take over Yahoo! I thought it was a really poor idea, well horrible idea. I really like Yahoo! and a lot of the things they are doing. I also really do like Microsoft (it is just some of their products that frustrate me to no end), in particular I think the MS Live group has come up with some great ideas out of research and that pleases e to know end. I am a giant fan of Ray Ozzie (oh, where have you gone Ray?).
Merger Would be a Giant Culture Clash
Yes, there are the technology concerns with some of the best open and shared technology development and augmentation coming out of Yahoo!, which is counter to the Microsoft focus on using their own tools (most of the web is built on open tools and Yahoo! helps make that a great platform to develop upon). This is not my big concern.
Where I see a giant problem is the management and employee culture. I know and have known a lot of employees and managers (mid-level and upper-level) at both organizations. Microsoft is a tough business culture with keeping the top percentage of employees and contributers on a project and moving others off to find a spot on other projects. In talking with many Microsoft employees (most were in the top performer group) this is often seen as horribly disruptive to the team when the changes occur. This management model also discourages sharing collectively and building collaboratively, which is also stated as a huge problem. These disruptions and metrics that are counter to strong development for the web and quick iterative cycles (not that Yahoo! seems to iterate quickly other than Flickr and a handful of other products) are quite counter to an open shared development process at Yahoo!. The clash of management cultures on this front, unless Microsoft did the unthinkable and adopted the Yahoo! approach, which could fix a lot of what has been holding Microsoft back (well, from current and former employees perspectives).
Related to the performance of employees the management teams go through similar reviews. But, many employees I have talked with (at conferences, networking events, airports and airplanes (there is always one within 10 seats of me it seams), and chat) have been really frustrated with management changes that can occur after 6 to 9 months. Having a new manager often changes focus and direction, which breaks momentum and continuity. Talking with great people Microsoft has lost over the past couple years, this management change was their biggest reason for leaving. The changes in management also often lead to conflicting measurement goals, which would make a great product or team look as if they were not working up to the standards. This is not management, but business process failure. This is not saying Microsoft has poor managers, quite the opposite in fact as many are some of the best I have run across in the business. But, the structure, processes, and measurement that the top management of Microsoft has established seems to be what has inhibited Microsoft from really top performance. What may work for some parts of Microsoft does not seem to work for other areas (actually, of all the Microsoft employees I have talked with from all across the organization the model does not work outside of sales).
The Yahoo! management has had more than their share of restructuring, but the disruptions this has made to product development and progress have been minimal. The goals, direction, and means to get the job done do not change for the most part (from what I have heard). Employees are flustered, but not demoralized. Yahoo! seems to have much greater continuity and central focus. Their products are well known, well used, and they iterate (over time). Many discussions with Yahoo! employees and managers outside the walls of Yahoo! are more frustrated by the silos and inability to work across the silos, but some the restructuring in the past couple of years has helped move to alleviate these problems. The cross platform team that works to help research, understand, and develop best of class solutions is a great step in this direction (from the perspective of many within Yahoo!). Yahoo! has known what has been holding back its efforts (Panama ate focus and resources) and has taken steps to alleviate the problems and move in a new positive direction. There are many things in Yahoo! that were more transparent two years ago than they are now (part of that may be those talking about things openly have been insanely busy). One of the things that seems to be problematic (from an outsider's perspective) is blinder focus and lack of concurrent development within groups.
Sum of Parts are Not Positive
When looking at the two cultures of the companies they are incredibly polar. One of the first steps in looking at a purchase or merger must be to look at compatibility of the cultures. Sure the products and services look like they may be a good fit by some at Microsoft, but those products and services are built by people with in a culture that propagates an environment to build wonderful things. Breaking that culture (Microsoft repeatedly iterated the vast savings the combination of MS and Y! would make) through integration of polar cultures has the high probability of destroying the value of what you believe will help. In this case a one plus one could equal less than one.
Partnering Not Combining
Yahoo! and Microsoft could have increased value partnering and working together though a Microsoft investment. What and how I do not know, but Microsoft needs positive outcomes and Yahoo! could use some financial boosts. Microsoft could also use a culture change, but that does not seem to be with in their vision as of yet and it is a huge organization to move in a new direction.
Yahoo! could improve its lot with partnerships, be it Microsoft, Ebay, Murdoch, Time Warner (AOL), and Google. I really do not want to see the Yahoo! search engine go away as the competition is good and provides alternatives should something go wrong with a one player or few player marketplace (oligopoly).
Getting More Value In Enterprise with Social Bookmarking
The last few weeks I have been running across a few companies postponing or canceling their social computing or Enterprise 2.0 efforts. The reasons vary from the usual budget shifts and staff changes (prior projects were not delivered on time), and leadership roles need filling. But two firms had new concerns of layoffs or budget cuts.
To both firms I pointed out now was the exact time they really needed to focus on some Enterprise 2.0 efforts, particularly social bookmarking as well as wikis and blogs. These solutions help gather information, find value across the organization, capture knowledge, build cohesiveness for members of the organization in time where there there is uncertainty. One of the biggest reasons that these tools make sense is their cost to deploy and receive solid value. As Josh Bernoff (and others in from Forrester) points out in the Strategies For Interactive Marketing In A Recession free report from Forrester, the cost to deploy is in the $50,000 to $300,000 range (usually more expensive for large and more complex deployments).
Social Bookmarking has Great Value in the Enterprise
Every organization needs to know itself better then they currently do. The employees and members of the organization are all trying to do their job better and smarter. The need to connect people inside an organization with others with similar interest, contexts, and perceptions is really needed. I am a huge fan of social bookmarking tools to help along these lines as it helps people hold on to information they have need, want, or have interest in (particularly with future uses) and put things in their own context and perception. Once people understand the value they derive from using the tools to hold on to information out of their vast flow and streams of information and data that run before them each day they quickly "get it". As people also share these bookmarks in the organization with their tags and annotations, they also realize quickly they are becoming a valuable conduit to helping others find information and they grasp the value they will derive from being a resource that adds value in the organization. Other people derive value from information in the organization and outside it being augmented with individual perspectives and context. When this is pair with search, as Connectbeam does with their social search that pairs with existing FAST, Google Search Appliance, and others in-house search engines, the value the whole organization receives is far beyond the cost and minimal effort people are putting into the tools to get smarter, by more easily holding on and sharing what they know.
Nearly every attendee to the workshops I have put on around this subject quickly realizes they undervalued the impact and capability of social bookmarking (as well as other social computing tools) in the enterprise. The also provides a strong foundation for better understanding social computing to increase the derived value for all parties (individuals, collective users, collaborative users, and the organization).
Is is time for your enterprise to get smarter and provide more value inside and out?
[This is also blogged at Getting More Value In Enterprise with Social Bookmarking :: Personal InfoCloud with moderated comments turned on.]
Social Computing Summit in Miami, Florida in April, 2008
ASIS&T has a new event they are putting on this year, the Social Computing Summit in Miami, Florida on April 10-11, 2008 (a reminder page is up at Yahoo's Upcoming - Social Computing Summit). The event is a single-track event on both days with keynote presentations, panels, and discussion.
The opening keynote is by Nancy Baym. I have been helping assist with organization of the Social Computing Summit and was asked by the other organizers to speak, which I am doing on the second day. The conference is a mix of academic, consumer, and business perspectives across social networking, politics, mobile, developing world, research, enterprise, open social networks (social graph and portable social networks) as well as other subjects. The Summit will be a broad view of the digital social world and the current state of understanding from various leaders in social computing.
There is an open call for posters for the event that closes on February 25, 2008. Please submit as this is looking to be a great event and more perspectives and expertise will only make this event more fantastic.
DataPortability Video is Place to Start Understanding
Marchall Kirkpatrick at ReadWriteWeb has posted a good background about New Video Explains the Basics of Data Portability. The DataPortability - Connect, Control, Share, Remix video is under 2 minutes in length and explains the reasons why the DataPoratbility.org group is important. It aims to ease the pain many are experiencing as they use more social media, social web services, social networks, and/or social computing services in their personal and work life.
Control
The biggest piece in this for me is control with translates to services respecting privacy wishes among other desires around trust and control of sharing. As Tom Raftery points out With the rising interest in, and use of Social Networks (FaceBook, Plaxo et al) there is growing unease in what those sites are doing with your data, never mind the inconvenience of uploading all your data every time you join a new site. The DataPortability.org aims to include in its focus data that is "shared between our chosen (and trusted) tools and vendors".
I have been working around the edges on a project whose aim is to respect these privacy wishes. This is one of the things that really needs to be at the core of all services entering into this market segment.
Ma.gnolia Goes Mobile
On Friday Ma.gnolia rolled out a mobile version of their site, M.gnolia - Mobile Ma.gnolia. This had me really excited as I now have access to my bookmarks in my pocket on my mobile. Ma.gnolia gives a quick preview in their blog post Ma.gnolia Blog: Flowers on the Go.
What Mobile Ma.gnolia Does and Does Not Do
First, off the mobile Ma.gnolia does not have easy bookmarking, which is not surprising given the state things in mobile browsers. I really do not see this as a huge downside. What I am head over heals happy about is access to my bookmarks (all 2800 plus). The mobile version allows searching through your own tags (if you are logged in). It currently has easy access to see that is newly bookmarked in Ma.gnolia groups you follow, your contact's bookmarks, popular bookmarks, your own tags, and your profile.
Mobile Site Bookmarks
One thing that is helpful for those that use mobile web browsing is having easy access to mobile versions of web sites. Yes, the iPhone and many smartphone users (I am in the Nokia camp with my well liked E61i) can easily browse and read regular web pages, but mobile optimized pages are quicker to load and have less clutter on a smaller screen. The iPhone, WebKit-based browsers (Nokia), Opera Mini, and other decent mobile web browsers all have eased mobile browsing use of regular webpages, but having a list of mobile versions is really nice.
Yesterday, Saturday, I created a Ma.gnolia Mobile Version Group so people can share web pages optimized for mobile devices (quicker/smaler downloads, smaller screens, less rich ads, etc.). One of the ways I was thinking people could use this is to find sites in this group then bookmark them for their own use with tags and organization that makes sense for themself. The aim is just to collect and share with others what you find helpful and valuable for yourself. This group will be monitored for spam as the rest of Ma.gnolia is (Ma.gnolia uses "rel="no-follow"" so there really is little value to spammers).
Ways You Can Use Mobile Ma.gnolia
This means if you tagged a store, restaurant, bar, transit site, or other item that has value when out walking around it is really nice to have quick access to it. It can also be a great way to read those items you have tagged "to read" (if you are a person that tags things in that manner) so you can read what you want in the doctor's office, bus, train, or wherever.
I have a lot of content I have bookmarked for locations I am work, live, and visit. When I come across something I want to remember (places to eat, drink, learn, hang, be entertained, etc.) I often dump them into the bookmarks. But, getting to this information has been painful from a mobile in the past. I am now starting to go back to things I have tagged with locations and add a "togo" tag so they are easier for me to find and use in the Ma.gnolia mobile interface. I have already added a bookmark for an museum exhibit that I really want to see that is not far from where I am. When a meeting is dropped, postponed, or runs short near the museum I can make a trip over and see it. There is so much information flowing through my devices and it is nice to be able to better use this info across my Personal InfoCloud in my trusted devices I have with me and use the information in context it is well suited for, when have stepped away from my desk or laptop.
I am looking forward to see where this goes. Bravo and deep thanks to the Larry and others at Ma.gnolia that made this happen!
Posting Elements of the Social Software Stack
I have been working for quite on finding a good way to explain the elements in the social software stack (or most of the important ones). I have blogged the result of the work as The Elements in the Social Software Stack (comments are open there).
In my public and in-house workshops I have worked through various graphics from others and my own to work as a foundation for talking to and through the subject. In November I finally sat down (in a hallway open space) the day before my workshop at the IA Konferenz in Stuttgart, Germany. It had all the elements that are part of a solid foundation, in progressive order:
- Identity
- Object (social object)
- Presence
- Actions
- Sharing
- Reputation
- Relationships
- Conversation
- Groups
- Collaboration
This and one other post that is in the works are becoming the corner stones for my work helping start-ups and enterprise work through social software (social computing) to properly solve their problems and address the issues at hand. It has also been the foundation for rethinking (mostly more clearly thinking about) social bookmarking and folksonomy. I am rewriting the work I have done toward the book based on these two pieces as it is making the communication of concepts clearer.
Who Does This Help?
People looking at the social software services should have a solid idea of the central elements, identity and the social object. After that it is a building process to account for the other elements leading up to the services full offerings. Social bookmarking (folksonomy related services) should get up to or include conversation. Tools like Ma.gnolia go up to groups for their social bookmarking service and they cover the elements leading up to that end point.
There is more that can be fleshed out in this, but it is a foundation and a starting point. The next piece will build on this posting and should be a good foundation for understanding.
Still here? Go read The Elements in the Social Software Stack :: Personal InfoCloud and offer constructive feedback. Thank you.
Pffft! Social Graph, We Need the Portable Social Network
In reading Alex Rudloff's "Privacy as Currancy" post I had two thoughts reoccur: 1) privacy is a currency back by trust; and 2) Pfffft! Social graph? Where is my Portable Social Network?
I agree with what Alex stated about wanting to move out of Facebook as my trust in them is gone completely (mostly driven by even though they apologized (poorly) Facebook still receives trackings of all your travels on the internet after you opt out, Om Malik's Zuckerberg's Mea Culp, Not Enough, and Brian Oberkirk's Facebook Harder to Shake than the Columbia Record Tape Club (a great read on the hurdles of really getting out of Facebook)). I will likely blog about the relationship between privacy and trust in another post in the not too distant future, as I have been talking about it in recent presentations on Social Software (Going Social and Putting Users First).
The Dire Need for Portable Social Networks
When Alex states:
Beacon had me so freaked out that I walked through what would happen if I simply removed my account (my natural, gut reaction). The fact is, I'd lose contact with a lot of people instantly. There's no easy way for me to take my data out and apply it somewhere else. There is no friend export and there isn't anywhere suitable for me to go.
I think we need portable social networks (or Social Network Portability as it is also known) before we need the social graph. Part of the interest in the social graph (mapping the relationships) is based on Facebook, but Facebook is a really poor interface for this information, it has some of the connections, some of the context, but it is not granular and does not measure strength (strong or weak ties) of relationships on a contextual and/or a preferential interest level. This social graph does little to help us move from one social software service to another other than to show a linkage.
There are strong reasons for wanting and needing the Portable Social Network. One is it makes it easy to drop into a new social software service and try it with social interactions with people whom we are already having social interactions. Whilst this is good it is also really important if something tragic or dire happens with a social software service we are already using, such as it is shut down, it is no longer performing for us, or it has given us a reason to leave through loss of trust. As I noted in the past (Following Friends Across Walled Gardens") leaving social software services is nothing new (even predates people leaving Delphi for Prodigy and Prodigy for AOL, etc.), but we still are not ready for this seemingly natural progression of moving house from one walled off social platform for another.
The Call for Action for Portable Social Network is Now
I am finding many of my friends have put their Facebook account on in hibernation (Facebook calls it &#quot;deactivation") and many have started taking the painful steps of really getting all of their information out of Facebook and planning to never go back. My friends have not sorted out what robust social software platform they will surface on next (many are still using Flickr, Twitter, Pownce, Tumblr and/or other options along with their personal blogs), but they would like to hold on to the digital statements of social relationship they made in Facebook and be able to drop those into some other service or platform easily.
One option could a just having a Smart Address Book or as Tim O'Reilly states Address Book 2.0. I believe that this should be a tool/service should have the relationships private and that privacy is controlled by the individual that owns the address book, possibly even accounting for the privacy request of the person whose address is in the address book. But, this is one option of many.
The big thing is we need Portable Social Networks now! This is not a far off in the future need it is a need of today.
[Comments are open on the syndicated post at Pffft! Social Graph, We Need the Portable Social Network :: Personal InfoCloud]
Can Facebook Change Its DNA
I wrote and posted Can Facebook Change Its DNA as a follow-up to for Business or LinkedIn Gets More Valuable regarding the changes needed in Facebook if it wants to be valuable (or have optimal value) for the business world.
The State of Enterprise Social Software - Pointer
I have written and posted The State of Enterprise Social Software on my Peronal InfoCloud blog as it has comments on and it also is where I am trying to keep my more professional pieces.
This blog post is a reaction to Richard McManus excellent post Big Vendors Scrap for Enterprise 2.0 Supremacy. The post seemed less about supremacy than scapping to be relevant. Many of the tools I am quite or somewhat familiar with and rather unimpressed. But, go read the other post to find my assessments of the tools, but also the tools that are doing much better jobs than the traditional enterprise vendors.
A Stale State of Tagging?
David Weinberger posted a comment about Tagging like it was 2002, which quotes Matt Mower discussing the state of tagging. I mostly agree, but not completely. In the consumer space thing have been stagnant for a while, but in the enterprise space there is some good forward movement and some innovation taking place. But, let me break down a bit of what has gone on in the consumer space.
History of Tagging
The history of tagging in the consumer space is a much deeper and older topic than most have thought. One of the first consumer products to include tagging or annotations was the Lotus Magellan product, which appeared in 1988 and allowed annotations of documents and objects on one's hard drive to ease finding and refinding the them (it was a full text search which was remarkably fast for its day). By the mid-90s Compuserve had tagging for objects uploaded into its forum libraries. In 2001 Bitzi allowed tagging of any media what had a URL.
The down side of this tagging was the it did not capture identity and assuming every person uses words (tag terms) in the same manner is a quick trip to the tag dump where tags are not fully useful. In 2003 Joshua Schacter showed the way with del.icio.us that not only allowed identity, upon which we can disambiguate, but it also had a set object in common with all those identities tagging it. The common object being annotated allows for a beginning point to discern similarity of identityĵs tag terms. Part of this has been driven on Joshua's focus on the person consuming the content and allowing a means for that consumer to get back to their information and objects of interest. (It is around this concept that folksonomy was coined to separate it from the content publisher tagging and non-identity related tagging.) This picked up on the tagging for one's self that was in Lotus Magellan and brings it forward to the web.
Valuable Tagging
It was in del.icio.us that we saw tagging that really did not work well in the past begin to become valuable as the clarity in tag terms that was missing in most all other tagging systems was corrected for in the use of a common object being tagged and the identity of the tagger. This set the foundation for some great things to happen, but have great things happened?
Tagging Future Promise
Del.icio.us set many of out minds a flutter with insight into the dreams of the capability of tagging having a good foothold with proper structure under them. A brilliant next step was made by RawSugar (now gone) to use this structure to make ease of disambiguating the tag terms (by appleseed did you mean: Johnny Appleseed, appleseeds for gardening/farming, the appleseed in the fruit apple, or appleseed the anime movie?). RawSugar was a wee bit before its time as it is a tool that is needed after there tagging (particularly folksonomy related tagging systems) start scaling. It is a tool that many in enterprise are beginning to seek to help find clarity and greater value in their internal tagging systems they built 12 to 18 months ago or longer. Unfortunately, the venture capitalists did not have the vision that the creators of RawSugar did nor the patience needed for the market to catch-up to the need in a more mature market and they pulled the plug on the development of RawSugar to put the technology to use for another purpose (ironically as the market they needed was just easing into maturity).
The del.icio.us movement drove blog tags, laid out by Technorati. This mirrored the previous methods of publisher tagging, which is most often better served from set categories that usually are derived from a taxonomy or simple set (small or large) of controlled vocabulary terms. Part of the problem inherent in publisher tags and categories is that they are difficult to use outside of their own domain (however wide their domain is intended - a specific site or cross-sites of a publisher). Using tags from one blog to another blog has problems for the same reason that Bitzi and all other publisher tags have and had problems, they are missing identity of the tagger AND a clear common object being tagged. Publisher tags can work well as categories for aggregating similar content within a site or set of commonly published sites where a tag definition has been set (but that really makes them set categories) and used consistently. Using Technorati tag search most often surfaces this problem quickly with many variation of tag use surfacing or tag terms being used to attract traffic for non-related content (Technorati's keyword search is less problematic as it relies on the terms being used in context in the content - unfortunately the two searches have been tied together making search really messy at the moment). There is need for an improved tool that could take the blog tags and marry them to the linked items in the content (if that is what is being talked about - discerning predicate in blog tags is not clear yet).
Current Tools that Advanced
As of a year ago there were more than 140 social bookmarking tools in the consumer space, but there was little advancement. But, there are a few services that have innovated and brought new and valuable features to market in tagging. As mentioned recently Ma.gnolia has done a really good job of taking the next steps with social interaction in social bookmarking. Clipmarks pioneered the sub-page tagging and annotation in the consumer tagging space and has a really valuable resource in that tool. ConnectBeam is doing some really good things in the enterprise space, mostly taking the next couple steps that Yahoo MyWeb2 should have taken and pairing it with enterprise search. Sadly, del.icio.us (according to comments in their discussion board) is under a slow rebuilding of the underlying framework (but many complaints from enterprise companies I have worked with and spoken indepth with complain del.icio.us continually blocks their access and they prefer not to use the service and are finding current solutions and options to be better for them).
A Long Way to Go
While there are examples that tagging services have moved forward, there is so much more room to advance and improve. As people's own collection of tagged pages and objects have grown the tools are needed to better refind them. This will require time search and time related viewing/scanning of items. The ability to use co-occurance of tag terms (what other tags were used on the object), with useful interfaces to view and scan the possibilities.
Portability and interoperability is extremely important for both the individual person and enterprise to aggregate, migrate, and search across their collections across services and devices (now that devices have tagging and have had for some time, as in Mac OS X Tiger and now Vista). Enterprises should also have the ability to move external tagged items in through their firewall and publish out as needed, mostly on an employee level. There is also desire to have B2B tagging with customers tagging items purchased so the invoicing can be in the customers terminology rather than the seller terminology.
One of the advances in personal tagging portability and interoperability can easily be seen when we tag on one device and move the object to a second device or service (parts of this are not quite available yet). Some people will take a photo on their mobile phone and add quick tags like "sset" and others to a photo of a sunset. They send that photo to a service or move it to their desktop (or laptop) and import the photo and the tag goes along with it. The application sees the "sset" and knows the photo was transfered from that person's mobile device and knows it is their short code for "sunset" and expands the tag to sunset accordingly. The person then adds some color attribute tags to the photo and moves the photo to their photo sharing service of choice with the tags appended.
The current tools and services need tools and functionality to heal some of the messiness. This includes stemming to align versions of the same word (e.g. tag, tags, tagging, bookmark, bookmarking). Tag with disambiguation in mind by offering co-occurrence options (e.g. appleseed and anime or johnny or gardening or apple). String matching to identify facets for time and date, names (from your address book), products, secret tag terms (to have them blocked from sharing), etc. (similar to Stikkit and GMail).
Monitoring Tools
Enterprise is what the next development steps really need to take off (these needs also apply to the power knowledge worker as well). The monitoring tools for tags from others and around objects (URLs) really need to fleshed out and come to market. The tag monitoring tools need to become granular based on identity and co-occurance so to more tightly filter content. The ability to monitor a URL and how it is tagged across various services is a really strong need (there are kludgy and manual means of doing this today) particularly for simple and efficient tools (respecting the tagging service processing and privacy).
Analysis Tools
Enterprise and power knowledge workers also are in need of some solid analysis tools. These tools should be able to identify others in a service that have similar interests and vocabulary, this helps to surface people that should be collaborating. It should also look at shifts in terminology and vocabulary so to identify terms to be added to a taxonomy, but also provide an easy step for adding current emergent terms to related older tagged items. Identify system use patterns.
Just the Tip
We are still at the tip of the usefulness of tagging and the tools really need to make some big leaps. The demands are there in the enterprise marketplace, some in the enterprise are aware of them and many more a getting to there everyday as the find the value real and ability to improve the worklife and workflow for their knowledge workers is great.
The people using the tools, including enterprise need to grasp what is possible beyond that is offered and start asking for it. We are back to where we were in 2003 when del.icio.us arrived on the scene, we need new and improved tools that understand what we need and provide usable tools for those solutions. We are developing tag islands and silos that desperately need interoperability and portability to get real value out of these stranded tag silos around or digital life.
Reading Information and Patterns
The past few weeks and months the subject of reading, analysis, and visualization have been coming up a lot in my talking and chatting with people. These are not new subjects for me as they are long time passions. Part of the discussion the past few weeks have been focussed on what is missing in social bookmarking tools (particularly as one's own bookmarks and tags grows and as the whole service scales) as wells as group discussion monitoring tools, but this discussion is not the focus of this post. The focus is on reading, understanding, and synthesis of information and knowledge.
Not that Reading
I really want to focus on reading. Not exactly reading words, but reading patterns and recognizing patterns and flows to get understanding. After we learn to read a group of letters as a word we start seeing that group of letters as a shape, which is a word. It is this understanding of patterns that interact and are strung together that form the type of reading I have interest in.
Yesterday, Jon Udell posted about analyzing two gymnasts make turns. He was frustrated that the analysis on television lacked good insight (Jon is a former gymnast). Jon, who is fantastic at showing and explaining technologies and interactions to get to the core values and benefits as well as demoing needed directions, applied his great skill and craft on gymnastics. He took two different gymnasts doing the same or similar maneuver frame-by-frame. Jon knew how to read what each gymnast was doing and shared his understanding of how to read the differences.
Similarly a week or so ago an article about the Bloomberg Terminal fantasy redesign along with the high-level explanations and examples of the Bloomberg Terminal brought to mind a similar kind of reading. I have a few friends and acquaintances that live their work life in front of Bloomberg Terminals. The terminals are an incredible flood of information and views all in a very DOS-looking interface. There is a skill and craft in not only understanding the information in the Bloomberg Terminal, but also in learning to read the terminal. One friend I chatted with while he was working (years ago) would glance at the terminal every minute. I had him explain his glancing, which essentially was looking for color shifts in certain parts of the screen and then look for movement of lines and characters in other areas. He just scanned the screen to look for action or alerts. His initial pass was triage to then discern where to focus and possibly dive deeper or pivot for more related information.
The many of the redesign elements of the Bloomberg Terminals understood the reading and ability to understand vast information (in text) or augmented the interface with visualizations that used a treemap (most market analysts are very familiar with the visualization thanks to SmartMoney's useage). But, the Ziba design was sparse. To me it seemed like many of the market knowledge workers used to the Bloomberg Terminal and knew how to read it would wonder where their information had gone.
Simplicity and Reading with Experience
The Ziba solution's simplicity triggers the need in understanding the balance between simplicity just breaking down the complex into smaller easy to understand bits and growing into understanding the bits recollected in a format that is usable through recognition and learned reading skills. The ability to read patterns is learned in many areas of life in sport, craft, and work. Surfers look at the ocean waves and see something very different from those who do not surf in the ebb, flow, breaks, surface currents and under currents. Musicians not only read printed music but also hear music differently from non-musicians, but formally trained musicians read patterns differently from those who have just "picked it up". There has been a push in business toward data dashboards for many years, but most require having the right metrics and good data, as well as good visualizations. The dashboards are an attempt to provide reading information and data with an easier learning curve through visualization and a decreased reliance on deep knowledge.
Getting Somewhere with Reading Patterns
Where this leads it there is a real need in understanding the balance between simplicity and advanced interaction with reading patterns. There is also a need to understand what patterns are already there and how people read them, including when to adhere to these patterns and when to break them. When breaking the patterns there needs to be simple means of learning these new patterns to be read and providing the ability to show improved value from these new patterns. This education process can be short video screen shots, short how-to use the interface or interactions. Building pattern libraries is really helpful.
Next, identify good patterns that are available and understand why they work, particularly why they work for the people that use then and learn how people read them and get different information and understanding through reading the same interface differently. Look at what does not work and where improved tools are needed. Understand what information is really needed for people who are interested in the information and data.
 An example of this is Facebook, which has a really good home page for each Facebook member, it is a great digital lifestream of what my friends are doing. It is so much better at expressing flow and actions the people I have stated I have social interest in on Facebook than any other social web tool that came before Facebook. Relative to the individual level, Facebook fails with its interface of the information streams for its groups. Much of the content that is of interest in Facebook happens in the groups, but all the groups tell you is the number of new members, new messages, new videos, and new wall posts. There is much more valuable information tucked in there, such as who has commented that I normally interact with, state the threads that I have participated in that have been recently updated, etc.
An example of this is Facebook, which has a really good home page for each Facebook member, it is a great digital lifestream of what my friends are doing. It is so much better at expressing flow and actions the people I have stated I have social interest in on Facebook than any other social web tool that came before Facebook. Relative to the individual level, Facebook fails with its interface of the information streams for its groups. Much of the content that is of interest in Facebook happens in the groups, but all the groups tell you is the number of new members, new messages, new videos, and new wall posts. There is much more valuable information tucked in there, such as who has commented that I normally interact with, state the threads that I have participated in that have been recently updated, etc.
This example illustrates there needs to be information to read that has value and could tell a story. Are the right bits of information available that will aid understanding of the underlying data and stories? It the interface helpful? Is it easy to use and can it provide more advanced understanding? Are there easy to find lessons in how to read the interface to get the most information out of it?
Why Ma.gnolia is One of My Favorite Social Bookmarking Tools
After starting the Portable Social Network Group in Ma.gnolia yesterday I received a few e-mails and IMs regarding my choice. Most of the questions were why not just use tags and del.icio.us. After I posted my Ma.Del Tagging Bookmarklet post I have had a lot of questions about Ma.gnolia and my preference as well as people thought I was not a fan of it. I have been thinking I would blog about my usage, but given my work advising on social bookmarking and social web, I shy away talking about what I use as what I like is likely not what is going to be a good fit for others. But, my work is one of the reasons I want to talk about what I like using as nearly every customer of mine and many presentation attendees look at del.icio.us first (it kicked the door wide open with a tool that was light years ahead of all others), but it is not for everybody and there are many other options. Much of my work is with enterprise and organizations of various size, which del.icio.us is not right for them for privacy reasons. I still add to del.icio.us along with my favorite as there are many people that have subscribed to the at feed as they derive value from that subscription so I take the extra step to keep that feed as current.
Ma.gnolia Offers Great Features for Sociality
I have two favorite tools for my own personal social bookmarking reasons Ma.gnolia and Clipmarks (I don't think I have anything publicly shared in Clipmarks). First the later, I use Clipmarks primarily when I only want to bookmark a sub-page element out on the web, which are paragraphs, sentences, quotes, images, etc.
I moved to try Ma.gnolia again last Fall when something changed in del.icio.us search and the results were not returning things that were in del.icio.us. My trying Ma.gnolia, by importing all of my 2200 plus bookmarks not only allowed me to search and find things I wanted, but I quickly became a fan of their many social features. In the past year or less they have become more social in insanely helpful and kind ways. Not only does Ma.gnolia have groups that you can share bookmarks with but there is the ability to have discussions around the subject in those groups. Sharing with a group is insanely easy. Groups can be private if the manager wishes, which makes it a good test ground for businesses or other organizations to test the social bookmarking waters. I was not a huge fan of rating bookmarks as if I bookmarked something I am wanting to refind it, but in a more social context is has value for others to see the strength of my interest (normall 3 to 5 stars). One of my favorite social features is giving "thanks", which is not a trigger for social gaming like Digg, but is an interpersonal expression of appreciation that really makes Ma.gnolia a friendly and positive social environment.
Started with Beauty, but Now with Ease
Ma.gnolia started as a beautiful del.icio.us (it was not the first) and the beauty got in the way of usability for many. But, Ma.gnolia has kept the beautiful strains and added simple ease of use in a very Apple delightful moments sort of way. The thanks are a nice treat, but the latest interactions that provide non-disruptive ease of use to accomplish a task, without completely taking you away from your previous flow (freaking brilliant in my viewpoint - anything that preserves flow to accomplish a short task is a great step). Another killer feature is Ma.gnolia Roots, which is a bookmarklet that when clicked hovers a semi-transparent layer over the webpage to show information from Ma.gnolia about that page (who has linked to it, tags, annotations, etc.) and makes it really easy to bookmark that page from that screen. The API (including a replica of the del.icio.us API that nearly all services use as the standard), add-ons, Creative Commons license for your bookmarks, many bookmarklet options, and feed options. But, there are also the little things that are not usually seen or noticed, such as great URLs that can be easily parsed, all pages are properly marked up semantically, and Microformats are broadly and properly used throughout the site (nearly at every pivot).
Intelligently Designed
For me Ma.gnolia is not only a great site to look at, a great social bookmarking site that is really social (as well as polite and respectful of my wishes), but a great example for semantic web mark-up (including microformats). There is so much attention to detail in the page markup that for those of us that care it is amazingly beautiful. The visual layer can be optimized for more white space and detail or for much easier scrolling. The interactions, ease of use, and delightful moments that assist you rather than taking you out of your flow (workflow, taskflow, etc.) and make you ask why all applications and social sites are not this wonderful.
Ma.gnolia is not perfect as it needs some tools to better manage and bulk edit your own bookmarks. It could use a sort on search items (as well as narrow by date range). Search could use some RedBull at times. It could improve with filtering by using co-occurance of tag terms as well as for disambiguation.
Overall for me personally, Ma.gnolia is a tool I absolutely love. It took the basic social bookmarking idea in del.icio.us and really made it social. It has added features and functionality that are very helpful and well executed. It is an utter pleasure to use. I can not only share things easily and get the wonderful effects of social interaction, but I can refind things in my now 2,500 plus bookmarks rather easily.
Ma.gnolia Portable Social Networking Group Now Open
I have been talking with people about portable social networks for 18 months or more and initially blogged about it last November (2006) in my post Following Friends Across Walled Gardens. Recently the portable social network effort has flowed into Microformats: Social Network Portability. I have been following Brian Oberkirk's portable social network blog posts and we have had more than a few chats about this in the last few months. Finally it seems that some core geeks are on this quest as well, thanks to a gathering of minds at Foo Camp with Brad Fitzpatrick and David Recordon posting Thoughts on the Social Graph and the starting of the Social Network Portability Google Group. The oauth (more info on OpenAuth). Kevin Lawver has been rocking the real world with his Portable Social Networks at Mashup Camp discussion and example.
Ma.gnolia Portable Social Network Group
Tracking these small bits that are loosely joined needed a little more glue. To this end I started a ma.gnolia group for portable social networking to aggregate links. Already there is a good groups of people joining the group, which is promising. I have been critical of Ma.gnolia in the past, but they have iterated and built a social bookmarking site that has become my favorite social bookmarking service (Clipmarks is my second favorite when I need to just hold onto sub-page items). If you want to keep follow, keep track of the current site, or (even better) contribute bookmarks as well as join in discussion join the group. Ma.gnolia makes joining insanely simple by using OpenID for account creation and login (should you be part of the modern web world - such as having an AOL AIM account).
Open Conversations and Privacy Needs for Business
I thought I would share the latest press bit around this joint, Thomas Vander Wal was quoted in Inc Magazine What's Next: Shout it Out Loud (or in the August 2007 issue beginning on page 69). The article focuses the need and desire for companies to share and be open with more of their data and information. Quite often companies are getting bit by their privacy around what they do (how their source their products/resources, who they donate money to, etc.) and rumors start. It is far more efficient and helpful to be open with that information, as it gets out anyway.
Ironically, in the same paper issue on page 26 there is a an article about When Scandal Knocks..., which includes a story about Jamba Juice and a blog post that inaccurately claimed it had milk in its products, which could have easily been avoided if Jamba Juice had an ingredients listing on its web site.
The Flip Side
There are two flip sides to this. One is the Apple converse, which is a rare example of a company really making a mythic organization out of its privacy. The second is companies really need privacy for some things, but the control of information is often too extreme and is now more harmful than helpful.
Viable Privacy
I have been working on a much longer post looking at the social software/web tools for and in the enterprise. Much of of the extreme openness touted in the new web charge is not a viable reality inside enterprise. There are a myriad of things that need to be private (or still qualify as valid reasons for many). The list include preparations for mergers and acquisitions, securities information dealings (the laws around this are what drive much of the privacy and are out dated), reorganizations (restructuring and layoffs, which organizations that have been open about this have found innovative solutions from the least likely places), personal employee records, as well as contractual reasons (advising or producing products for competitors in the same industry or market segment). Out side of these issues, which normally add up to under 30 to 40% of the whole of the information that flows through an organization, there is a lot of room for openness in-house and to the outside world.
Need for Enterprise Social Tools Grasping Partial Privacy
When we look at the consumer space for social software there are very few consumer tools that grasp social interaction and information sharing on a granular level (Ma.gnolia, Flickr, and the SixApart tools Vox and LiveJournal are the exceptions that always come to mind). But, many of the tools out there that are commonly used as examples of social web tools really fall down when business looks at them and thinks about privacy and selective sociality (small groups). The social web tools all around really need to grow up and improve in this area. As we are seeing the collaboration and social tools evolve to more viable options we start to see their more glaring holes that do not reflect the reality of human social interaction.
Closing the Gap
What we need is for companies to be more open so the marketplace is a more consumer and communicative environment, but we also need our still early social web tools to reflect our social realities that not everything is public and having tools that better fit those needs.
[Cross-posted at Personal InfoCloud: Open Converastions... with comments open on that posting.]
Sharing and Following/Listening in the Social Web
You may be familiar with my granular social network post and the postings around the Personal InfoCloud posts that get to personal privacy and personal management of information we have seen, along with the Come to Me Web, but there is an element that is still missing and few social web sites actually grasp the concept. This concept is granular in the way that the granular social network is granular, which focusses on moving away from the concept of "broad line friends" that focus on our interest in everything people we "friend", which is not a close approximation of the non-digital world of friend that we are lucky to find friends who have 80 percent common interests. This bit that is missing focusses on the sharing and following (or listening) aspects of our digital relationships. Getting closer to this will help filter information we receive and share to ease the overflow of information and make the services far more valuable to the people using them.
Twitter Shows Understanding
Twitter in its latest modifications is beginning to show that it is grasping what we are doing online is not befriending people or claiming friend, but we are "following" people. This is a nice change, but it is only part of the equation that has a few more variables to it, which I have now been presenting for quite a few years (yes and am finally getting around to writing about). The other variables are the sharing and rough facets of type of information we share. When we start breaking this down we can start understanding the basic foundation for building a social web application that can begin to be functional for our spheres of sociality.
Spheres of Sociality
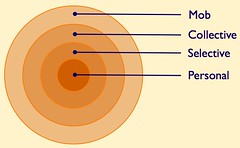 The Spheres of Sociality are broken into four concentric rings:
The Spheres of Sociality are broken into four concentric rings:
- Personal
- Selective
- Collective
- Mob
There are echos of James Surowiecki's Wisdom of Crowds in the Spheres of Sociality as they break down as follows. The personal sphere is information that is just for one's self and it is not shared with others. The selective sphere, which there may be many a person shares with and listens to, are closed groups that people are comfortable sharing and participating with on common interests (family, small work projects, small group of friends or colleagues, etc.). The collective sphere is everybody using that social tool that are members of it, which has some common (precise or vague) understanding of what that service/site is about. The last sphere is the mob, which are those people outside the service and are not participants and who likely do not understand the workings or terminology of the service.
These sphere help us understand how people interact in real life as well as in these social environments. Many of the social web tools have elements of some of these or all of these spheres. Few social web tools provide the ability to have many selective spheres, but this is a need inside most enterprise and corporate sites as there are often small project teams working on things that may or may not come to fruition (this will be a future blog post). Many services allow for just sharing with those you grant to be your followers (like Twitter, Flickr, the old Yahoo! MyWeb 2.0, and Ma.gnolia private groups, etc.). This selective and segmented group of friends needs a little more examination and a little more understanding.
Granular Sharing and Following
 The concepts that are needed to improve upon what has already been set in the Spheres of Sociality revolve around breaking down sharing and following (listening) into more discernible chunks that better reflect our interests. We need to do this because we do not always want to listen everything people we are willing to share with are surfacing. But, the converse is also true we may not want to share or need to share everything with people we want to follow (listen to).
The concepts that are needed to improve upon what has already been set in the Spheres of Sociality revolve around breaking down sharing and following (listening) into more discernible chunks that better reflect our interests. We need to do this because we do not always want to listen everything people we are willing to share with are surfacing. But, the converse is also true we may not want to share or need to share everything with people we want to follow (listen to).
In addition to each relationship needing to have sharing and listening properties, the broad brush painted by sharing and listening also needs to be broken down just a little (it could and should be quite granular should people want to reflect their real interests in their relationships) to some core facets. The core facets should have the ability to share and listen based on location, e.g. a person may only want to share or listen to people when they are in or near their location (keeping in mind people's location often changes, particularly for those that travel or move often). The location facet is likely the most requested tool particularly for those listening when people talk about Twitter and Facebook. Having some granular categories or tags to use as filters for sharing and listening makes sense as well. This can break down to simple elements like work, play, family, travel, etc. as broad categories it could help filter items from the sharing or listening streams and help bring to focus that which is of interest.
Breaking Down Listening and Sharing for Items
| Yourself | Others | |
|---|---|---|
| Share | Yes | Yes/No |
Where this gets us it to an ability to quickly flag the importance of our interactions with others with whom we share information/objects. Some things we can set on an item level, like sharing or just for self, and if sharing with what parameters are we sharing things. We will set the default sharing with ourself on so we have access to everything we do. This follows the Spheres of Sociality with just personal use, sharing with selective groups (which ones), share with the collective group or service, and share outside the service. That starts setting privacy of information that starts accounting for personal and work information and who could see it. Various services have different levels of this, but it is a rare consumer services that has the selective service sorted out (Pownce comes close with the options for granularity, but Flickr has the ease of use and levels of access. For each item we share we should have the ability to control access to that item, to just self or out across the Spheres of Sociality to the mob, if we so wish. Now we can get beyond the item level to presetting people with normative rights.
Listening and Sharing at the Person Level
| Others Settings | ||
|---|---|---|
| Listen/Follow | Yes | No |
| Granular Listen/Follow | Yes | No |
| Granular Share | Yes | No |
| Geo Listen/Follow | Yes | No |
| Geo Share | Yes | No |
We can set people with properties that will help use with default Sphere of Sociality for sharing and listening. The two directions of communication really must be broken out as there are some people we do not mind them listening to the selective information sharing, but we may not have interest in listening to their normal flow of offerings (optimally we should be able to hear their responses when they are commenting on items we share). Conversely, there may be people we want to listen to and we do not want to share with, as we may not know them well enough to share or they may have broken our privacy considerations in the past, hence we do not trust them. For various reasons we need to be able to decide on a person level if we want to share and listen to that person.
Granular Listening and Sharing
Not, only do we have needs and desires for filtering what we share and listen to on the person level, but if we have a means to set some more granular levels of sharing, even at a high level (family, work, personal relation, acquaintance, etc.). If we can set some of these facets for sharing and have them tied to the Spheres we can easily control who and what we share and listen to. Flickr does this quite well with the simple family, friends, contacts, and all buckets, even if people do not use them precisely as such as family and friends are the two selective buckets they offer to work with (most people I know do not uses them precisely as such with those titles, but it provides a means of selective sharing and listening).
Geo Listening and Sharing
Lastly, it is often a request to filter listening and sharing by geography/location access. There are people who travel quite a bit and want to listen and share with people that are currently local or will be local to them in a short period, but their normal conversations are not fully relevant outside that location. Many people want the ability not to listen to a person unless they are local, but when a person who has some relationship becomes local the conversation may want to be shared and/or listened to. These settings can be dependent on the granular listening and sharing parameters, or may be different.
Getting There...
So, now that this is out there it is done? Hmmm, if it were only so easy. The first step is getting developers of social web and social software to begin understanding the social relationships that are less broad lines and more granular and directional. The next step is a social interaction that people need to understand or that the people building the interfaces need to understand, which is if and how to tell people the rights granted are not reciprocal (it is seems to be a common human trait to have angst over non-reciprocal social interactions, but it is the digital realm that makes it more apparent that the flesh world).
Inline Messaging
Many of the social web services (Facebook, Pownce, MySpace, Twitter, etc.) have messaging services so you can communication with your "friends". Most of the services will only ping you on communication channels outside their website (e-mail, SMS/text messaging, feeds (RSS), etc.) and require the person to go back to the website to see the message, with the exception of Twitter which does this properly.
Inline Messaging
Here is where things are horribly broken. The closed services (except Twitter) will let you know you have a message on their service on your choice of communication channel (e-mail, SMS, or RSS), but not all offer all options. When a message arrives for you in the service the service pings you in the communication channel to let you know you have a message. But, rather than give you the message it points you back to the website to the message (Facebook does provide SMS chunked messages, but not e-mail). This means they are sending a message to a platform that works really well for messaging, just to let you know you have a message, but not deliver that message. This adds extra steps for the people using the service, rather than making a simple streamlined service that truly connects people.
Part of this broken interaction is driven by Americans building these services and having desktop-centric and web views and forgetting mobile is not only a viable platform for messaging, but the most widely used platform around the globe. I do not think the iPhone, which have been purchased by the owners and developers of these services, will help as the iPhone is an elite tool, that is not like the messaging experience for the hundreds of millions of mobile users around the globe. Developers not building or considering services for people to use on the devices or application of their choice is rather broken development these days. Google gets it with Google Gears and their mobile efforts as does Yahoo with its Yahoo Mobile services and other cross platform efforts.
Broken Interaction Means More Money?
I understand the reasoning behind the services adding steps and making the experience painful, it is seen as money in their pockets through pushing ads. The web is a relatively means of tracking and delivering ads, which translates into money. But, inflicting unneeded pain on their customers can not be driven by money. Pain on customers will only push them away and leave them with fewer people to look at the ads. I am not advocating giving up advertising, but moving ads into the other channels or building solutions that deliver the messages to people who want the messages and not just notification they have a message.
These services were somewhat annoying, but they have value in the services to keep somebody going back. When Pownce arrived on the scene a month or so ago, it included the broken messaging, but did not include mobile or RSS feeds. Pownce only provides e-mail notifications, but they only point you back to the site. That is about as broken as it gets for a messaging and status service. Pownce is a beautiful interface, with some lightweight sharing options and the ability to build groups, and it has a lightweight desktop applications built on Adobe AIR. The AIR version of Pownce is not robust enough with messaging to be fully useful. Pownce is still relatively early in its development, but they have a lot of fixing of things that are made much harder than they should be for consuming information. They include Microfomats on their pages, where they make sense, but they are missing the step of ease of use for regular people of dropping that content into their related applications (putting a small button on the item with the microformat that converts the content is drastically needed for ease of use). Pownce has some of the checkboxes checked and some good ideas, but the execution of far from there at the moment. They really need to focus on ease of use. If this is done maybe people will comeback and use it.
Good Examples
So who does this well? Twitter has been doing this really well and Jaiku does this really well on Nokia Series60 phones (after the first version Series60). Real cross platform and cross channel communication is the wave of right now for those thinking of developing tools with great adoption. The great adoption is viable as this starts solving technology pain points that real people are experiencing and more will be experiencing in the near future. (Providing a solution to refindability is the technology pain point that del.icio.us solved.) The telecoms really need to be paying attention to this as do the players in all messaging services. From work conversations and attendees to the Personal InfoCloud presentation, they are beginning to get the person wants and needs to be in control of their information across devices and services.
Twitter is a great bridge between web and mobile messaging. It also has some killer features that add to this ease of use and adoption like favorites, friends only, direct messaging, and feeds. Twitter gets messaging more than any other service at the moment. There are things Twitter needs, such as groups (selective messaging) and an easier means of finding friends, or as they are now appropriately calling it, people to follow.
Can we not all catch up to today's messaging needs?
Does IBM Get Folksonomy?
While I do not aim to be snarky, I often come off that way as I tend to critique and provide criticism to hopefully get the bumps in the road of life (mostly digital life) smoothed out. That said...
Please Understand What You Are Saying
I read an article this morning about IBM bringing clients to Second Life, which is rather interesting. There are two statements made by Lee Dierdorff and Jean-Paul Jacob, one is valuble and the other sinks their credibility as I am not sure they grasp what they actually talking about.
The good comment is the "5D" approach, which combines the 2D world of the web and the 3D world of Second Life to get improved search and relevance. This is worth some thinking about, not a whole lot as the solution as it is mentioned can have severe problems scaling. The solution of a virtual world is lacking where it does not augment our understanding much beyond 2D as it leaves out 4 of the 6 senses (it has visual and audio), and provides more noise into a pure conversation than a video chat with out the sensory benefits of video chat. The added value of augmented intelligence via text interaction is of interest.
I am not really sure that Lee Dierdorff actually gets what he is saying as he shows a complete lack of even partial understanding of what folksonomy is. Jacob states, "The Internet knows almost everything, but tells us almost nothing. When you want to find a Redbook, for instance, it can be very hard to do that search. But the only real way to search in 5D is to put a question to others who can ask others and the answer may or may not come back to you. It's part of social search. Getting information from colleagues (online) -- that's folksonomy." Um, no that is not folksonomy and not remotely close. It is something that stands apart and is socially augmented search that can viably use the diverse structures of a folksonomy to find relevant information, but asking people in a digital world for advise is not folksonomy. It has value and it is how many of us have used tools like Twitter and other social software that helps us keep those near in thought close (see Local InfoCloud). There could be a need for a term/word for that Jacob is talking about, but social search seems to be quite relevant as a term.
Related, I do have a really large stack of criticism for the IMB DogEar product that would improve it greatly. It needs a lot of improvement as a social bookmarking and folksonomy tool, but also from the social software interaction side there are things that really must get fixed for privacy interests in the enterprise before it really could be a viable solution. There are much better alternatives for social bookmarking inside an enterprise other than DogEar, which benefits from being part of the IBM social software stack Lotus Connections as the whole stack is decent together, but none of the parts are great, or even better than good by them self. DogEar really needs to get to a much more solid product quickly as their is a lot of interest now for this type of product, but it is only a viable solution if one is only looking at IBM products for solutions.
Understanding Taxonomy and Folksonmy Together
I deeply appreciate Joshua Porter's link to from his Taxonomies and Tags blog post. This is a discussion I have quite regularly as to the relation and it is in my presentations and workshops and much of my tagging (and social web) training, consulting, and advising focusses on getting smart on understanding the value and downfalls of folksonomy tagging (as well as traditional tagging - remember tagging has been around in commercial products since at least the 1980s). The following is my response in the comments to Josh' post...
Response to Taxonomy and Tags
Josh, thanks for the link. If the world of language were only this simple that this worked consistently. The folksonomy is a killer resource, but it lacks structure, which it crucial to disambiguating terms. There are algorithmic ways of getting close to this end, but they are insanely processor intensive (think days or weeks to churn out this structure). Working from a simple flat taxonomy or faceted system structure can be enabled for a folksonomy to adhere to.
This approach can help augment tags to objects, but it is not great at finding objects by tags as Apple would surface thousands of results and they would need to be narrowed greatly to find what one is seeking.
There was an insanely brilliant tool, RawSugar [(now gone thanks to venture capitalists pulling the plug on a one of a kind product that would be killer in the enterprise market)], that married taxonomy and folksonomy to help derive disambiguation (take appleseed as a tag, to you mean Johnny Appleseed, appleseed as it relates to gardening/farming, cooking, or the anime movie. The folksonomy can help decipher this through co-occurrence of terms, but a smart interface and system is needed to do this. Fortunately the type of system that is needed to do this is something we have, it is a taxonomy. Using a taxonomy will save processor time, and human time through creating an efficient structure.
Recently I have been approached by a small number of companies who implemented social bookmarking tools to develop a folksonomy and found the folksonomy was [initially] far more helpful than they had ever imagined and out paced their taxonomy-based tools by leaps and bounds (mostly because they did not have time or resources to implement an exhaustive taxonomy (I have yet to find an organization that has an exhaustive and emergent taxonomy)). The organizations either let their taxonomist go or did not replace them when they left as they seemed to think they did not need them with the folksonomy running. All was well and good for a while, but as the folksonomy grew the ability to find specific items decreased (it still worked fantastically for people refinding information they had personally tagged). These companies asked, "what tools they would need to start clearing this up?" The answer a person who understands information structure for ease of finding, which is often a taxonomist, and a tool that can aid in information structure, which is often a taxonomy tool.
The folksonomy does many things that are difficult and very costly to do in taxonomies. But taxonomies do things that folksonomies are rather poor at doing. Both need each other.
Complexity Increases as Folksonomies Grow
I am continually finding organizations are thinking the social bookmarking tools and folksonomy are going to be simple and a cure all, but it is much more complicated than that. The social bookmarking tools will really sing for a while, but then things need help and most of the tools out there are not to the point of providing that assistance yet. There are whole toolsets missing for monitoring and analyzing the collective folksonomy. There is also a need for a really good disambiguation tool and approach (particularly now that RawSugar is gone as a viable approach).
The Social Enterprise
I am just back from Enterprise 2.0 Conference held in Boston, where I presented Bottom-up All The Way Down: How Tags Help Businesses Organize (thanks to Stowe Boyd for the tantalizing session title), which was liveblog captured by Sandy Kemsley as "Enterprise 2.0: Thomas Vander Wal". I did not catch all of the conference due to some Boston business meetings and connecting with friends and meeting digi-friends whose work I really enjoy face-to-face. The sessions I made it to were good and enlightening and as always the hallway conversations were worth their weight in gold.
Ms. Perceptions and Fear Inside the Corporate Walls
Having not been at true business focussed conference in years (until the past few weeks) I was amazed with how much has changed and how much has stayed the same. I was impressed with the interest and adoption around the social enterprise tools (blogs, wikis, social bookmarking/folksonomy, etc.). But, the misperceptions (Miss Perceptions) are still around and have grown-up (Ms. Perception) and are now being documented by Forrester and others as being fact, but the questions are seemingly not being asked properly. Around the current social web tools (blogs, wikis, social bookmarking, favoriting, shared rating, open (and partially open collaboration) I have been finding little digital divide across the ages. Initially there is a gap when tools get introduced in the corporate environment. But this age gap very quickly disappears if the incredible value of the tools is made clear for people s worklife, information workflow, and collaboration, as well as simple instructions (30 second to 3 minute videos) and simply written clear guidelines that outline acceptable use of these tools.
I have been working with technology and its adoption in corporations since the late 80s. The misperception that older people do not get technology, are foreign to the tools, and they will not ever get the technical tools has not changed. It is true that nearly all newer technologies come into the corporation by those just out of school and have relied on these tools in university to work intelligently to get their degree. But, those whom are older do see the value in the tools once they have exposure and see the value to their worklife (getting their job done), particularly if the tools are relatively simple to use and can be adopted with simple instruction (if it needs a 10 to 200 page manual and more than 15 minutes of training to start using the product effectively adoption will be low). Toby Redshaw of Motorola stated on a panel that he found in Motorola (4600 blogs and wikis and 2600 people using social bookmarking) "people of all ages adopt these tools if they understand the value connected to their work". Personally, I have seen this has always been the case in the last 20 years as this is how we got e-mail, messaging, Blackberries, web pages, word processing, digital collaboration tools (the last few rounds and the current ones), etc. in the doors of small to large organizations. I have worked in and with technically forward organizations and ones that are traditionally thought of as slow adopters and found adoption is based on value to work and ease of use and rarely based on age.
This lack of understanding around value added and (as Toby Redshaw reinforced) "competitive advantage" derived from the social tools available today for use in the enterprise is driven by fear. It is a fear of control that is lost from the top-down. But, the advantage to the company from having this information shared and easy found and used for collaboration to improve knowledge, understanding, and efficiency can not be dismissed and needs to be embraced. The competitive advantage is what is gained today, but next month or next quarter it could mean just staying even.
Getting Beyond Fear
But, what really is important is the communication and social enterprise tools are okay and add value, but the fear is overplayed, as a percentage rarely occurs, and handling the scary stuff it relatively easy to handle.
Tagging and Social Bookmarking in Enterprise
In the halls I had many conversations around tagging ranging from old school tagging being painful because the experts needed to tag things (meaning they were not doing the job as expert they were hired to do and their terms were not widely understood) all the way to the social bookmarking tools are not scaling and able to keep up with the complexity, nor need to disambiguate the terms used. But, I was really impressed with the number of organizations that have deployed some social bookmarking effort (officially or under somebody's desk) and found value (often great value).
Toby Redshaw: I though folksonomy was going to be some Bob Dillon touchy-feely hippy taxonomy thing, but it has off the chart value far and above any thing we had expected.
My presentation had 80 to 90 percent of the people there using social bookmarking tools in some manner in their organization or worklife. The non-verbal feed back as I was presenting showed interest in how to make better sense of what was being tagged, how to use it better in their business, how to integrate with their taxonomy, and how to work with the information as the tools scale. The answers to these are longer than the hour I have, they are more complex because it all depends on the tools, how they are set-up and designed, how they are used, and the structures of information inside and outside their organization.
Stitching Conversation Threads Fractured Across Channels
Communicating is simple. Well it is simple at its core of one person talking with another person face-to-face. When we communicate and add technology into the mix (phone, video-chat, text message, etc.) it becomes more difficult. Technology becomes noise in the pure flow of communication.
Now With More Complexity
But, what we have today is even more complex and difficult as we are often holding conversation across many of these technologies. The communication streams (the back and forth communication between two or more people) are now often not contained in on communication channel (channel is the flavor or medium used to communicate, such as AIM, SMS, Twitter, e-mail, mobile phone, etc.).
We are seeing our communications move across channels, which can be good as this is fluid and keeping with our digital presence. More often than not we are seeing our communication streams fracture across channels. This fracturing becomes really apparent when we are trying to reconstruct our communication stream. I am finding this fracturing and attempting to stitch the stream back together becoming more and more common as for those who are moving into and across many applications and devices with their own messaging systems.
The communication streams fracture as we pick-up an idea or need from Twitter, then direct respond in Twitter that moves it to SMS, the SMS text message is responded back to in regular SMS outside of Twitter, a few volleys back and forth in SMS text, then one person leaves a voicemail, it is responded to in an e-mail, there are two responses back and forth in e-mail, an hour later both people are on Skype and chat there, in Skype chat they decide to meet in person.
Why Do We Want to Stitch the Communication Stream Together?
When they meet there is a little confusion over there being no written overview and guide. Both parties are sure they talked about it, but have different understandings of what was agreed upon. Having the communication fractured across channels makes reconstruction of the conversation problematic today. The conversation needs to be stitched back together using time stamps to reconstruct everything [the misunderstanding revolved around recommendations as one person understands that to mean a written document and the other it does not mean that].
Increasingly the reality of our personal and professional lives is this cross channel communication stream. Some want to limit the problem by keeping to just one channel through the process. While this is well intentioned it does not meet reality of today. Increasingly, the informal networking leads to meaningful conversations, but the conversations drifts across channels and mediums. Pushing a natural flow, as it currently stands, does not seem to be the best solution in the long run.
Why Does Conversation Drift Across Channels?
There are a few reasons conversations drift across channels and mediums. One reason is presence as when two people notice proximity on a channel they will use that channel to communicate. When a person is seen as present, by availability or recently posting a message in the service, it can be a prompt to communicate. Many times when the conversation starts in a presence channel it will move to another channel or medium. This shift can be driven by personal preference or putting the conversation in a medium or channel that is more conducive for the conversation style between people involved. Some people have a preferred medium for all their conversations, such as text messaging (SMS), e-mail, voice on phone, video chat, IM, etc.. While other people have a preferred medium for certain types of conversation, like quick and short questions on SMS, long single responses in e-mail, and extended conversations in IM. Some people prefer to keep their short messages in the channel where they begin, such as conversations that start in Facebook may stay there. While other people do not pay attention to message or conversation length and prefer conversations in one channel over others.
Solving the Fractured Communication Across Channels
Since there are more than a few reasons for the fractured communications to occur it is something that needs resolution. One solution is making all conversations open and use public APIs for the tools to pull the conversations together. This may be the quickest means to get to capturing and stitching the conversation thread back together today. While viable there are many conversations in our lives that we do not want public for one reason or many.
Another solution is to try to keep your conversations in channels that we can capture for our own use (optimally this should be easily sharable with the person we had the conversation with, while still remaining private). This may be where we should be heading in the near future. Tools like Twitter have become a bridge between web and SMS, which allows us to capture SMS conversations in an interface that can be easily pointed to and stitched back together with other parts of a conversation. E-mail is relatively easy to thread, if done in a web interface and/or with some tagging to pull pieces in from across different e-mail addresses. Skype chat also allows for SMS interactions and allows for them to be captured, searched, and pulled back together. IM conversations can easily be saved out and often each item is time stamped for easy stitching. VoIP conversations are often easily recorded (we are asking permission first, right?) and can be transcribed by hand accurately or be transcribed relatively accurately via speech-to-text tools. Voice-mail can now be captured and threaded using speech-to-text services or even is pushed as an attachment into e-mail in services as (and similar to) JConnect.
Who Will Make This Effortless?
There are three types of service that are or should be building this stitching together the fractured communications across channels into one threaded stream. I see tools that are already stitching out public (or partially public) lifestreams into one flow as one player in this pre-emergent market (Facebook, Jaiku, etc.). The other public player would be telecoms (or network provider) companies providing this as a service as they currently are providing some of these services, but as their markets get lost to VoIP, e-mail, on-line community messaging, Second Life, etc., they need to provide a service that keeps them viable (regulation is not a viable solution in the long run). Lastly, for those that do not trust or want their conversation streams in others hands the personally controlled application will become a solutions, it seems that Skype could be on its way to providing this.
Is There Demand Yet?
I am regularly fielding questions along these lines from enterprise as they are trying to deal with these issues for employees who have lost or can not put their hands on vital customer conversations or essential bits of information that can make the difference in delivering what their customers expect from them. Many have been using Cisco networking solutions that have some of these capabilities, but still not providing a catch all. I am getting queries from various telecom companies as they see reflections of where they would like to be providing tools in a Come to Me Web or facilitating bits of the Personal InfoCloud. I am getting requests from many professionals that want this type of solution for their lives. I am also getting queries from many who are considering building these tools, or pieces of them.
Some of us need these solutions now. Nearly all of us will need these solutions in the very near future.
Full-Day Social Web & Folksonomy Workshop at d.construct
 Tickets for the d.construct Workshops go on sale June 14, 2007. Buying a ticket for a full-day workshop provides free access to the full d.construct conference on September 7th. I am presenting the following workshop on September 6th...
Tickets for the d.construct Workshops go on sale June 14, 2007. Buying a ticket for a full-day workshop provides free access to the full d.construct conference on September 7th. I am presenting the following workshop on September 6th...
Building the Social Web with Tagging / Folksonomies
Thomas Vander Wal, creator of the term folksonomy, provides a full-day workshop on building the social web through a detailed look at tagging systems. The workshop will provide a foundation for understanding social software from the perspective of the people who use it. This perspective helps site owners solve the cold start problem of social software not starting out social.
The focus of the workshop is to provide a solid foundation for building and maintaining a social system from the design and management perspective. The workshop will cover policy issues, monitoring, analysis, and tagging systems as features that are added to the mix of existing tools.
The day will provide a brief history of tagging from the days of tagging in the desktop era to current web use. The exercises will focus on better understanding what happens in tagging systems and use those lessons to frame how to build better systems and make better use of the information that is made relevant through those tagging systems. The workshop includes overviews of social web pattern interaction design and the wide array of features.
Folksonomy Provides 70 Percent More Terms Than Taxonomy
While at the WWW Conference in Banff for the Tagging and Metadata for Social Information Organization Workshop and was chatting with Jennifer Trant about folksonomies validating and identifying gaps in taxonomy. She pointed out that at least 70% of the tags terms people submitted in Steve Museum were not in the taxonomy after cleaning-up the contributions for misspellings and errant terms. The formal paper indicates (linked to in her blog post on the research more steve ... tagger prototype preliminary analysis) the percentage may even be higher, but 70% is a comfortable and conservative number.
Is 70% New Terms from Folksonomy Tagging Normal?
In my discussion with enterprise organizations and other clients that are looking to evaluate their existing tagging services, have been finding 30 percent to nearly 70 percent of the terms used in tagging are not in their taxonomy. One chat with a firm who had just completed updating their taxonomy (second round) for their intranet found the social bookmarking tool on their intranet turned up nearly 45 percent new or unaccounted for terms. This firm knew they were not capturing all possibilities with their taxonomy update, but did not realize their was that large of a gap. In building their taxonomy they had harvested the search terms and had used tools that analyzed all the content on their intranet and offered the terms up. What they found in the folksonomy were common synonyms that were not used in search nor were in their content. They found vernacular, terms that were not official for their organization (sometimes competitors trademarked brand names), emergent terms, and some misunderstandings of what documents were.
In other informal talks these stories are not uncommon. It is not that the taxonomies are poorly done, but vast resources are needed to capture all the variants in traditional ways. A line needs to be drawn somewhere.
Comfort in Not Finding Information
The difference in the taxonomy or other formal categorization structure and what people actually call things (as expressed in bookmarking the item to make it easy to refind the item) is normally above 30 percent. But, what organization is comfortable with that level of inefficiency at the low end? What about 70 percent of an organization s information, documents, and media not being easily found by how people think of it?
I have yet to find any organization, be it enterprise or non-profit that is comfortable with that type of inefficiency on their intranet or internet. The good part is the cost is relatively low for capturing what people actually call things by using a social bookmarking tool or other folksonomy related tool. The analysis and making use of what is found in a folksonomy is the same cost of as building a taxonomy, but a large part of the resource intensive work is done in the folksonomy through data capture. The skills needed to build understanding from a folksonomy will lean a little more on the analytical and quantitative skills side than the traditional taxonomy development. This is due to the volume of information supplied can be orders of magnitude higher than the volume of research using traditional methods.
Folksonomy Book In Progress
Let me start with an announcement. I have not had any answer for continual question after I present on tagging and folksonomy (I also get the question after the Come to Me Web and Personal InfoCloud presentations), which is "where is your book?" Well I finally have an answer, I have signed with O'Reilly to write a book, initially titled Understanding Folksonomy (this may change) and it may also be a wee bit different from your normal O'Reilly book (we will see how it goes).
I am insanely excited to be writing for O'Reilly as I have a large collection of their books from over the years - from the programming PHP, Perl, Python, and Ruby to developer guides on JavaScript, XHTML, XML, & CSS to the Polar Bear book on information architecture, Information Dashboard Design, and Designing Interfaces: Patterns for Effective Interaction Design along with so many more.
Narrowing the Subject
One of the things that took a little more time than I realized it would take is narrowing the book down. I have been keeping a running outline of tagging and folksonomy related subjects that have been in my presentations and workshop as well as questions and answers from these sessions. The outline includes the deep knowledge that has some from client work on the subject (every single client has a different twist and set of constraints. Many of the questions have answers and for some the answers are still being worked out, but the parameters and guidelines are known to get to viable solutions.
Well, when I submitted the outline I was faced with the knowledge that I had submitted a framework for a 800 to 1,000 page book. Huh? I started doing the math based on page size, word counts, bullets in the outline, and projects words per bullet and those with knowledge were right. So, I have narrowed it down to an outline that should be about 300 pages (maybe 250 and maybe a few more than 300).
What Is In This Smaller Book?
I am using my tagging and folksonomy presentations as my base, as those have been iterated and well tested (now presented some version of it well over 50 times). While I have over 300 design patterns captured from tagging service sites (including related elements) only a few will likely be used and walked through. I am including the understanding from a cognitive perspective and the lessening of technology pain that tagging services can provide to people who use them. There will also be a focus on business uses for intranet and web.
When Will This Be Done
Given that I have a rather busy Fall with client work, workshops, and presentations I set a goal to finish the writing by the end of Summer. It sounds nuts and it really feels like grad school all over again, but that is my reality. I have most of the words in my head and have been speaking them. Now I need to write them (in a less dense form than I blog).
Your Questions and Feedback
If you have questions and things you would like covered please e-mail me (contact in the header nav above). I will likely be setting up a blog to share and post questions (this will happen in a couple weeks). I am also looking for sites, organizations, and people that would like to be included in the case studies and interviews (not all will end up in the book, but those that are done will end up tied to the book in some manner). Please submit suggestions for this section if you have any.
From the HQ Office
It has been a good stretch of travel, mostly for work/professional life, but also took a trip to Florida for family holiday. At the moment I am back in the office working on proposals for upcoming projects of various lengths for clients and working through the process of writing, which involves dead trees at the final stages.
Web 2.0 Expo and SF Bay Area
I am soon off again to the San Francisco Bay Area to speak at the O'Reilly Web 2.0 Expo and have business meetings around the Bay Area (please ping via e-mail if you would like to meet-up during this time).
WWW2007 Workshop on Tagging and Metadata
Early next month I am off to Banff to keynote the WWW2007 Workshop on Tagging and Metadata for Social Information Organization. I am not sure how long this trip will be as I will have some pressing work around this time.
Social Software Summit
Lastly, I should note there will be a Social Software Summit that will run at the same time as the ASIS&T IA Summit next Spring (Spring 2008) in Miami. The Social Software Summit is still in its early stages of planning (the idea, dates, location, and interest have been launched). The dates are April 10-11 2008. I have a role in the planning and preparation for this event, along with some other incredible people.
On SXSW Tag You're It Panel
I am a panelist on the Tag You're It Panel at South by SouthWest in Austin, Texas. Others on the panel are the ever fantastic: Heath Row (moderator), George Oates, and Ben Brown. The panel information:
Tag You're It on Saturday 10 March 2007 at 2:00 pm to 3:00 pm. The panel will be looking at what people are actually doing inside social tagging systems and where things have gone in the past couple years with tagging. We will get beyond the notion that tagging is cool by providing examples of how people are really using the tools in innovative and useful ways.
Stop by and say hello.
Ma.Del Tagging Bookmarklet
Out of frustration with Yahoo MyWeb no longer surfaces results in Yahoo Search, which made Yahoo Search much better for me than any other web search. Now that this is no long functioning and there is no response as to if or when it will return I am back to Google and Microsoft Live Search (the relevancy is better for me on many things). But, this change also removes the value of MyWeb and this has me looking back to Ma.gnolia (also am a huge fan of Raw Sugar and their facets, but that is another longer post).
New Tagging Combo Bookmarklet
When I became a fan of MyWeb I used some glue to make Del.icio.us and MyWeb Combo Bookmarklet.
So now I have done the same for Ma.gnolia and del.icio.us with the Ma.Del Marklet (drag to bookmark bar in FireFox and Safari only). This was built using the Ma.gnolia bookmarklet Ma.rker Mini as its base.
Cuban Clocks and Music Long Tail Discovery
The last two trips to San Francisco I have heard a latin version of Coldplay's Clocks on KFOG and it really intrigued me. This last trip I was in the car for four songs and one of them was Coldplay's Clocks by the Cuban All Stars. I have been trying to track this track down since first hearing, but am not having great luck. This continually happens when I listen to KFOG, which is about the only regular radio station I will listen to (I much prefer XM Radio for is lack of advertising and blathering idiots spouting off while playing overplayed songs that have little merit.
What I like about this version of Clocks by the Cuban All Stars (I have seen the dashboard metadata list it as Ibrahim Ferrer, but it has not been described as such by the DJs on KFOG). This is where my music recommendations break. But, some digging on the KFOG website points me to Rhythms Del Mundo as the source (but their Flash site seems horribly broken in all browsers as none of the links work). I have found the album on iTunes, but only a partial listing and none of the physical music store options have this in stock as it is not mainstream enough (how I miss Tower).
This all seems like far more work that should be needed. But, not if one has even slightly long tail musical interests. I had a wonderful discussion along these lines wish Cory from IODA about this and the lack of really good long tail discovery systems.
I use Last.fm to discover new things from friend#039;s lists, but the Last.fm neighbor recommendations seem to only work on more mainstream interests (Pandora really falls off on the long tail for me). Now if KFOG put their play list in KFOG, it would help greatly and I would add them to my friend list (or I could move back home to the San Francisco Bay Area).
Stikkit Adds an API
Stikkit has finally added an API for Stikkit. This makes me quite happy. Stikkit has great ease of information entry and it is perfect for adding annotations to web-based information.
Stikkit is My In-line Web Triage
I have been using Stikkit, from the bookmarklet, as my in-line web information triage. If I find an event or something I want to come back to latter (other than to read and bookmark) I pop that information into Stikkit. Most often it is to remind me of deadlines, events, company information, etc. I open the Stikkit bookmarklet and add the information. The date information I add is dumped into my Stikkit calendar, names and addresses are put into the Stikkit address book, and I can tag them for context for easier retrival.
Now with the addition of the API Stikkit is now easy to retrieve a vCard, ical, or other standard data format I can drop into my tools I normally aggregate similar information. I do not need to refer back to Stikkit to copy and paste (or worse mis-type) into my work apps.
I can also publish information from my preferred central data stores to Stikkit so I have web access to events, to dos, names and addresses, etc. From Stikkit I can then share the information with only those I want to share that information with.
Stikkit is growing to be a nice piece for microcontent tracking in my Personal InfoCloud.
It is Finally IT and Design in Enterprise (and Small Business)
My recent trip to Northern California to speak at the UIE Web App Summit and meetings in the Bay Area triggered some good ideas. One thread of discovery is Enterprise, as well as small and medium sized business, is looking at not only technology for solutions to their needs, but design.
IT Traditions
Traditionally, the CIO or VP IT (and related upper management roles) have focussed on buying technology "solutions" to their information problems. Rarely have the solutions fixed the problems as there is often a "problem with the users" of the systems. We see the technology get blamed, the implementation team get blamed (many do not grasp the solution but only how to install the tools, as that is the type of service that is purchased), and then the "users need more training".
Breaking the Cycle of Blame and Disappointment
This cycle of blame and disappointment in technology is breaking around a few important realizations in the IT world.
Technology is not a Cure All
First, the technology is always over sold in capability and most often needs extensive modification to get working in any environment (the cost of a well implemented system is usually about the same as a built from scratch solution - but who has the resources to do that). Most CIOs and technology managers are not trusting IT sales people or marketing pitches. The common starting point is from the, "your tool can not do what you state" and then discussions can move from there. Occasionally, the tools actually can do what is promised.Many, decision makers now want to test the product with real people in real situations. Solution providers that are good, understand this and will assist with setting up a demonstration. To help truly assess the product the technical staff in the organization is included in the set-up of the product.
People and Information Needs
Second, the problems are finally being identified in terms of people and information needs. This is a great starting place as it focusses on the problems and the wide variety of personal information workflows that are used efficiently by people. We know that technology solutions that mirror and augment existing workflows are easily adopted and often used successfully. This mirroring workflow also allows for lower training costs (occasionally there is no training needed).
Design with People in Mind
Third, design of the interaction and interface must focus on people and their needs. This is the most promising understanding as it revolves around people and their needs. Design is incredibly important in the success of the tools. Design is not just if it looks pretty (that does help), but how a person is walked through the steps easily and how the tools is easy to interact with for successful outcomes. The lack of good design is largely what has crippled most business tools as most have focussed on appealing to the inner geek of the IT manager. Many IT managers have finally realized that their interface and interaction preferences are not remotely representative of 95 percent of the people who need to or should be using the tools.
It is increasingly understood that designing the interaction and interface is very important. The design task must be done with the focus on the needs of real people who will be using the product. Design is not sprinkling some Web 2.0 magic dust of rounded corners, gradients, and fading yellow highlights, but a much deeper understanding that ease of use and breaking processes into easy steps is essential.
Smile to Many Faces
This understanding that buying a technology solutions is more than buying code to solve a problem, but a step in bringing usable tools in to help people work efficiently with information. This last week I talk to many people in Enterprise and smaller businesses that were the technical managers that were trying to get smarter on design and how they should approach digital information problems. I also heard the decision managers stating they needed better interfaces so the people using the tools could, well use the tools. The technology managers were also coming to grips that their preferences for interfaces did not work with most of the people who need the tools to work.
Technology Companies Go Directly to the Users
I have also been seeing the technology tool makers sitting with their actual people using their tools to drastically improve their tools for ease of use. One President of a technology tool maker explained it as, ":I am tired of getting the blame for making poor tools and losing contracts because the technology decision makers are not connected with the real needs of the people they are buying the tools for." This president was talking to three or four users on problems some of his indirect clients were having with a tool they really needed to work well for them. This guy knows the tech managers traditionally have not bought with the people needing to use the tools in mind and is working to create a great product for those people with wants and needs. He also knows how to sell to the technology managers to get their products in the door, but knows designing for the people using the product is how he stays in the company.
Digging Out of Digital Limbo
Things are mostly back to normal here. The new MacBook Pro has been wonderful (it is a bit odd to mostly focus on it as a tool and not the center of adoration as I normally do for Apple products) and even better getting my digital life flowing again. I found some gaps in e-mail had been backed-up in an odd place and they were restored.
The gap between sending my PowerBook out for data recovery (not possible as the drive was toast) and getting the MacBook Pro in my hands, even until the time of my first full back-up was one of trying to balance new info and old. Fearful of a "perfect storm" I was pushing my digital life out into corners of the internet. I have been pulling things back in to my laptop and re-building notes from paper I jot quick bits on.
Moving Forward
I have since picked up a Maxtor OneTouch III Turbo with one terrabyte of capacity set to RAID1 across its two drives (translates to mirrored 500MB drives). This seems like an insane amount of space, but knowing I can have more than one version of a back-up (that is part of what knocked me out) and can back-up my other external drive info (where my 70GB of music is stored) provides a nice peace of mind. I am also integrating my Amazon S3 into the equation as well as my .Mac storage. I am using Apple Backup and Retrospect Express to currently do my back-ups. I want a book able image for use on my Intel Mac, which it seems to have the capability of providing. I am still looking at other options. I have been a big fan of Carbon Copy Cloner, but it does not provide a bootable image capability on Intel Macs.
This New Year
I mostly have my feet under myself this new year, oh yes, Happy New Year! Work is taking off full bore and some of the bumps from last year seem to have been ironed out and lessons learned. I had planned to do a year end book wrap-up and a first year in business as InfoCloud Solutions, Inc., but the lack of a computer pushed those ideas off the table. I do not make New Years resolutions, as I try to make needed adjustments as they are needed and try not to put them off to some arbitrary date. I will be providing one or two most posts later this week, when the pile subsides and things go out the door.
Until then, enjoy Macworld and do your backups.
Ghosts of Technology Past, Present, and Future
The past two days have brought back many memories that have reminded me of the advances in technology as well as the reliance on technology.
Ghost of Rich Web Past
I watched a walk through of a dynamic prototype yesterday that echoed this I was doing in 1999 and 2000. Well, not exactly doing as the then heavy JavaScript would blow up browsers. The DHTML and web interfaces that helped the person using the site to have a better experience quite often caused the browser to lock-up, close with no warning, or lock-up the machine. This was less than 100kb of JavaScript, but many machines more than two years old at that time and with browsers older than a year or two old did not have the power. The processing power was not there, the RAM was not there, the graphics cards were not powerful, and the browsers in need of optimizing.
The demonstration yesterday showed concepts that were nearly the exact concept from my past, but with a really nice interface (one that was not even possible in 1999 or 2000). I was ecstatic with the interface and the excellent job done on the prototype. I realized once again of the technical advances that make rich web interfaces of "Web 2.0" (for lack of a better term) possible. I have seen little new in the world of Ajax or rich interfaces that was not attempted in 2000 or 2001, but now they are viable as many people's machines can now drive this beauties.
I am also reminded of the past technologies as that is what I am running today. All I have at my beck and call is two 667MHz machines. One is an Apple TiBook (with 1 GB of RAM) and one is a Windows machine (killer graphics card with 256MB video RAM and 500MB memory). Both have problems with Amazon and Twitter with their rich interfaces. The sites are really slow and eat many of the relatively few resources I have at my disposal. My browsers are not blowing up, but it feels like they could.
Ghost of Technology Present
The past year or two I have been using my laptop as my outboard memory. More and more I am learning to trust my devices to remind me and keep track of complex projects across many contexts. Once things are in a system I trust they are mostly out of my head.
This experience came to a big bump two days ago when my hard drive crashed. The iterative back-ups were corrupted or faulty (mostly due to a permission issue that would alter me in the middle of the night). The full back-up was delayed as I do not travel with an external drive to do my regular back-ups. My regularly scheduled back-ups seem to trigger when I am on travel. I am now about 2.5 months out from my last good full back-up. I found an e-mail back-up that functioned from about 3 weeks after that last full backup. Ironically, I was in the midst of cleaning up my e-mail for back-up, which is the first step to my major back-up, when the failure happened.
I have a lot of business work that is sitting in the middle of that pile. I also have a lot of new contacts and tasks in the middle of that period. I have my client work saved out, but agreements and new pitches are in the mire of limbo.
Many people are trying to sync and back-up their lives on a regular basis, but the technology is still faulty. So many people have faulty syncing, no matter what technologies they are using. Most people have more than two devices in their life (work and home computer, smart phone, PDA, mobile phone with syncable address book and calendar, iPod, and other assorted options) and the syncing still works best (often passably) between two devices. Now when we start including web services things get really messy as people try to work on-line and off-line across their devices. The technology has not caught up as most devices are marketed and built to solve a problem between two devices and area of information need. The solutions are short sighted.
Ghost of the Technosocial Future
Last week I attended the University of North Carolina Social Software Symposium (UNC SSS) and while much of the conversation was around social software (including tagging/folksonomy) the discussion of technology use crept in. The topic of digital identity was around the edges. The topic of trust, both in people and technology was in the air. These are very important concepts (technology use, digital identity, and trusted technology and trusted people). There is an intersection of the technosocial where people communicate with their devices and through their devices. The technology layer must be understood as to the impact is has on communication. Communication mediated by any technology requires an understanding of how much of the pure signal of communication is lost and warped (it can be modified in a positive manner too when there are disabilities involved).
Our digital communications are improving when we understand the limitations and the capabilities of the technologies involved (be it a web browser of many varied options or mobile phone, etc.). Learning the capabilities of these trusted devices and understanding that they know us and they hold our lives together for us and protect our stuff from peering eyes of others. These trusted devices communicate and share with other trusted devices as well as our trusted services and the people in our lives we trust.
Seeing OpenID in action and work well gave me hope we are getting close on some of these fronts (more on this in another post). Seeing some of the great brains thinking and talking about social software was quite refreshing as well. The ability to build solid systems that augment our lives and bring those near in thought just one click away is here. It is even better than before with the potential for easier interaction, collaboration, and honing of ideas at our doorstep. The ability to build an interface across data sets (stuff I was working on in 1999 that shortened the 3 months to get data on your desk to minutes, even after running analytics and working with a GIS interface) can be done in hours where getting access to the wide variety of information took weeks and months in the past. Getting access to data in our devices to provide location information with those we trust (those we did not trust have had this info for some time and now we can take that back) enables many new services to work on our behalf while protecting our wishes for whom we would like the information shared with. Having trusted devices working together helps heal the fractures in our data losses, while keeping it safe from those we do not wish to have access. The secure transmission of our data between our trusted devices and securely shared with those we trust is quickly arriving.
I am hoping the next time I have a fatal hard drive crash it is not noticeable and the data loss is self-healed by pulling things back together from resources I have trust (well placed trust that is verifiable - hopefully). This is the Personal InfoCloud and its dealing with a Local InfoCloud all securely built with trusted components.
Let Me Count the 24 Ways
It is that wonderful time of the year for 24 ways, the wonderful 24 gifts from one web developer to the rest of us. I deeply enjoyed them last year and am looking forward to the remainder of the gems.
Personal Twitter Use
Early this past summer I started playing with Twitter (then donning the moniker "twttr"). It drove me absolutely bonkers. I could not sort out how to stop my handful of friends from dumping their, "I had a gorgonzola cheese sandwich" into my SMS. I would be in a meeting or giving a presentation and my phone would vibrate with this micro-blogging nothingness of life status updates.
Since then I stopped pushing anything, but direct responses, to SMS or e-mail. This really made Twitter much better. But, then I was not peeking at it. In the past month or two I have had it running as a regular tab in my browser and it is much better, it does not scream for my attention, but acts more like me looking across a bar to see what my friends are doing. It is now a nice social space with quiet chatter.
Last week when I was in San Francisco I was using Twitter and Dodgeball, but found my friends in SF mostly using Dodgeball at night and I was mostly not in proximity (I only have one person in my DC network on Dodgeball). The Dodgeball demands to connect with Google account pushed me over from logging in, which is the last thing I want.
Twitter in SF worked wonderfully. I could state a meeting was shifted and announce I was going to get coffee and would find another person that wanted to join up to do the same. I found others doing the same and I would join them. I could also partake in cross continent chatter with friends.
This week I moved Twitter out to its own narrow (it needs to be even narrower - is there a Greasemonkey script to make it narrow) window. I keep it on my large monitor to my right, which is my social space (calendar, skype, YIM, AIM/iChat, and now Twitter). These are my social glancing applications and Twitter is a really nice compliment to the pack of Local InfoCloud tools, now that I have it set to match my expectations and desire for interruptions (or desire for minimal interruptions).
New Podcast Interview of Thomas Vander Wal by Brian Oberkirch
I have been slow in pointing to a recent Podcast interview of Thomas Vander Wal by Brian Oberkirch. Brian and I have been trying to schedule this chat for quite some time. We cover a broad range of subjects that are of interest to me and I have been thinking about and playing with lately.
Brian has a great collection of podcasts interviews from his edgework series. I have listened to many and really enjoy them.
Stikkit Is a Nice Example of a Personal InfoCloud Tool
I have been using the newly launched Stikkit for the last day and rather enjoying it. Stikkit, is a web-based postit with super powers of a notepad with bookmark, calendar, lite address book for people, tagging, to do, and reminders to SMS (in the U.S.) and/or e-mail.
Stikkit is the product of values of n start-up that is the founded by Rael Dornfest, formerly of O'Reilly.
This summer I was in Portland and got a preview of Stikkit and was really impressed. It was a slightly different application at that point, but it had the great bones to be a really nice application for one's own Personal InfoCloud. Much of the really good intuitive scripting that turns dates in text into calendar entries, text to do lists into ones that can be checked-off, and other text to real functionality is in the current version and just sings.
When I used the Stikkit bookmarklet it captured pertinent information from a page that I wanted to track, which had date related information that is essential to something I have interest in, it made a calendar entry. The focus of the Personal InfoCloud is to have applications and devices that let people hold on to information that they have interest in and move it across devices, as well as add their own context. Stikkit, really is a wonderful step in making a rather friction free approach to the Personal InfoCloud. It puts the focus on the person and their wants and needs for the use of the information in a page. Stikkit can free the information from the confines of the web page and alert the person to important dates. Stikkit also allows the person to share what they find easily.
I think the key to Stikkit is the term "easily", which is the underpinning of the whole application. The only thing I would love to see is Microformats added so that the information in Stikkit could be dropped into my own address book or calendar and synced (if the gods of syncing shine favorably on me that day). Looking at the markup in Stikkit, it seems to be semantically well structured to easily add microformats in the near future.
This has been cross-posted at Stikkit at personalinfocloud.com where there is commenting turned on.
Yahoo! Bookmarking and Broken Roadmap
[Update: [This response came from Nathan Arnold an engineer on the Bookmarks/Social Search team
It would seem that either we've under-communicated the roadmap ideas, and you've gotten the wrong impression of what's going on.
No MyWeb user is being forced to use Bookmarks or Del.icio.us just yet. Del.icio.us continues to stand on its own, and MyWeb and Bookmarks continue to share your data. If you save something in Bookmarks, it will be private in MyWeb. If you save something in MyWeb, it will show up in Bookmarks and you can edit it their (bookmarks being private, only you can access it).
The eventual roadmap is to migrate users off MyWeb only when the good social elements of MyWeb have been integrated into the bookmarks product. Until that time, users can continue to use MyWeb as they see fit. When we do shut the switch off to MyWeb, the same features will be available on Bookmarks.
At that time, they will ALSO have the option of migrating content to del.icio.us.
Hope that clears it up...]
I have received a lot of response to one item from yesterday's post, Yahoo! Bookmarks Beta (or Alpha), which looked at the new bookmarking replacement from Yahoo!. The response has been rather harsh and critical of one move, that is pulling the MyWeb 2 content into the Bookmarks Beta. Most IMs and e-mail are from people who are really livid that their social bookmarking content is pulled into a closed system. Had Yahoo been smart and clearly stated they were doing this on the Bookmark Beta page it would not have helped it seems as they took people's information from one context and are breaking that context. Not grasping this essential component has be questioning if Yahoo really has thought this through. Yesterday I focussed on the design and development problems, today I am focussing on the product issues.
Bookmarking Beta
Yahoo! drastically needed to update their Bookmarking tool. It is a tool that is widely used and was really clumsy in today's web works. The ease of use of the new tool and adopting MyWeb 2's saved pages and adding tagging to folders was essential. Bookmarks is a closed system as it always has been, but some elements of sociality are integrated that are seemingly familiar and comfortable for regular people.
Bookmarking Beta has a good overview video highlighting some of the new functionality and possibly helpful help pages (ironically the link for help is broken in Safari and the in Firefox you can get to the help page, but the content is not viewable). The marking and explanation around the new Bookmarking tool is good and is needed.
Breaking Social Bookmarking
Yahoo! moving the the small base of people using MyWeb 2 into Bookmarking Beta was flat out foolish. I thought so yesterday, but there were so many other things that needed addressing I lumped it in with the rest. The livid responses I received about this one made me realize it really needs more focus. Yahoo! never explained or marketed MyWeb 2 well, if at all. It is a rather good tool that did some things really well. One of the things that was quite good was its ability to share and recommend items from your friends and contacts. This was a component that oddly was well ahead of del.icio.us and was in the product before Yahoo! acquired del.icio.us. The potential for great social interactions, recommendations, and interactions was central for most of the people that used MyWeb 2 regularly. For others it was a more friendly interface to a social bookmarking tool than del.icio.us (I will get to this in more depth in a moment).
Moving MyWeb 2 content, which is content with intent to be social into a tool that is not social is really backwards thinking. The strong reactions by people who use the tool prove this out. Connecting those dots to begin with deeply has be questioning if Yahoo! gets what they are doing. It is an old web mistake, a really poor old web mistake.
Shrinking 3 to 2
The stated roadmap for MyWeb 2, Bookmarks, and del.icious has Yahoo! moving three main products into two. Two are similar and one is different. Bookmarks is different as it is not traditionally a social tool (not saying it could not or should not be, if done well). MyWeb 2 and del.icio.us are similar tools in that they are both social bookmarking tools. While they are similar the audiences for both are vastly different and the I am really not sure they will or even should mix.
Yahoo! Innovation and Focus on Regular People
Yahoo! in recent years has bought some incredibly innovative companies. There was a whole lot of questions about integrating products that were innovative into the standard Yahoo! offerings. The first of these companies was Flickr, which was a product that was (and is back to being) incredibly innovative. Flickr was vastly different than Yahoo! Photos and many questioned how Yahoo! would integrate them. What Yahoo! did with Flickr is take some of their innovations and integrate them into their mainstream Photo product. What Yahoo! did that was brilliant was leave Flickr as a its own product and let them innovate and test the waters. The Flickr team has grown and they are back to doing insanely brilliant things. Integrating a Flickr into Photos would not have been good for either product. Photos is aimed at regular people who love the product and it serves them well. Flickr is a different beast as it is very social and it is very emergent and it has a fan base that gets that. Flickr has passionate users that love the new features, functionality, and sociality. It has an interface that meets those passionate fans.
Yahoo! has an incredibly large user base (around 70 million people). Its focus is on regular people and serving their needs really well. It is currently going through upgrades to its interfaces for many products, see the Yahoo! homepage for a sample of the great interfaces that are aimed and working really well for regular people and are seemingly being brought to other products, like Bookmarks. These regular people are not the alpha geeks and followers of the innovative products, they want products that work as they expect and they are comfortable with allowing them to do what they want and need. Yahoo! gets this really well and are marrying the innovation and improved design that will work across browsers for these regular people. Yahoo takes time and care ensuring that the products are as smooth, bug-free, and usable as any product or company out there (possibly better than most). They build real products that real people can use.
Innovation and del.icio.us
The big problem I see, which is far worse than the big mistake of moving MyWeb 2 into Bookmarking Beta, is taking an innovative product like del.icio.us and pushing it mainstream. Currently, del.icio.us has about 1 million users. These users are not the normal Yahoo! regular people users, they are ones that will use and enjoy innovative products. The del.icio.us interface is one that many of the regular people understand or like (I have done a decent amount of user testing around this) as it seems very "geeky" and I have heard comments along the lines of "I never liked DOS". This is fine as many of those that use and passionately love del.icio.us enjoy the interface. The interaction design, like the compound tag terms are really foreign to regular people, who more easily understood the comma separated tags with spaces between real words (as that is how most regular people write a string of terms). It has a completely different base of people using it than regular people.
Yahoo! really needs del.icio.us to keep innovating. Joshua Schacter and his team are doing incredible things and they need to keep trying new things and pushing the envelope. Yahoo! really needs a del.icio.us, just like it needs Flickr to remain a distinct product. I have constantly wondered why del.icio.us never took on Yahoo! branding like Flickr or Upcoming, but of late I had thought it was letting del.icio.us innovate and be free, which makes a lot of sense.
Poisoning the Water
What the Yahoo! roadmap seems to be doing is poisoning the water. Bringing del.icio.us into the mainstream will piss off many of those people who are passionate about del.icio.us and its innovation. There were fears of this with Flickr, but Yahoo! proved that leaving Flickr alone was valuable to the company as a whole. Either Yahoo! does not care about the innovation or the passionate users that help provide feedback on social bookmarking to Yahoo! or they don't get what they have. There are two very different sets of people using Yahoo! products and those using del.icio.us. Mixing the two will more likely alienate the passionate del.icio.us users or not be a product that will work well with regular people. Like Flickr and Photos they are two separate groups of people. Yahoo! needs both groups of people to maintain is regular people using Yahoo! and to keep the innovation going.
What Roadmap?
It really makes no sense to poison del.icio.us by pushing it mainstream. So what roadmap? It seems like Yahoo! should have a self supporting tool with del.icio.us with a revenue neutral product (at least revenue neutral) that is ad supported. It needs that quick moving testing and innovation platform (it also needs them for many other products, like calendaring, address book, file storage, etc.) to keep the pipeline filled with good well tested ideas that work with people who are understanding of emergent systems. These good ideas can then flow into testing for the tools for regular people and see if they work there. Yahoo! needs its social bookmarking advocates that love del.icio.us, they can not afford to lose their eyes, interest, or input.
So where does the social bookmarking tool or features for regular people go? Yahoo! needs its new and improved Bookmarking tool and it needs del.icio.us. Changing del.icio.us to go mainstream would be a monumental screw-up. Bringing more sociality into the regular Bookmarking tool, would be a better option. Yahoo! already screwed up by putting content from a their social bookmarking took into a non-social bookmarking tool. The failures of MyWeb 2 were largely no marketing and no iteration to fix the many rough bits.
New ideas explaining and time. Innovation takes time to become integrated into use by regular people. Innovation and understanding of new constructs and concepts get adopted through reading the manual (FAQ or Help), watching a demonstration, reading about it in their normal media streams, watching friends and co-workers, and recommendations of friends. Yahoo! is beginning to take these steps with Bookmarking Beta, they never did this well for MyWeb 2. Bringing the new tools of sociality into the regular Bookmarking tool with highlighting the need for it (triggering the lightbulb moment) and various means of educating would make sense. The social networking tools should become part of the mainstream. Tying these interactions and relating them to known social constructs in peoples lives for sharing information with some groups and not all is something many regular people get. It takes explaining it in terms that regular people understand. Yahoo! does this explaining very well in many other places, why is it so difficult to grasp for social networking?
One avenue for introducing social bookmarking into the mainstream is sharing bookmarks with Yahoo! Groups that they already belong to. Many people have their bridge club in Groups or their kid's soccer (football) team. They have groups of people that they are comfortable sharing links and other information with already. Limiting the new Bookmarks tool to e-mail and SMS is fine, but it seems like there is a ready audience waiting for a well explained tool that would solve technology problems they already have, which is sharing links and bookmarks with people they already know and trust. Yahoo! really needs to use what they do well in various contexts and various audiences that use it.
Yahoo! Bookmarks Beta (or Alpha)
Yahoo! has released it fourth or fifth public bookmarking site, Yahoo! Bookmarks Beta to go along with Yahoo! Bookmarks, del.icio.us, and two versions of Yahoo! MyWeb. This new version seems aimed at being a long needed replacement for the relatively ancient Yahoo! Bookmarks. But, as the post on Better Bookmarks, Better Toolbar this new Bookmarks will do away with Yahoo! MyWeb, as MyWeb will be bundled into del.icio.us. This for me seems really odd as MyWeb2 was much better with the social network than del.icio.us has been. I am going to focus on the new Bookmarking site, because there are some things I like, but there are things that are quite broken and should have been caught with a decent quality assurance test or a decent interaction design heuristic test (some of the things that are broken have been broken in MyWeb 2 for months and it seems to have been imported here). I am normally a big fan of what Yahoo! does, but this release is horribly bumpy and would to be better suited with an Alpha moniker.
Y! Bookmarks Beta Good Things
Yahoo! Bookmarks has been needing an overhaul for years. It is great to see that the six or seven year old product is finally getting attention. Keeping the folder metaphor is good for those that have lived in that realm is a good thing and including tagging as well is a great step forward for this product (oddly, an odd interface for adding tags is used, but that is for later and a rather minor thing compared to the bigger bumps). Having the video for an introduction is a great step forward and would have been a great asset for MyWeb 2 (not so sure it would help adoption with del.icio.us as its interface seems to be a stopping point for regular people using the web) as it would illustrate the lightbulb moment for people to understand why MyWeb 2 is important and useful.
The basic interaction design improvements are very good, with the drag and drop (there are usability/accessibility limitations with drag-and-drop and it would seem like the click-and-stick would have been much better, but that is another long post). The three view options for the bookmarks is helpful too as it provides a nice visual interface with helpful information or ones that are more scannable for people. The layout of the full view is a really nice improvement over the existing MyWeb 2 interface. Another great step forward is the URLs are readable links in the status bar not the hash or unfriendly to human links that were in MyWeb 2.
The URLS overall are well designed in Bookmarks Beta. They can be guessed and edited easily. This is a wonderful change from MyWeb 2.
Bookmark Homepage Oddities
As mentioned above there are some (many) places that need help or some attention to detail in the new Bookmarks. I am using screen captures to help illustrate the points and the images are on Flickr and notations are there. Some of this seems snarky at times, but I am rather shocked that so many details and blatant errors made it public. I am a huge Yahoo fan, for a long list of reasons, but this does get me to question the attention to detail and care that goes into design and development. This was likely hundreds of hours of work by a team and a lot of testing. Just really surprised.
When I first came to the new Bookmarks Home page I was surprised to see all of the content. My expectation was it was going to be my old bookmarks that were included in My Yahoo! pages, which I update and are extensions of bookmarks from 1999. There was no clue on the page that the content had come from MyWeb 2, it took some digging and the "imported delicious" in my tags was the clue. There is no explanation how the bookmarks would be integrated into My Yahoo (I don't want my 2,400 some MyWeb bookmarks in My Yahoo).
The interface on Bookmarks Beta, while nice is difficult to find the sorts and folder/tag view modification as the typeface is very small. The "Sort by:" does not state was the default sort is. The sort is a toggle between date and title (presumably title by alphabetical sort, but my assumptions seem to be off on many things on the site).
The tools bar with view selection, add, edit, move, send, and delete was a little confusing. Some of the tools relate to making a check box selection in the bookmarked items, but that is not clear. While, other tools are not related (view selector and add). I easily understood view, add, edit, and delete were. Move has an icon that indicates moving out of a folder, but I was not clear where a "move" would put the selected items. Was it going to a folder, into My Yahoo sidebar, into del.icio.us, etc. Where was it moving things to? Send had similar problems as one could send by e-mail (should it state e-mail instead?) Why not use the really helpful convention in Yahoo! Local, which is really clear as to where things can be sent? Lastly, I found out that deleting something from Bookmarks removes the item from MyWeb 2 and that should not happen, unless it is made clear in the page that your bookmarks are being pulled from that repository, which Bookmark Beta fails to do.
Edit Bookmarks Broken
The Edit Form page was where I began to think that the Bookmark Beta was more an Alpha. I had first thought it was my using Firefox 2 as a browser, but the same if not worse problems also exist in my Safari browser. The edit bookmark screen is missing labels for the form fields, but it is also missing the existing content. It seems that this could be caused by relying on JavaScripting rather than a server generated page, as this page does not degrade well at all. Additionally the tag fields are empty, where the tag I want to edit should be. If the tag had been in the text box field I would have had a far more painful time separating the multi-term tag into its intended single term tags. Yahoo MyWeb 2 did this really well with a convention called commas. The social bookmarking site, Raw Sugar also uses this common convention and has wonderful affordance for assisting people with their comma separate string of tags. Having text box fields limits the ability for scaling, even if the interface populates the screen with a new text box when the five offered are filled it is still a really clumsy interaction it seems (I know Yahoo! test the living daylights out of their interfaces, which is a great thing, and I would love to know how this interface ended up in the public). Oddly, the one thing missing from this screen is the ability to add this bookmark into a folder. The new Bookmark tool is keeping the folders or is it not? Should not all of the possible interactions be available from the edit view?
Additionally, in a second view of the bookmark edit screen you will see the selected entry is not next to the bookmark edit screen. This likely means that the item being edited, if selected from the lower portion of the page, will not be anywhere near the editing box. There really must be closer. There is a lot of JavaScript being used on the page already, why not hide the items not selected for editing to provide a better proximity for people editing?
Bookmark Search Missing Items or Poor Sort
I tried "Search bookmarks" to get "tech" items. This search is supposed to query tags, titles, descriptions, etc. The resulting set was missing the first item from my default view, which is tagged "tech" is not in this set returned. This set is set for a sort order by date, which should put the item at the top of the returned set. This was something I really wanted to try in search as a similar returned set has been the result in MyWeb 2 and del.icio.us for at least a couple months. The algorithm is horribly off or the the sort is off. The good thing in the Bookmark Beta is it lets you know the sort order (the state in the default result is called out correctly),and lets you select a different sort order. Unfortunately, the search is broken as it is elsewhere. When I ran the search on tags (in the tag view portion of the page) the proper result set was returned with the most recently added item with a "tech" tag right at the top of the date order sort.
The labeling of the page and the type of search is missing from the page. The heading for the results states "Search Results 1-10 or 572", but it does not say what type of search I just ran. A proper heading should be should be "Search Your Bookmarks Results 1-10 of 572".
Add Bookmark Screen
This page has few oddities. The thing that stands out on this add bookmark page is the "My Tags" area. In the folder view of that content object you can drag-and-drop an item into a folder. The convention has been set that there is a drag-and-drop connection between that content object and my bookmarks. But in the tag view you can not drag one of the 20 tags into an empty (or filled) tag text field. The convention that was set, does not extend.
More troubling is the "My Tags" content object has find functionality stating "Type Tag here" in the text field next to the find button. When I have the add screen open I am not expecting that to take me to a new screen. Since the add tag interface does not have type ahead from by tag set, I would think had been hopeful that I could drop in a tag and have other related tags I have used on bookmarks would surface. What does get returned is a tag search result page and my add bookmark screen is blown away. I realize that the convention for what happens with tag search/find is already set, but since the convention for drag-and-drop is broken from folders, other things could be emergent as well.
All My Tags

This page is held back by poor labeling with the "All Tags" label, but it is actually "All My Tags" or some similar convention, as they are not all the tags from all of the users. The tags are semantically well structured in the XHTML as they are an unordered list, which is easy to parse mechanically or for accessibility reasons. The layout of the tags would benefit from having the list be full justified, which would provide a little more space around the tags leading to easier scanning of the page full of tags.
It is odd that the page has a handful of weighted tags, the flat list of tags alphabetically is easier to scan than a weighted tag cloud but these five tags that are most often used seems to be rather odd. I am quite happy not to see a full tag cloud.
Recommended Bookmarks

The Recommended bookmarks tab is the old unuseful default page from MyWeb 2, also known as the Interesting Today page. Ironically, there has never been anything interesting on this MyWeb 2 page. Yahoo Bookmarks has a really good clue as to what I find interesting (or any other person using the tool) or pay attention to, it is our bookmarks. We make an explicit statement each time we bookmark something as to what we have an interest in. This can easily be paired to find people who have bookmarked the same items (this identifies people who may be good sources for new bookmarks to recommend) and what vocabulary they have used to call that bookmark something (if they use the same terms to describe the bookmark it can be easily and most often correctly deduced that we do really have similar interests) and we have a few similar matches like this that person, their terms, and bookmarks can be used to build a list of things I would be interested in. If you take that list and parse it against things I have already bookmarked you will have a killer list of things to recommend me that I will care about. This can be server intensive, but the matching and pairing does not need to be done on the production server for the bookmarks, it can be chugging away in the background and serving up recommendations. This flows directly out of the presentation I have given to Yahoo! Tech Dev and have had many long discussions about at Yahoo! Since this is part of a public presentation I give all of competitors to Yahoo! have the information and most are putting it to use in various ways.
Wrap-up
Some of this seems harsh, but it is a public release by Yahoo! with a Beta moniker thrown on to it. But, much of this information Yahoo! already has as they have asked for the feedback before and received it. Things just don't get fixed. Some of these things are minor, but others are not details, they are big glaring errors. Yahoo has some of the best brains, designers, and developers on the planet and they should be producing products, even with Beta moniker that are not this rough. This is much closer to a Google product that is launched and is really rough around the edges and will likely not get fixed. At least I know with Yahoo things normally get ironed out, or at least they did.
None-the-less this has promise and it should be more accessible to regular people than MyWeb 2, but it seems really silly to throw out MyWeb 2 as it does many things better than del.icio.us, but del.icio.us does many things insanely well. Seeing the two products mixed will be a really tough challenge as it could easily break the fan base in del.icio.us or make a social bookmarking site like MyWeb 2 less approachable by putting a more geek-centric del.icio.us interface on it.
[I have added a follow-up to this focusing on the Yahoo! Roadmap for Social Bookmarking.]
Rebranding and Crossbranding of .net Magazine
From an e-mail chat last week I found out that .net magazine (from the UK) is now on the shelves in the US as "Web Builder". Now that I have this knowledge I found the magazine on my local bookstore shelves with ease. Oddly, when I open the cover it is all ".net".
Rebranding and Crossbranding
In the chat last week I was told the ".net" name had a conflict with a Microsoft product and the magazine is not about the Microsoft product in the slightest, but had a good following before the MS product caught on. Not so surprisingly the ".net" magazine does not have the same confusion in the UK or Europe.
So, the magazine had a choice to not get noticed or rebrand the US version to "Web Builder" and put up with the crossbranding. This is not optimal, as it adds another layer of confusion for those of us that travel and are used to the normal name of the product and look only for that name. Optimally one magazine name would be used for the English language web design and development magazine. If this every happens it will mean breaking a well loved magazine name for the many loving fans of it in the UK and Europe
What is Special About ".net" or "Web Builder"?
Why do I care about this magazine? It is one of the few print magazines about web design and web development. Not only is it one of the few, but it flat out rocks! It takes current Web Standards best practices and makes them easy to grasp. It is explaining all of the solid web development practices and how to not only do them right, but understand if you should be doing them.
I know, you are saying, "but all of this stuff is already on the web!" Yes, this stuff is on the web, but not every web developer lives their life on the web, but most importantly, many of the bosses and managers that will approve this stuff do not read stuff on the web, they still believe in print. Saying the managers need to grow-up and change is short-sighted. One of the best progressive thinkers on technology, Doc Searls is on the web, but he also has a widely read regular column in Linux Journal. But, for me the collection of content in ".net" is some of the best stuff out there. I read it on planes and while I am waiting for a meeting or appointment.
I know the other thing many of you are saying, "but it is only content from UK writers!" Yes, so? The world is really flat and where somebody lives really makes little difference as we are all only a mouse click away from each other. We all have the same design and development problems as we are living with the same browsers and similar people using what we design and build. But, it is also amazing that a country that is a percentage the size of the US has many more killer web designers and developers than the US. There is some killer stuff going on in the UK on the web design and development front. There is great thought, consideration, and research that goes into design and development in the UK and Europe, in the US it is lets try it and see if it works or breaks (this is good too and has its place). It is out of the great thought and consideration that the teaching and guiding can flow. It also leads to killer products. Looking at the Yahoo Europe implementations of microformats rather far and wide in their products is telling, when it has happened far slower in the Yahoo US main products.
Now I am just hoping that ".net" will expand their writing to include a broader English speaking base. There is some killer talent in the US, but as my recent trip to Australia showed there is also killer talent there too. Strong writing skills in English and great talent would make for a great global magazine. It could also make it easier to find on my local bookstore shelves (hopefully for a bit cheaper too).
The Excellence of Accessibilty Presentations
One of the people I have met this past year and come to know better through traveling to and from Web Directions 2006 and hanging with at d.construct is Derek Featherstone. His presentations on the subject of accessibility are the best I have ever seen. The past year I have not had the opportunity to think, talk about, or develop around the subject of web accessibility (I had thought of this as a good thing, but I will explain that shortly) other than as an extension of semantically well structured information, which most conference I have been speaking at are related to in one form or another.
Derek is one of the first presenters that digs deep into accessibility beyond a set of rules, but also looks at usability for those with accessibility needs as the baseline for building great sites that work for all. He frames his presentations not as accessibility is for "them", but as it is for all of us. This focus is astoundingly refreshing and rare.
Derek digs into how JavaScript and Ajax, if done well (did you read that caveat, "done well"?), can actually improve accessibility. In his presentation Derek walks through how to think about interfaces, both rich and static, and improve upon them for everybody. Much of this is basic usability that is missed by many, but the rich interface elements are something I have not heard before from somebody talking about accessibility.
Lastly, Derek's presentation style is light and easy, which bring many people who are put off my accessibility into listening and learning. It is a great thing to watch people gain interest as he presents about a subject they did not care about. But even better is when they start talking about they now have a good framework to think about and approach accessibility does the power of Derek's presentation style and deep knowledge make a the subject come to life.
Granted I have not been reading much around accessibility for the past year, although I have had some great discussions about it with Matt May and Christian Heilmann at various points this year along the lines of rich interfaces and caring about those with accessibility needs. My lack of interest is not because I do not care about accessibility, but I have been burned out from dealing with the politics of accessibility in the U.S. Federal Government. I enjoyed working with the webmasters on the government side, but outside of that it was really painful. Most people would go out of their way to make unusable, poorly structured, semantically incorrect, let alone unaccessible sites just because they were told to make a site accessible. The long battles, even with those charged with caring and ensuring accessibility, made me very happy not to have to deal with accessibility for quite a while. Since you can get about 90 percent of the way to accessibility with just semantically well structured XHTML mark-up, which is the mark of any decent web developer, I have not considered the subject much beyond that in over a year.
Derek's presentations and our long discussions regarding semantically well structured information as the basis for everything that has improved the web in the past few years, brought me back to enjoying the subject of accessibility. In saying this I am more sure now that those who wrote the U.S. Section 508 regulations and those on the Access Board have failed those who needed real accessibility so they could partake in this freedom of information we embrace.
Trip and d.construct Wrap-up
I am back home from the d.construct trip, which included London and Brighton. The trip was very enjoyable, the d.construct conference is a pure winner, and I met fantastic people that keep my passion for the web alive.
d.construct
The d.construct conference had Jeff Barr from Amazon talking about Amazon Web Services, Paul Hammond and Simon Willison discussing Yahoo and its creation and use of web services for internal and external uses, Jeremy Keith discussing the Joy of the API, Aral Balkan presenting the use of Adobe Flex for web services, Derek Featherstone discussing accessibility for Javascript and Ajax and how they can hurt and help the web for those with disabilities, myself (Thomas) discussing tagging that works, and Jeff Veen pulling the day together with designing the complete user experience.
Jeff Barr provided not only a good overview of the Amazon offerings for developers, but his presentation kept me interested (the previous 2 times my mind wandered) and I got some new things out of it (like the S3 Organizer extension for Firefox.
Jeremy was his usual great presenting form (unfortunately a call from home caused me to miss the some of the middle, but he kept things going well and I heard after that many people learned something from the session, which they thought they knew it all already.
Paul and Simon did a wonderful tag team approach on what Yahoo is up to and how they "eat their own dog food" and how the Yahoo Local uses microformats (Wahoo!).
Aral was somebody I did not know before d.construct, but I really enjoyed getting to know him as well as his high energy presentation style and mastery of the content that showed Flash/Flex 2.0 are fluent in Web 2.0 rich interfaces for web services.
Derek was fantastic as he took a dry subject (accessibility) and brought it life, he also made me miss the world of accessibility by talking about how JavaScript and Ajax can actually improve the accessibility of a site (if the developer knows what they are doing - this is not an easy area to tread) and made it logical and relatively easy to grasp.
I can not comment on my own presentation, other than the many people what sought me out to express appreciation, and to ask questions (many questions about spamming, which is difficult if the tagging system is built well). I was also asked if I had somebody explain the term dogging (forgetting there was a rather bawdy use of the term in British culture and using the term as those people who are dog lovers - this lead to very heavy laughter). Given the odd technical problems at the beginning of the presentation (mouse not clicking) things went alright about 5 minutes or so in.
Lastly, the man I never want to follow when giving a presentation, Jeff Veen rocked the house with his easy style and lively interaction with his slides.
I am really wanting to hear much more from Aral and Derek now that I have heard them speak. I am looking forward to seeing their slides up and their podcasts, both should be posted on the d.construct schedule page.
London Stays
The trip also included an overnight stay in London on the front and back end of the conference. Through an on-line resource I had two last minute rooms booked at Best Western Premiers that were great rooms in well appointed hotels. The hotels even had free WiFi (yes, free in Europe is a huge savings), which was my main reason for staying at these hotels I knew nothing about. I really like both locations, one near Earls Court Tube Station and the other Charing Cross Road and SoHo. The rooms were well under 200 U.S. dollars, which is a rarity in central London. I think I have a new place to track down then next time I visit London.
London People & Places
I had a few impromptu meetings in London and an accidental chat. When I first got in I was able to clean-up and go meet friends Tom and Simon for lunch at China Experience. We had good conversations about the state of many things web. Then Tom showed me Cyber Candy, which I have been following online. I was then off to Neal's Yard Dairy to pick-up some Stinking Bishop (quite excellent), Oggleshield, and Berkswell. I then did a pilgrimage to Muji to stock up on pens and all the while using Yahoo Messanger in a mobile browser (a very painful way to communicate, as there is no alert for return messages and when moving the web connection seems to need resetting often).
That evening I met up with Eric Miraglia for a great chat and dinner, then included Christian Heillmann (who has a great new book (from my initial read) on Beginning JavaSctipt with DOM Scripting and Ajax) in our evening. The discussions were wonderful and it was a really good way to find people of similar minds and interests.
On my last day in London I ended up running into Ben Hammersley as he was waiting for a dinner meeting. It was great to meet Ben in person and have a good brief chat. Somehow when walking down the street and seeing a man in a black utilikilt, with short hair, and intently using his mobile there are a short list of possibilities who this may be.
Food
My trip I had a few full English breakfasts, including one in Brighton at 3:30am (using the term gut buster), which was my first full meal of the day. The breakfast at the Blanche House (the name of the hotel never stuck in my head and the keys just had their logo on them, so getting back to the hotel was a wee bit more challenging than normal) was quite good, particularly the scrambled eggs wrapped in smoked Scottish salmon. The food the first night in Brighton at the Seven Dials was fantastic and a great treat. Sunday brunch at SOHo Social in Brighton was quite good and needed to bring me back from another late night chatting, but the fish cakes were outstanding. The last evening in London I stopped in at Hamburger Union for a really good burger with rashers bacon. The burgers are made with only natural fed, grass-reared additive free beef. This is not only eco-friendly, but really tasty. I wish there were a Hamburger Union near where I work as I would make use of it regularly.
Too Short a Visit
As it is with nearly every trip this year, the time was too short and the people I met were fantastic. I really met some interesting and bright people while in Brighton and I really look forward to keeping in touch as well as seeing them again.
Quick and Intense Usability Interations
Last evening I was chatting with Nate Bolt who mentioned he had done some usability studies with a large client who brought their developers with them to watch the studies live. He mentioned that the developers would go back every evening an code the site/tools they were testing and then test the new site the next day. Others that were chatting thought this was nuts, which a year or two ago I would have thought the same.
A couple years ago I started talking to people doing development and usability sprints that start-ups, open source projects, and small development teams had been trying.
Usabilty Test Built into Sprints and Hack Days
In the past year I have talked with at least three teams working on projects that are doing one-day to four-day sprints or hack days to gather information from usability tests regarding how people use or are unable to use their products as well as collect wish-lists of desired product improvements. In the multi-day sessions some of the identified front-end tweaks and quick development tasks are knocked out, tested with people who use the product, and iterated a few times. The instant feedback on tweaks is very helpful and allows for rapid product development.
Quick Fixes and Long Term Tasks
The time between the intense sessions are used to build the deeper and more wide spread changes. These release cycles are now quicker and more on target. One project also has done usability sessions in addition to the intense sessions to catch some of the more subtle issues (with people new to the sites/tools as well as those with long term use).
Listening and Fixing Before Their Eyes
I definitely see the strong advantages of the intense sessions mixed with the usual longer term development. Finally it seems a broad section of the development world is finally learning that the best way to build out stuff is to sit with the people that use it, see their pain and frustration. But, even better is fixing that pain overnight. These intense iterations build positive feedback for the developers and designers on the projects, the business owners seeing quick improvements, and the people who want and need to use the products. The people using the tools will most likely go away and become evangelists for the products as the developers and designers not only listened to their needs, but fixed it so it worked better for them right before their eyes.
What It Takes
This approach not only takes solid developers and designers, but smart project managers that can assess (more accurately triage) the needed fixes, prioritize the short term and long term solutions, assign and manage these quick solutions. Smart and passionate people is the key to these solutions as well as nimble teams.
Small Projects Get It, Will Enterprise?
I am wondering if the quick intense iterations will be where we are going. I definitely see it for the small and nimble. But, can enterprise iterate this quickly? Or will the hands that need to bless the iterations have to stay involved with meeting cycles that will slow down the progress?
I have been impressed with the discussions around Yahoo! Hack Days and Yahoo is a large enterprise with many meetings, but they "get it" (or are in the process of internalizing "getting it"). I think Yahoo is showing enterprise can get there. But getting there will take faith that the enterprise has hired well and have the right people working for (and with) them and the right managers in place that trust their developers and designers, but most importantly trust their customers and people that use, as well as want to use, what they produce.
Platial Turning it Up
A few months ago a couple of friends pointed me to Platial a social geo-annatation site that is build on top of the Google map API. As luck would have it I met up with the creators and developers of Platial while in Amsterdam at XTech 2006. I was in deep "just got off an overnight flight" syndrome, but really enjoyed talking with them non-the-less.
Platial is headquartered in Portland, Oregon and on my recent trip I stopped in to say hello. Not only do they have killer developers and staff, an incredible workspace, but great things are coming to Platial. I left even more impressed with the tool and the direction it is heading than I was prior.
If you have not tried it, head on over and give it a try. Remember to keep coming back as they have more killer stuff in the pipeline.
They are One
Congratulations to Clearleft on their one year anniversary. This is one of "the" web shops to work with. You should be so lucky to be on their client list.
Technosocial Architect
Those of you that know me well know I am not a fan of being labeled, yes it is rather ironic. A large part of this is a breadth of focus in the lens, from which I view the world. I am deeply interested in how people interact, how people use technology, and the role of information in this equation. My main interest is information and information use, when to people want it and need it, how people acquire it. I am utter fascinated by how technology plays in this mix and how important design is. I look at technology as any mediated form of communication, other than face-to-face communication. The quest began in the technology "quot;paper age" looking at layout and design of text and images on the printed page and the actual and latent messages that were portrayed in this medium. I also dove into television and video as well as computer aided visualizations of data (Tufte was required reading in quantitative methods class (stats) in the early '90s in grad school).
Well, this life long interest only continued when I started digging into the web and online services in the early 90s. But, as my interest turned professional from hobby and grad student my training in quantitative and qualitative (ethnographic) research were used not for public policy, but for understanding what people wanted to do with technology or wished it would work, but more importantly how people wanted to use information in their life.
Basis for Digital Design and Development
As I have waded through web development and design (and its various labels). Most everything I have done is still based on the undergrad training in communication theory and organizational communication. Understanding semantics, rhetoric, layout, design, cogsci, media studies, cultural anthropology, etc. all pay a very important part in how I approach everything. It is a multi-disciplinary approach. In the mid-80s I had figured everybody would be using computers and very adept by the time I finished undergrad, that I thought it was a waste to study computer science as it was going to be like typing and it programming was going to be just like typing, in that everybody was going to be doing (um, a wee bit off on that, but what did I know I was just 18).
People Using Information in Their Life
The one thing that was of deep interest then as it is now, is how people use information in their life and want and need to use information in their life. To many people technology gets in the way of their desired ease of use of information. Those of us who design and build in the digital space spend much of our time looking at how to make our sites and applications easier for people to use.
Do you see the gap?
The gap is huge!
We (as designers and developers) focus on making our technology easy to use and providing a good experience in the domain we control.
People want to use the information when they need it, which is quite often outside the domains we as designers and developers control.
Designing for Information Use and Reuse
Part of what I have been doing in the past few years is looking at the interaction between people and information. With technology we have focussed on findability. Great and good. But, we are failing users on what they do with that information and what they want to do with that information. One question I continually ask people (particularly ones I do not know) is how are you going to use that information. When they are reading or scanning information (paper or digital it does not matter) I ask what is important to them in what is before them. Most often they point to a few things on the page that have different uses (an article referenced in the text, an advertisement for a sale, a quote they really like, etc.). But, the thing that nearly everything that they find important is it has a use beyond what they are reading. They want to read the article that is referenced, they want the date and location for the sale (online address or physical address and date and times), they want to put the quote in a presentation or paper they are writing.
End-to-end is Not the Solution
Many companies try to focus on the end-to-end solution. Think Microsoft or Google and their aim to solve the finding, retaining, using, and reusing of that information all within their products. Currently, the companies are working toward the web as the common interface, but regular people do not live their life on the web, they live it in the physical world. They may have a need for an end-to-end solution, but those have yet to become fully usable. People want to use the tools and technologies that work best for them in various contexts. As designers and developers we can not control that use, but we can make our information more usable and reusable. We have to think of the information as the focal point. We have to think of people actually connecting with other people (that is individuals not crowds) and start to value that person to person interaction and sharing on a massive scale.
Our information and its wrappers must be agnostic, but structured and prepared in a manner that is usable in the forms and applications that people actually use. The information (content to some) is the queen and the people are the king and the marriage of the two of them will continue the reign of informed people. This puts technology and the medium as the serf and workers in that kingdom. Technology and the medium is only the platform for information use and reuse of the information that is in people's lives. That platform, like the foundation of a house or any building must not be noticed and must serve its purpose. It must be simple to get the information and reuse it.
Technology and Design are Secondary
Those of us that live and breathe design and development have to realize what we build is only secondary to what people want. It is the information that is important to regular people. We are only building the system and medium. We are the car and the road that take people to Yosemite where they take pictures, build memories, bond with their travel companions, etc. What is created from this trip to Yosemite will last much longer than the car or road they used to get them to the destination. We only build the conduit. We have to understand that relationship. What we build is transient and will be gone, but what people find and discover in the information they find in what we build must last and live beyond what we control and can build or design. We must focus on what people find and want to use and reuse while they are using what we are designing and building for them.
Information as Building Blocks
All of what is being described is people finding and using information that an other person created and use it in their life. This is communication. It is a social activity. This focus is on building social interactions where information is gathered and used in other contexts. Information use and reuse is part of the human social interaction. This social component with two people or more interacting to communicate must be the focus. We must focus on how that interaction shapes other human interactions or reuses of that information garnered in the communication with an other and ease that interaction. If you are still reading (hello) you probably have something to do with design or development of technology that mediates this communication. We are building social tools in which what is communicated will most likely have a desired use for the people interacting outside of what we have built or designed.
Technosocial Architects
People who understand the social interactions between people and the technologies they use to mediate the interactions need to understand the focus is on the social interactions between people and the relationship that technology plays. It is in a sense being a technosocial architect. I ran across the word technosocial in the writings of Mimi Ito, Howard Rheingold, and Bruce Sterling. It always resonates when I hear technosocial. Social beings communicate and inherent in the term communication is information.
Focus on People, Medium, and Use
Just above you see that I referenced three people (Mimi, Howard, and Bruce) as people who used a term that seems to express how I believe I look at the work I do. It is people, more importantly, it is individuals that I can point to that I trust and listen to and are my social interpreters of the world around me. These people are filters for understanding one facet of the world around me. People have many facets to their life and they have various people (sometimes a collective of people, as in a magazine or newspaper) who are their filters for that facet of their life. There are people we listen to for food recommendations, most likely are different from those that provide entertainment, technology, clothing, auto, child care, house maintenance, finance, etc. We have distinct people we learn to trust over time to provide or reinforce the information we have found or created out of use and reuse of what we have interacted with in our life.
Looking at many of the tools available today there is a focus on the crowd in most social tools on the web. Many regular people I talk to do not find value in that crowd. They want to be able to find individual voices easily that they can learn to trust. Just like I have three people I can point to people in social software environments look at the identity (screen name many times) as their touch point. I really like Ask MetaFilter as a social group "question and answer" tool. Why? Mostly because there are screen names that I have grown to know and trust from years of reading MetaFilter. The medium is an environment that exposes identity (identity is cloaked with a screen name and can be exposed if the person so decides in their profile). People are important to people. In digitally mediated social environments the identity is that point of reference that is a surrogate for name in physical space. In print the name of the writer is important as a means to find or avoid other pieces or works. We do the same in movies, television news, television shows, online videos, podcasts, blogs, etc. the list does not end.
Our social mediums need to keep this identity and surface the identity to build trust. People use identity as gatekeepers in a world of information overload. When I look at Yahoo! Answers and Yahoo! MyWeb (my absolute favorite social bookmarking tool) I get dumped into the ocean of identities that I do not recognize. People are looking for familiarity, particularly familiarity of people (or their surrogate identity). In MyWeb I have a community (unfortunately not one that is faceted) where I trust identities (through a series of past experience) as filters for information in the digital world around us, but I am not placed in this friendly environment, but put in an environment where I find almost nothing I value presented to me. This is the way Yahoo! Answers works as well, but it does not seem like there is the ability to track people who ask or answer questions that a person would find value in.
The tools we use (as well as design and build) must understand the value of person and identity as information filters. The use of information in our lives is one explicit expression of our interest in that subject, the person who created the information, or the source what housed that information. Use and reuse of information is something we need to be able to track to better serve people (this gets in to the area of digital rights management, which usually harms information use more than it enables it, but that is another long essay). The medium needs to understand people and their social interaction people have with the information and the people who create the information and the desired use. This use goes well beyond what we create and develop. Use requires us understanding we need to let go of control of the information so it may be used as people need.
Need for Technosocial Architects
Looking at the digital tools we have around us: websites, social computing services and tools (social networking sites, wikis, blogs, mobile interaction, etc.), portals, intranets, mobile information access, search, recommendation services, personals, shopping, commerce, etc. and each of these is a social communication tool that is based on technology. Each of these has uses for the information beyond the digital walls of their service. Each of these has people who are interacting with other people through digital technology mediation. This goes beyond information architecture, user experience design, interaction design, application development, engineering, etc. It has needs that are more holistic (man I have been trying to avoid that word) and broad as well as deep. It is a need for understanding what is central to human social interactions. It is a need for understanding the technical and digital impact our tools and services have in mediating the social interaction between people. It is a need for understanding how to tie all of this together to best serve people and their need for information that matters to them when they want it and need it.
Still Thowing Out the User
There is much buzz about getting rid of the term user these days. Don Norman talks about using the term person, PeterMe picks up on this, and others are not happy with the term "user generated content", like Jon Udell who would like to use "reader-created content", Robert Scoble who believes it is screwing the Long Tail, and Jeff Veen who talks about people writing the web. I have to agree, well I did more than agree.
Throwing Out the User
More than a year ago I got fed up with the user and wrote about saying Good Bye to the User. In years prior I have watched people having painful moments in usability testing. These people felt sorry that they could not easily use what we built and designed. They had empathy for us, but we just lumped them in the category "user". User is not a good word, it is a dirty four letter word. Far too many times designers and developers blame the "user". We tried to solve the user's problems. It was not the problem of the user, it is a real person's pain.
As designers and developers we know deep inside that technology is complex and difficult to use, but we often forget it. The term user has stood in the way. But using person or people, we can see the pain and feel the pain. Many of us consider ourselves users and we do not have these problems, but we are über users, who at one point had the same pain and struggles.
People are different, we have learned this early in life. We can take some characteristics and lump groups of people together, but there are so many important facets that that make us who we are it is difficult to lump people across facets. The only way to lump people separating ourselves as designers and developers out of the equation and putting the focus on regular people. If you are reading this, you are most likely not a regular person who has problems using technology as they wish or need to. It is real people with pain. It is real people who worry about privacy, identity issues, easy access to needed info for themselves and some easy access for some people they know but impossible access for most everybody else, etc. But, the problem with this is these real people do not know this is what they want or need until they do not have it an it becomes painfully aware to them.
Generating Content
I like approach of Jeff Veen and Jon Udell who focus on person-created content. In a hip world of popularity engines like Digg where the masses or crowd bubble up information we forget that most people listen and trust individual voices. We have done this with mass media for years. We trusted certain news anchors and certain reporters on television. We read and trusted certain journalist, columnists, reviewers, and opinion writers. This trust was not always to the wrapper of the communication, like a paper or the whole network news offerings. It comes down to people trusting people. Individuals trusting individuals.
Those of us who have been blogging for nearly a dog year or more understand it is about the individual. We are individual people creating content. We are individual voices. We may be part of a collective at times, but people trust us the person and over time may come to trust people we trust, whom our readers do not know and do not trust yet.
Bringing People Together with People
So what do we need in these social computing environments? We need to see the person. We need to have the ability to find the person similar to us. We want to find those whom are near in thought to us. This may not be the most prolific person on a subject or the most linked to, but their interests match our interests and or vocabularies are similar (often a very good sign of commonality). In the popularity engines we should be able to find those who have "liked" or "dug" things similar to that which we have the same feelings and/or interests.
Doing Without the User
The past year I have been asked many times how easy it is not to use the term user. Well, at first it was hard to transition because it was a term I just used with out thinking. It was also hard because many of my clients and customers I worked with liked using the term user (they also have had many of the problems that come with the term user). But, over time I have a few clients using people and the empathy for the pain that the people who use their products feel is felt and it is reflected in their work products.
One benefit that came from focussing on the person and not the user has been being able to easily see that people have different desired uses and reuses for the data, information, media, etc. that the products I am working on or my clients are developing. I can see complexity more easily focussing on people than I could the user. Patterns are also easier to see looking at the individual people as the patterns resemble flows and not steps. When we focus on the user we try to fit what we built to pre-determined patterns, which we have broken into steps. We can determine steps that are roughly common points of task changing in the flows (changing from seeking to recognizing in a search task it part of an iterative flow, which we can determine is a separate step, but whether that leads to the next step or iterates a few more times is part of a person's information workflow.
Steps are Broken
One of the steps that is getting broken by real people is that around process. People use tools in different ways. For years we have been looking at a publish and subscribe model. But, that is missing a step or two when we look at the flows. People create content and publish it, right? Well, not quite. We are seeing people skipping the publish and pushing it straight to syndication. There is no single point where it is published and has a definable address. The old publish and subscribe model assumed publishing would syndicate the information (RSS, ATOM, RDF, etc.). But, we all know that syndication has been a really slow adoption for traditional media. It was many years after those of us blogging and syndicating information saw traditional media pick-up on the trend. But, traditional media has always understood going straight to syndication with columnists, radio, and television shows. It was the blogging community and personal content creators that were late to understanding we could just syndicate the information and skip the publishing step in the flow.
Getting to Watching People and Flows
How do we not miss things? We watch people and we need to pay attention to their flows. Each individual, each of their desires, each of their different personal information workflows, across each of their current devices, and how they wish they could have what we build inflict less pain on their person.
The person should not feel empathy for those of us building and designing tools and systems, we must feel the person's and peoples pain and feel empathy for them. Where have we stood in their way of their desired flow? Now we must get out of the way, get rid of the user, and focus on people to build and design more effectively.
System One Takes Information Workflow to a New Level
While at Microlearning Conference 2006 Bruno and Tom demonstrated their System One product. This has to be one of the best knowledge/information tools that I have seen in years. They completely understand simplicity and interaction design and have used it to create an information capture and social software tool for the enterprise. Bruno pointed me to a System One overview screen capture (you do not have to login to get started) that features some of the great elements in System One.
One of the brilliant aspects of System One is their marketing of the product. While it has easily usable wiki elements, heavy AJAX, live search, etc. they do not market these buzzwords, they market the ease of use to capture information (which can become knowledge) and the ease of finding information. The simplicity of the interface and interaction make it one of the best knowledge management tools available. Most knowledge management tools fall down on the information entry perspective. Building tools that are part of your workflow, inclusion of information from those that do not feed the KM tool, is essential and System One is the first tools that I have seen that understands this an delivers a product that proves they get it.
The enterprise social software market is one that is waiting to take off, as there is a very large latent need (that has been repressed by poor tools in the past). System One tool is quite smart as they have built e-mail search, file access, Google live file search (you type in the wiki (you do not need to know it is a wiki) and the terms used are searched in Google to deliver a rather nice contextual search. This built in search solves the Google complexity of building solid narrow search queries, but the person using the system just needs to have the capability to enter information into the screen.
Those of us that are geeks find Google queries a breeze, but regular people do not find it easy to tease out the deeply buried gems of information hidden in Google. Surfacing people who are considered experts, or atleast connectors to experts on subjects is part of the System One tool as well and this is an insanely difficult task in an enterprise.
My only wish was that I worked in an organization that would be large enough to use this tool, or there was a personal version I could use to capture and surface my own information when I am working.
You may recognize System One as the developer of retreivr, the Flickr interactive tool that allows you to draw a simple picture and their tool will find related photos in Flickr based on the drawing's pattern and colors. It is a brilliant tool, but not as smart as their main product.
An Overview of the Local InfoCloud is Available
I have finally posted a write-up on Exposing the Local InfoCloud, which explains the attributes and components that comprise the Local InfoCloud. This is a write-up of an explanation that has been bubbling for a couple years and I finally put into a presentation last Fall for Design Engaged. The Local InfoCloud include resources that are familiar to us and can often be the social software elements with which we interact as trusted resources.
During a recent symposium on social software (I attended virtually) there was much grumbling around the term "community" and when I stated I was going to try and redact that term from my usage, I was quickly asked what I was going to replace it with. Community is broadly used and for most of my uses the components in the Local InfoCloud are more distinct pointers to what people can mean when they discuss community. The components are also can help us describe the human and digital resources that bring data, information, and media objects closer to us.
When I have chatted with people about the attributes and components in the past it leads to more questions and wonderful discussions. The point of this piece is to clarify the framework for the Local InfoCloud and capture discussion. I have incorporated the feedback from chats I have had, where it was convincing, relevant, and I was happy with how it jelled. I am looking for more feedback and discussion, which is part of the reason it is posted at the Personal InfoCloud (comments and trackback capabilities are available, but moderated, there).
TechCrunch Party in Seattle
I am in Seattle next week for a few days and while there I will be heading to the TechCrunch Party on May 31st. It looks like a good event, as most TechCrunch events go. If you are around you will need to sign-up on the wiki to attend.
Developing the Web for Whom?
Google Web Developer Toolkit for the Closed Web
Andrew in his post "Reading user interface libraries" brings in elements of yesterday's discussion on The Battle to Build the Personal InfoCloud. Andrew brings up something in his post regarding Google and their Google Web Developer Toolkit (GWT. He points out it is in Java and most of the personal web (or new web) is built in PHP, Ruby [(including Ruby on Rails), Python, and even Perl].
When GWT was launched I was at XTech in Amsterdam and much of the response was confusion as to why it was in Java and not something more widely used. It seems that by choosing Java for developing GWT it is aiming at those behind the firewall. There is still much development on the Intranet done in Java (as well as .Net). This environment needs help integrating rich interaction into their applications. The odd part is many Intranets are also user-experience challenged as well, which is not one of Google's public fortés.
Two Tribes: Inter and Intra
This whole process made me come back to the two differing worlds of Internet and Intranet. On the Internet the web is built largely with Open Source tools for many of the big services (Yahoo, Google, EBay, etc.) and nearly all of the smaller services are Open Source (the cost for hosting is much much lower). The Open Source community is also iterating their solutions insanely fast to build frameworks (Ruby on Rails, etc.) to meet ease of development needs. These sites also build for all operating systems and aim to work in all modern browsers.
On the Intranet the solutions are many times more likely to be Java or .Net as their is "corporate" support for these tools and training is easy to find and there is a phone number to get help from. The development is often for a narrower set of operating systems and browsers, which can be relatively easy to define in a closed environment. The Google solution seems to work well for this environment, but it seems that early reaction to its release in the personal web it fell very flat.
13 Reasons
A posting about Top 13 reasons to CONSIDER the Microsoft platform for Web 2.0 development and its response, "Top 13 reasons NOT to consider the Microsoft platform for Web 2.0 development" [which is on a .Net created site] had me thinking about these institutional solutions (Java and .Net) in an openly developed personal web. The institutional solutions seem like they MUST embrace the open solutions or work seamlessly with them. Take any one of the technical solutions brought up in the Microsoft list (not including Ray Ozzie or Robert Scoble as technical solutions) and think about how it would fit into personal site development or a Web 2.0 developed site. I am not so sure that in the current state of the MS tools they could easily drop in with out converting to the whole suite. Would the Visual .Net include a Python, PHP, Ruby, Ruby On Rails, or Perl plug-in?The Atlas solution is one option in now hundreds of Ajax frameworks. To get use the tools must had more value (not more cost or effort) and embrace what is known (frogs are happy in warm water, but will not enter hot water). Does Atlas work on all browsers? Do I or any Internet facing website developer want to fail for some part of their audience that are using modern browsers?
The Web is Open
The web is about being browser agnostic and OS agnostic. The web makes the OS on the machine irrelevant. The web is about information, media, data, content, and digital objects. The tools that allow us to do things with these elements are increasingly open and web-based and/or personal machine-based.
Build Upon Open Data and Open Access
The web is moving to making the content elements (including the microconent elements) open for use beyond the site. Look at the Amazon Web Services (AWS) and the open APIs in the Yahoo Developer Network. Both of these companies openly ease community access and use of their content and services. This draws people into Amazon and Yahoo media and properties. What programming and scripting languages are required to use these services? Any that the developer wants.. That is right, unlike Google pushing Java to use their solution, Amazon and Yahoo get it, it is up to the developer to use what is best for them. What browsers do the Amazon and Yahoo solutions work in? All browsers.
I have been watching Microsoft Live since I went to Search Champs as they were making sounds that they got it too. The Live Clipboard [TechCrunch review] that Ray Ozzie gave at O'Reilly ETech is being developed in an open community (including Microsoft) for the whole of the web to use. This is being done for use in all browsers, on all operating systems, for all applications, etc. It is open. This seems to show some understanding of the web that Microsoft has not exhibited before. For Microsoft to become relevant, get in the open web game, and stay in the game they must embrace this approach. I am never sure that Google gets this and there are times where I am not sure Yahoo fully gets it either (a "media company" that does not support Mac, which the Mac is comprised of a heavily media-centric community and use and consume media at a much higher rate than the supported community and the Mac community is where many of the trend setters are in the blogging community - just take a look around at SXSW Interactive or most any other web conference these days (even XTech had one third of the users on Mac).
Still an Open Playing Field
There is an open playing field for the company that truly gets it and focusses on the person and their needs. This playing field is behind firewalls on Intranet and out in the open Internet. It is increasingly all one space and it continues to be increasingly open.
Expansive Web 2.0 Conference List
Eric Weaver has put together a killer list of upcoming conferences for Web 2.0 related subjects. Now to get this list in Upcoming.
The Battle to Build the Personal InfoCloud
Over at Personal InfoCloud I posted The Future is Now for Information Access, which was triggered by an interview with Steve Ballmer (Microsoft) about the future of technology and information. I do not see his future 10 years out, but today. I see the technology in the pockets of people today. People are frustrated with the information not being easily accessed and use and reuse not being as simple as it should. Much of this is happening because of the structure of the information.
Personal InfoCloud is the Focus
One thing that struck me from the article, which I did not write about, was the focus on Google. Personally I find it odd as Yahoo is sitting on the content and the structure for more than 90 percent of what is needed to pull off the Personal InfoCloud. Yahoo is beginning to execute and open access to their data in proper structures. Ballmer lays out a nearly exact scenario for aggregating one's own information and putting it in our lives to the one I have been presenting the last few years. Yahoo has the components in place today to build on top of and make it happen. Google is not only lacking the structure, but they are not executing well on their products they produce. Google does the technically cool beta, but does not iterate and fix the beta nor are they connecting the dots. Yahoo on the other hand is iterating and connecting (they need to focus on this with more interest, passion, and coordinated direction).
The Real Battle
I really do not see the battle as being between Google and the others. The real battle is between Yahoo and Microsoft. Why? Both focus on the person and that person's use and need for information in their life and with their context. Information needs to be aggregated (My Yahoo is a great start, but it goes deeper and broader) and filtered based on interest and need. We are living in a flood of information that has crossed into information pollution territory. We need to remove the wretched stench of information to get back the sweet smell of information. We need to pull together our own creations across all of the places we create content. We need to attract information from others whom have similar interests, frameworks, and values (intellectual, social, political, technological, etc.). The only foundation piece Yahoo is missing is deep storage for each person's own information, files, and media.
Microsoft Live Gets It
Microsoft has the same focus on the person. I have become intrigued with the Microsoft Live properties (although still have a large disconnect with their operating systems and much of their software). Live is aiming where Yahoo is sitting and beyond. Microsoft has the cash and the interest to assemble the pieces and people to get there. Live could get there quickly. Looking at the Live products I saw in January at Search Champs with some in relatively early states and what was launched a few months later, the are iterating quickly and solidly based on what real people want and need in their lives (not the alpha geeks, which Google seems to target). Live products are not done and the teams are intact and the features and connections between the components are growing. They are leaving Google in the dust.
Can Yahoo Stay Ahead of Microsoft?
The question for Yahoo is can they keep up and keep ahead of Microsoft? Google has the focus in search as of today (not for me as the combination of Yahoo! MyWeb 2.0 and Yahoo! Search combined blow away anything that Google has done or seemingly can do. Yahoo! does need to greatly improve the simplicity, ease of use, and payoff (it takes a while for the insanely great value of MyWeb 2.0 to kick in and that needs to come much earlier in the use phase for regular people).
I am seeing Microsoft assembling teams of smart passionate people who want to build a killer web for regular people. It seems Ray Ozzie was the turn around for this and is part of the draw for many heading to work on Live products. The competition for minds of people who get it puts Live in competition with Google, Yahoo, EBay, Amazon, and even Apple. I am seeing Live getting the people in that they need. Recently (last week) Microsoft even started changing their benefits and employee review practices to better compete and keep people. It seems that they are quite serious and want to make it happen now.
Yahoo Under Valued
Recent comments about Yahoo being under valued in the long term are dead on in my view. A recent Economist article about Google pointed out how poorly they execute on everything but their core service (search). This waking up starts to bring a proper focus on what those of us who look at regular people and their needs from information and media in their lives have been seeing, Yahoo gets it and is sitting on a gold mine. Yahoo has to realize that Microsoft sees the same thing and is pushing hard with a proper focus and passion to get there as well.
Google Overvalued
What does this mean for Google? I am not sure. Google is a technology company that is focussed on some hard problems, but it has to focus on solutions that people can use. Google aims for simple interfaces, but does not provide simple solutions or leaves out part of the solutions to keep it simple. They need a person-centered approach to their products. The addition of Jeff Veen and his Measure Map team should help, if they listen. Google has some excellent designers who are focussed on usable design for the people, but it seems that the technology is still king. That needs to change for Google to stay in the game.
More XTech 2006
I have had a little time to sit back and think about XTech I am quite impressed with the conference. The caliber of presenter and the quality of their presentations was some of the best of any I have been to in a while. The presentations got beneath the surface level of the subjects and provided insight that I had not run across elsewhere.
The conference focus on browser, open data (XML), and high level presentations was a great mix. There was much cross-over in the presentations and once I got the hang that this was not a conference of stuff I already knew (or presented at a level that is more introductory), but things I wanted to dig deeper into. I began to realize late into the conference (or after in many cases) that the people presenting were people whose writting and contributions I had followed regularly when I was doing deep development (not managing web development) of web applications. I changed my focus last Fall to get back to developing innovative applications, working on projects that are built around open data, and that filled some of the many gaps in the Personal InfoCloud (I also left to write, but that did get side tracked).
As I mentioned before, XTech had the right amount of geek mindset in the presentations. The one that really brought this to the forefront of my mind was on XForms, an Alternative to Ajax by Erik Bruchez. It focussed on using XForms as a means to interact with structured data with Ajax.
Once it dawned on me that this conference was rather killer and I sould be paying attention to the content and not just those in the floating island of friends the event was nearly two-thirds the way through. This huge mistake on my part was the busy nature of things that lead up to XTech, as well as not getting there a day or two earlier to adjust to the time, and attend the pre-conference sessions and tutorials on Ajax.
I was thrilled ot see the Platial presentation and meet the makers of the service. When I went to attend Simon Willison's presentation rather than attending the GeoRSS session, I realized there was much good content at XTech and it is now one on my must attend list.
As the conference was progressing I was thinking of all of the people that would have really benefitted and enjoyed XTech as well. A conference about open data and systems to build applications with that meet real people's needs is essential for most developers working out on the live web these days.
If XTech sounded good this year in Amsterdam, you may want to note that it will be in Paris next year.
Odd Moments in the Day - Odd Moments with Technology?
Today brought an odd moment. I looked up at iChat (my IM interface) and I see my name (Thomas Vander Wal) and podcast under Jeremy's name, which means Jeremy is most likely listening to a podcast interview with me. I had never seen that before.
Now I decide to share that odd moment with Jeremy, which I did not realize would cause Jeremy to have an odd moment.
How can the world of pervasive/ubiquitous computing ever get off the ground when we give each other odd moments through our friendly stalking? By the way I prefer using stalking, where as some people like the term monitoring, but the term monitoring does not cause me to think about privacy implications that I believe we must resolve within ourself or learn to better protect our privacy.
The incident today still causes me to chuckle for a short moment then realize how open we are with things on the internet and how different that seems to be even though most of our life has been public, but to a smaller and more localized group. It also resignals that change that came with the internet (well and much of technology) is that we can not see those who can see us. In a town we know the local video store guy knows what we rent, but now Amazon knows what we bought as do those people on our friends list whom we share our purchases with so they can have some insight as what to buy. My local video store guy in San Francisco, near California and 2nd or 3rd Avenue, was amazing. He knew everything I rented in the last few months and would provide perfect recommendations. Did he use a computer to aid himself? Nope, he was just that good and his brain could keep the connection between a face and videos rented and if you liked that video. He knew my taste perfectly and was dead on with recommendations. Not only was he on with me, but most others who frequented his store. He was great recommending, but also could help people avoid movies they did not like.
Was the guy in the video store freaky? Not really, well to me. He was a person and that was his role and his job. I worked in a coffee house for a while first thing in the morning. After a couple months I knew who the first 10 customers would be and I knew about half of the orders or possible variations of what people would order. People are patterned, I could tie the person's face to that pattern for espresso coffee drink order and I could recommend something that they should try. To some this was a little disturbing, but to most is was endearing and was a bond between customer and shopkeeper as I cared enough to know what they would like and remembered them (I did not often remember their names and most of them I did not know their names), but I knew what they drank. If is the familiarity.
So, with technology as an intermediary or as the memory tool what is so freaky? Is it not seeing into somebody's eyes? Is it the magic or somebody more than 3,000 miles away knowing what you are listening to and then have the person whom you are listening to pop-up for a chat? I think it is we have collapsed space and human norms. It is also difficult to judge intent with out seeing face or eyes. I was in a back and forth recently with a friend, but could not sense their intent as it seemed like the tone was harsh (for a person whom I trust quite a bit and think of as being intensely kind and giving) and I finally had to write and ask, but it was written from a point where I was bothered by the tone. My problem was I could not see the eyes of the person and see they playfulness or gestures to know their intent was playful challenging.
While at the Information Architecture Summit a couple/few weeks ago in Vancouver a few of us went to dinner and we played werewolf (my first time playing). But, I was reminded that the eyes hold a lot of information and carry a lot of weight in non-verbal communication. I could pick the werewolf whose eyes I could see, but in two occasions the werewolf was sitting next to me and I could not see their eyes. There was one person in each of the two games whom I did think was the werewolf as their eyes were signaling similarly to people who were not telling the truth in the cultures I grew up in.
Could technology be more easily embraced if it had eyes? Should we have glancing as Matt Webb has suggested and built an application to suggest? But could we take Matt'a concept farther? Would it be helpful?
This was a long post of what was just going to be pointing out an odd moment in the day.
Microsoft Live Image Search
I have been rather quiet about my trip to Microsoft as part of their Search Champs v.4. This trip was mid-January and I was rather impressed with the what Microsoft showed. The focus was late-stage beta for MS Live products and things that were a little more rough. Last week Expo launched, which is a rather cool classified site along the lines of edgio and Craigslist. Expo did not launch with anything ground breaking, but that could be coming. None-the-less it is refreshing to see this kind of effort and interest coming out of Microsoft.
Live Image Search is a Great Web Interface
One of the products that was stellar and near launch that we saw was Live Image Search (shown with vanderwal - what else). Image search was stellar as it is quite similar to Apple iPhoto with its interface, but built for the web. Take Live Image search for a spin. No really, scroll, mouse over, change the thumbnail size on the fly. It is fast and responsive. I am quite impressed.
Oh, since I am on a Mac, I have been using Firefox/Camino to view Live Image search and it works just as wonderfully as it did in the demos on Windows with IE. I think Microsoft understand that the web is a platform, just like Windows and Mac. Microsoft gets that the web as a platform must work on top of other OS platforms. The web browser is an OS agnostic application and must remain so. Microsoft seems to understand that when building for the web it should work across browsers and OS platforms otherwise it is just developing for an OS, but that is not the web. The proof in this will be when Microsoft releases an Live toolbar for Firefox that has all of the access and functionality of the IE toolbar.
More to Come
I am really waiting for another product to get launched or closer to launch as I really think Microsoft will have a good product there too. It is something that really is of interest to me. It really seemed like the Microsoft people we worked with were really listening to our feedback.
Color my opinion changed toward Microsoft. Not only are they doing things of interest, but they are shipping. They are not only trying to get the web, but they have brought in people who understand and know what direction to head. I went to Microsoft out of curiosity and found something that went against my notions of what they were doing. Microsoft get the web in a similar manner to the way that Yahoo does, it is about people with real problems.
Where is my Mac?
Am I giving up my Mac? No. Hell no. My OS works the way that I work and does not get in my way. I don't spend time swearing at it or messing with it. I do the things I need to do for my job and life using technology to augment that effort. Apple has been doing this for years and I don't want to mess up a very good thing.
Ray Ozzie Demos Live Clipboard for the Personal InfoCloud
Boy, did I whine too early! As Jyri blogs, Ray Ozzie demos a desktop to blog structured information tool. Ray demonstrated a potential (or is it real) tool from Microsoft, Live Clipboard. A set of screen captures of the Ozzie demonstration of Live Clipboard shows what they are up to. It is killer stuff that really solves real problems people have in living their life with digital information across their devices and platforms. He focusses on structured information, which is all around us, or should be all around us.
Ray Ozzie is one of my favorite geeks. I would have some extremely serious Microsoft love if Microsoft follows the Ray Ozzie vision of technology rather than that of the buffoon Steve Balmer. Ray has the vision and understanding that Bill Gates had for the desktop, but never showed beyond that. Balmer just seems to do more damage to Microsoft than any benefit (what is his benefit?) he provides. Where as Ray just flat out rocks by being brilliant (in a visionary to real product way), calm, and a wonderful communicator. Ray built one of my favorite tools, Groove, but stopped non-Microsoft version far too early as that could be THE killer app of the decade (last 10 years). If Groove were platform and device agnostic it would be the best thing going, but it will have to settle for a good app that has boundary limitations.
Ray is bright and understands the problems that real people have with digital information and focusses along the lines of the Personal InfoCloud for solutions. He seems to show not only tools, but simple solutions for real people to use. It is what Microsoft needs (that and to ship) and what the industry needs. So far Apple is one of the few big (non-web) companies in the space providing simple solutions that work to resolve the problems of real people as they interact with digital information and media.
ETech is Emergent? [updated]
I thought this would be the year I was going to ETech, but with a few other things going on it was not the year. I have many friends that go each year and I see them very rarely.
But, I think I would have been very frustrated by ETech this year. It is still about the web. Achingly, still about the web. The problem is digital information and media is increasingly living beyond the web. The web is but one platform to distribute information, but thinking people live their lives in and on the web is silly. Want the information that is on the web, but need the information in their lives, in their devices they have with them, and in context to the rest of their life.
The panel that triggered this reaction is one by friends, Jesse and Jeff "Designing the Next Generation of Web Apps". In Tom Coates review the binary approach (web for reading and web for apps) sounds so short sited and really caused the trigger. Is Emerging Tech just rehashing the current and the past? Or can it move forward? I am not seeing much of that forward movement this year.
People live their lives attracting information and focussing on the Come to Me Web and Personal InfoCloud we know people need the information to better mesh into their personal digital information workflow, which involves very little of the web. People find the information that they want and need and work very hard to keep it attracted to themself for easy refindability. Other than social bookmarking tools and a few others web based tools, much of this is done with tools that are beyond the web. Some people tuck all of their needed information and links into e-mail, others calendar, to do lists, PIMs, text files, syndication, e-mail, SMS, MMS, documents, mobile syndication, mobile documents, outlines, wiki on a stick, etc. There are many tools and many ways of working around lack of web access when people need the information most.
Many people, unlike those of us that build web-based tools (I am in that category), don't live on the web and their digital information needs to live beyond the web as well. That is the future of the web, it is a platform for just one state of information. That state that the web represents is the state of information transience. The information is in the process of moving from the creator to the person needing that information for their own use or for their reuse. This use will most likely not be on the web, but the reuse of information may be on the web.
The web as it exists now is a tool for publishing and aggregating. Some will use the web for use and reuse, but we need far more options that the web for real people to adopt their future and our now. We, as developers of tools, information, and resources must pay attention to real people. We must pay attention to their lives beyond the web and the large box in front of them. We need to understand their problems that they really have, which revolve around refindability and information reuse in their environment and context.
Now please go back to paying careful attention to the great things that friends and other alpha geeks are presenting at ETech and other conferences and un-conferences as that information is needed, but remember we are moving beyond, far beyond this current state of the web.
[update] Um, well Ray Ozzie just made me wish I was at ETech. He just showed what is emergent and what is the future. It could answer many of the items I just listed above. You go Ray!
Thomas Vander Wal on PodLeaders Podcast
I have been quite busy of late. Between some InfoCloud Solutions client work and some other things (including family).
I really need to pay attention to my blog a little bit as I do have things to post, like Thomas Vander Wal interviewed by Tom Raftery on PodLeaders podcast. The podcast covers the "come to me web", folksonomy, InfoClouds, and InfoCloud Solutions work. I wish I could talk more about my client work, but that will come.
This was recorded over a Skype connection with Tom sitting in Ireland. I was using my Apple iSight and it worked rather well. I have been enjoying Skype for chats with friends and business relations in Europe, I really like the quality as well as the price. But the thing that I really like is that it is really personal, much like a mobile phone, you are pretty much assured of getting the person you wish to talk with rather than some answering service or other interference.
I am back to working.
Changing the Flow of the Web and Beyond
In the past few days of being wrapped up in moving this site to a new host and client work, I have come across a couple items that have similar DNA, which also relate to my most recent post on the Come to Me Web over at the Personal InfoCloud.
Sites to Flows
The first item to bring to light is a wonderful presentation, From Sites to Flows: Designing for the Porous Web (3MB PDF), by Even Westvang. The presentation walks through the various activities we do as personal content creators on the web. Part of this fantastic presentation is its focus on microcontent (the granular content objects) and its relevance to context. Personal publishing is more than publishing on the web, it is publishing to content streams, or "flows" as Even states it. These flows of microcontent have been used less in web browsers as their first use, but consumed in syndicated feeds (RDF, RSS/Atom, Trackback, etc.). Even moves to talking about Underskog, a local calendaring portal for Oslo, Norway.
The Publish/Subscribe Decade
Salim Ismail has a post about The Evolution of the Internet, in which he states we are in the Publish/Subscribe Decade. In his explanation Salim writes:
The web has been phenomonally successful and the amount of information available on it is overwhelming. However, (as Bill rightly points out), that information is largely passive - you must look it up with a browser. Clearly the next step in that evolution is for the information to become active and tell you when something happens.
It is this being overwhelmed with information that has been of interest to me for a while. We (the web development community) have built mechanisms for filtering this information. There are many approaches to this filtering, but one of them is the subscription and alert method.
The Come to Me Web
It is almost as if I had written Come to Me Web as a response or extension of what Even and Salim are discussing (the post had been in the works for many weeks and is an longer explanation of a focus I started putting into my presentations in June. This come to me web is something very few are doing and/or doing well in our design and development practices beyond personal content sites (even there it really needs a lot of help in many cases). Focussing on the microcontent chunks (or granular content objects in my personal phraseology) we can not only provide the means for others to best consume our information we are providing, but also aggregate it and provide people with better understanding of the world around them. More importantly we provide the means to best use and reuse the information in people's lives.
Important in this flow of information is to keep the source and identity of the source. Having the ability to get back to the origination point of the content is essential to get more information, original context, and updates. Understanding the identity of the content provider will also help us understand perspective and shadings in the microcontent they have provided.
A Better Day and Brigher Future
Things are a little better on this end today. I was able to delete the Photoshop French version and reinstall a Photoshop demo (I was very surprised I was able to do this and get back to the exact days left on the tryout where is left of yesterday) so I could continue to work. The shipment of the new package will be the fourth attempt to get this right by Adobe (their stock price is what?).
I have received many great suggestions on hosting and am looking at two of them seriously. E-mail has been up all day today as host hosting, which is good.
Along this front I am really getting tired of my own blogging tool. I no longer have time to keep running and the effort it takes to write, check, and post does not work for me any longer. I am doing too many things at once and not paying enough attention to the actual writing, which I really need to. I also blog adding all the mark-up needed (including needed character encodings). I really want to turn on comments again as readership here has grown and I really want to get back to "conversations" (not just monologues plus e-mail). There are things I want to build that I think would help the blogging community, but it is really fruitless to do this for a tool that has an install base of 1.
I have my options narrowed down for me as I will be running two sites from it and be using it as a CMS as well as a blogging tool. The two candidates I am down to are Movable Type and Drupal. I am leaning toward MT mostly because they have a very active support system inside the company and user-base. Drupal has a killer user-base that is very innovative and the tool has many social and community aspects to it that I really like. I will most likely be playing with both. Both have a good track record running more than one site off an install and using shared components for the different sites.
Now it is sorting out, which I can dump my current site into most easily and clean out the mark-up and encoding so to let the blogging tool do it (will make for easier current specification RSS/Atom feeds). I am also wanting to keep the 1770-plus URLs the same (as well as RESTful), which I have not sorted out. Suggestions are welcome.
Real Time Flight Tracking Site for Your Mobile
Thanks to Tim Boyd I found a wonderful Mobile Flight Tracking Tool (the flight tracking tool is described by Jon Gales the developer. Tim took a photo of the flight tracking tool running on his Treo.
This is exactly the right tool to do the job that many need. Everybody complains about the lack of mobile interfaces to flight on-time information when they are needing to meet somebody at the airport. The airlines solutions either do not exist, are not detailed enough, or have interfaces that are cluttered (even on a Treo). Airlines suggested arrival times are a joke as they are trying to compensate for their tendencies for late arrivals, which they get penalized on. This has lead to a 45 minute flight from Washington to New York being stated at a flight time of 2 hours or more. On-time flight is not anything close to an efficient guide.
Most of the airline sites only think of the desktop for decent information, but where real-time flight arrival information is important is when you are on the go. Jon Gales's application solves a real life information need in the context of life. A standing ovation for his work is in order. I wish more apps like this were in existence, information solutions for people's real lives (we do not sit at our desktops and most do not carry their laptops where ever they go).
When designing for the mobile (this app horizontally scrolls on my Nokia 3650 and solving that is a relatively easy solution) we need to cut out the clutter. We need to understand the information need and the information that can be provided on that small screen. Paring away what is not essential is a vital task. Getting to what is important is also important. What is important is accurate and useful information for people's given the context that people wanting to use the information on the go face.
Yahoo! Go Launches [Updated]
I am quite interested in the newly launched Yahoo! Go, which is self described as:
Yahoo! Go - a new suite of products and services for your PC, mobile phone and even your TV.
Yahoo! Go allows you to access the information and content that is important to you on whatever device you choose.
So wherever you go, your photos, your music, your email, " your life&#quot; is right there with you. Ready to go.
The service provides your contacts (address book), photos, messanger, and mail. All great to have where ever you go. This is a very helpful service.
But wait! It is missing one thing. Yahoo! states, "allows you to access the information and content that is important to you". If that is true it is missing one giant piece. Where is the calendar? [Update] The calendar is actually there. Russ Beattie (of Yahoo! Mobile) provided the following response:
Y! Go also syncs the Calendar, it syncs with your Yahoo! Calendar and uses the Series 60 native calendar app on the phone for alerts. The SyncML service also syncs the calendar on phones like the SonyEricsson's and Nokias which support it.
What really impresses me is the SyncML work. That news is one of the most impressive things I have heard on calendaring in a while. I have been waiting for Apple to go this route for their iSync for the last couple revisions and I thought they would be the leaders on this syncing standards front. Yahoo! seems to understand the needs today and the future, which is one of the things that has impressed me about Yahoo! in the last year or two (they really get it, possibly better than any other large web company, yes I am considering Google too). If you want more info on Yahoo! and using SyncML Russ has the following post on Yahoo! Mobile Services: SyncML and More. I am still not sure why the marketing people left out calendaring. [/Update]
<ignore>Of all the things to leave out.</ignore> The calendar is one of two pieces of essential social data that people complain constantly that they do not have access to, or did not sync properly (the other is contact info). A large part of our social communication is about the "next". It could be the next call, the next meeting, the next lunch, the next... you fill-in the blank. Social is not completely about the now, it is about the future too. Not having a component to connect in the future and to ensure proper planning it is only a partial social tool.
One of my pet peeves the last four years, or so I have been working with the Model of Attraction and the Personal InfoCloud (your information you are interested, that you have attracted to your device, becomes attracted to you and moves across your devices so it is at your ready call when you want it and need it) is constant access to one's own information, which means whether you have connectivity or not and is available on the device you have with you (it must be device and platform agnostic). Yahoo! seems to get this all but for that one important bit.
In the past year Yahoo! purchased a company that provides event information (Upcoming), which could tie wonderfully into a calendar (either as events you are attending or potential events). Yahoo! also recently announced connecting Tivo and your Yahoo! calendar. We know they get the importance of the calendar. Where oh where is it? [Update] It is actually there just not advertised.[/Update]
Off the Top Blog Turned Five
I forgot that 31 December 2005 was my 5 year anniversary blogging. A lot has changed on this blog and the whole blogging arena. Many of my short posts along the lines of, "I found this cool thing... " are now in my del.icio.us feed, which for those of you with JavaScript turned on is over on the right as the new incarnation of Quick Links. The same items and more I also post over on Yahoo! MyWeb, but because I can post to just myself or to a community of people I know with similar interests. (I really really hope their community functionality of MyWeb gets fixed soon in 2006 to better filter feeds from the community coming to me and allow something other than, "you can see all of my links and I will see all of your links". Life and real people's interests are not like that and Yahoo! is the people understanding people products on the web for people's lives. So, lets get to it shall we?)
Blogging seems to be more than the relative handful of people I followed in 1999 through 2001. It really exploded following that, partly because there were more options that were easy to use and options that became more stable. In 2000 I had been running this site (under a few different URLs) for five years and when I added Blogger as my tool to add content more easily it was a wonderful change for me. Not long after that Pyra (the company that started Blogger) imploded and we were left with just Ev and when Ev was away Blogger had separation anxiety. Not long after I turned to blogging by hand for a few months. I then put my own blogging tool in place that eased my workflow (Movable Type did not have the features that I wanted for my multiple categories and three entry types (essay, journal, and weblog). I had built my tool as a means to post information while traveling from any web browser when I was doing it by hand and needed FTP to regularly post. I have been running the same blogging tool with modifications since it launched 31 October 2001 (I had a post on my hand built page from October 2001 announcing it.
The look of the site has changed from the bright blue and bright green on black the blog launched with (this had been used for two years or so, and blogging with that use of the color palette was hard on the eyes). I moved to a less hard on the eyes color scheme not long after the blog launched. The current look was put in place 20 November 2002. Other than turning off comments (which I hope to bring back some day) and modifying the right-hand bar I have not made many changes since then. Life has been a bit busy since then.
I am still hoping that I will move this blog to a commercial blogging tool as my time is pulled elsewhere and I do not have the time or energy to tweak the underlying code that creates this blog. I have been quite happy with my use of TypePad since they launched and I keep my more professional blog, Personal InfoCloud over there. My happiness with TypePad and the full company of six apart there to support Movable Type will likely make it my choice. I have some other uses for the Movable Type software, other than this blog that is helping my choice. I am also a fan of WordPress and Drupal (Drupal has the capabilities under it to do what I want and need too and a large developer community). These changes come down to time available, so I could be a while.
For Many AJAX is Not Degrading, But it Must
A little over two months ago Chad Dickerson posted one of the most insightful things on his site, Web 0.1 head-to-head: 37Signals' Backpackit vs. Gmail in Lynx. You are saying Lynx? Yes! The point is what 37Signals turns out degrades wonderfully and it is still usable. It could work on your mobile device or on a six year old low end computer in Eritrea in a coffee house or internet cafe (I have known two people who have just done that in the last year and found Gmail did not work nor did MSN, but Yahoo did beautifully).
Degrading is a Good Thing
Part of my problem with much of the push towards AJAX (it is a good, no great thing that XMLHTTPRequest is finally catching on). But, it must degrade well. It must still be accessible. It must be usable. If not, it is a cool useless piece of rubbish for some or many people. I have been living through this with airline sites (Continental), commerce sites (Amazon - now slightly improved), actually you name it and they adopted some where in this past year. In most cases it did not work in all browsers (many times only in my browser of last resort, which by that time I am completely peeved).
When Amazon had its wish list break on my mobile device (I (and I have found a relatively large amount of others this past couple years doing the same thing) use it to remember what books I want when I am in brick bookstores and I will check book prices as well as often add books to my wish list directly) I went nuts. The page had a ghastly sized JavaScript, which did some nice things on desktops and laptops but made the page far too large to download on a mobile device (well over 250 kb). In the past few weeks things seemed to have reversed themselves as the page degrades much better.
Is There Hope?
Chad's write-up was a nice place to start pointing, as well as pointing out the millions of dollars lost over the course of time (Continental admitted they had a problem and had waived the additional phone booking fee as well as said their calls were up considerably since the web redesign that broke things for many). Besides Chad and 37Signals I have found Donna Mauer's Designing usable rich internet applications as a starting point. I also finally picked up DOM Scripting: Web Design with JavaScript and the Document Object Model by Jeremy Keith, which focusses on getting JavaScript (and that means AJAX too) to degrade. It is a great book for designers, developers, and those managing these people.
I have an awful lot of hope, but it pains me as most of us learned these lessons five to seven years ago. Things are much better now with web standards in browsers, but one last hurdle is DOM standardization and that deeply impacts JavaScript/DOMScripting.
Delicious Lesson and Social Network Ecosystems
Joshua Porter brings up a wonderful point he is calling the "Delicious Lesson". The Del.icio.us Lesson is incredibly important, as it is one thing that many tools and implementations of the social web do not get. The person must get value for their interaction in the service or it will fade.
I see so much focus on the technology, the interaction components, the network effect, etc. But, the driver for these services that are successful is that they have a direct primary value for the person choosing to use them.
A Little Effort for Greater Personal Payback
Jeff Hawkins (the inventor of the Palm device and pen-based writing language (Graffiti) Palm used) talks about the most important point for people to adopt and learn Graffiti was it gave the person value. Jeff points out that learning Graffiti took a little bit of time, but people could see value of learning Graffiti as it made for a quicker input of information. There was personal value that did not take a lot of initial effort to learn, which returned a much greater value.
Social Network Ecosystems
In social networks and personal interaction with web applications and their associated communities there is a ecosystem. The social networks have value chains. I have been playing with this idea for a few months (mostly with in the intersection of the Personal InfoCloud and the Local InfoCloud. I have been using it on some personal projects and it is weaving its way into my consulting practice (but with focus on the full ecosystem and values).
The personal interaction with the system/application/service and value derived is a viable measure, particularly when there are two points of value for the person. The first personal value is derived from the service returning direct value to the person for their interaction. In del.icio.us it is making one&039;s own bookmarks/favorites more easily refindable, the ability to expand one's own bookmarks/favorites beyond the functional restrictions of the browser, and having access to the bookmarks/favorites from any browser anywhere one has web access. The second value is the network value, which can be a feeling of digital philanthropy (doing it out of goodness), personal attention (being an authority, coolness, building points for alphaness, etc.), a driver for monetary reward (recognition increases clicks to an site with ad revenues, builds attention for a business, etc.), etc.
Attention is Value
Attention for those providing development, like in the widget communities for Yahoo! Widgets and Apple Dashboard is very important. In the podcast of the Niall Kennedy and Om Malik interview with Kevin Burton regarding APIs this issue gets brought up (beginning at 15:19 into the podcast). The example discusses Konfabulator (the original product name for Yahoo! Widgets) and Apple Dashboard. Kevin Burton (I believe) states Apple Dashboard has larger exposure than Konfabulator does at the moment and Apple could offer the developers more attention to get more people writing widgets for them. Here the initial value for the developers is attention, as is pointed out in the podcast. The developers are passionate about what they do (personal value in a platform for their expression of their development prowess), but the secondary value received is attention. In a limited pool of developers (not only for widgets, but APIs, and other open development arenas) value to the developer is attention, which can lead to monetary value. This value to the developer is going to be a driver for which service they provide their services (a secondary driver is ease of development). The value to the network is more widgets equal more cool things for the service, but the primary reason the developers are there, is often the value to themselves.
Del.icio.us is Back
Yeah!! Del.icio.us is back. After many hours, if not a day of being down due to residual effects from a power outage. I bet Joshua is looking forward to somebody else managing the servers.
I has been a bad week for the popular stuff on the web with TypePad outage problems in the past week as well (yes, that meant Personal InfoCloud was down).
Does it bug me? Not so much. Del.icio.us being down meant I was not cross posting with Yahoo! MyWeb rather than to both places. If this site is down I am not too happy as my work e-mail is on the same server and I have been living in e-mail lately. But, I think with TypePad and Del.icio.us and the like with their outages I have appreciation for what it takes to keep that up and running. I also know the problems inherent in scaling those type of services. At some point the killer ease of use applications become more about killer sysadmins and server/datastore optimization skills. That is where one learns to grow up.
Along those lines, I am quite happy to see Technorati get their server situation sorted out and they are now running at usable speed again (it was a seemingly long time coming).
Web 2.0 Dead?
It was bound to happen sooner or later, but it was a little sooner than expected. Richard McMannus explains why Web 2.0 jumped the shark as an follow-up to his Web 2.0 is dead. R.I.P. post. This pronouncement has an impact as he is co-writing a book on Web 2.0 for O'Reilly Books (with Joshua Porter) and writes Web 2.0 Explorer on ZD Net. In Richard's explanation he gives the prime reason is to get away from the hype and cynicism.
Tim O'Reilly describes Web 2.0 in rather long detail. But in the more than a year that the term has been around it has not been used in any specific specific sense and it quickly turned into a buzzword with little meaning. There are some profoundly different things taking place on the web, when we compare it to the web five years ago. These things seem to be best described by their terms and pointing to what has changed and where we are going now. Richard writes that he will still largely be writing about the same things, but will not be using the Web 2.0 moniker.
The Rich Interface
During the past six to nine months one could easily see that the term Web 2.0 getting flattened into hype and mis-understanding. Many articles were written about new technologies that were changing the landscape, but neither were the technologies new, nor were they doing much of anything different than sites were doing or trying to do in the previous three to five years. AJAX was not new, it was a new name for xmlhttprequest (which most web developer worth much of anything knew about, but knew there was little browser adoption outside of Microsoft IE). Jesse James Garrett provided a much easier means of calling the long term, mostly to talk more easily about what Flickr and Google (in Gmail and Google maps) had been doing in the past year using it as part of their rich interfaces. The rich interfaces were absolutely nothing new as Flash had been providing the exact rich interface capability for years. The problem was much of the design world had not worked through its documentation and design specifications for a rich interface using Flash, but they jumped all over AJAX with out ever working through solutions to the problems of state, (re)addressing information, breaking the back button, addressable steps in a process, etc. Web browsers growing up and becoming consistent and more processing power and memory on the machines under the browsers have enabled the rich interface more than anything that gets credit for being new.
Web as Platform
The web as a platform is a great step forward, but it is anything but new, just ask the folks at Salesforce. But it has been embraced as a replacement for the desktop . The downside is most people do not have continuous access (or anything near it) and many do not want it. People have set workflows that cross many devices, contexts, and information uses. Thinking the web is the only way is just as short-sited as closed desktop applications. The web as a platform is insanely helpful, but it should not be the only platform. We have to work towards cross-platfoms and cross-device use development as an end not just the web.
Forbidden Term
Very quickly this year the Web 2.0 term was forbidden from usage from many conferences and large meetings I went to. It was forbidden as by that point it had lost its meaning and using the more direct terms, like social networking, social bookmarks, rich interface for mail, web as an application platform, etc. It was also noted that people should not say the new web, with out explaining why they thought it was new. There needs to be clarity in understanding so we can communicate, and Web 2.0 did not provide that as it was an umbrella term that was used as a buzz word to replace specific changes people did not understand.
Without a Term How to We Understand
There have been a handful of people who have been writing on the Web 2.0 changes and landscape and using the term well and describing the components that are being used in new ways. Richard was one and his writing partner Joshua is another. The group that is aggregated at Web 2.0 Workgroup are most of the rest.
With out the term Web 2.0 it will be tough, but it was more a marker of a confluence of many different things that shifted than a bright line in one or two areas. Understanding what has changed will make sense, which is a large part or what Joshua has been doing and a small handful of others. When the confluence is the streams and rivers of technology, social interaction (as Bruce Sterling calls it "technosocial"), interface, web services, application that provide uses that are needed, cultural and social changes along the lines of privacy (this could swing back massively), cultural changes with more people having comfort with social interactions using technology, trust, etc. take place there will be problems describing it. There will also be only a rare few that can cross the chasms and grasp, make sense of the subtle as well as vast changes, and explain them intelligently and simply to others. As the majority of writing has proven it is a very rare few indeed that have the background and wit to handle this challenge.
Now that I am at the end of the brain dump (some of it long festering), I think I am a wee bit sad to see the term losing traction. But, I don't have to think had to remember one of the vast many of poor articles that every journal has had somebody write.
In full disclosure I spoke on the BayCHI Web 2.0 Panel held at Parc in August. Been writing and speaking on digital information use across devices and platforms for three or four years and the underlying information architecture that is needed to support it. In this past year I frame the need for it as a change from the "I go get web" to the "Come to me web" (not quite equivalent to the push/pull analogy, but I will explain this later for those that have not heard the presentations or me just ramble about it). I felt it important to frame what I change I was talking about rather than rely on the Web 2.0 moniker.
Structured Blogging has (Re)Launched
Structured Blogging has launched and it may be one of the brightest ideas of 2005. This has the capability to pull web services into nearly every page and to aggregate information more seamlessly across the web. The semantic components help pull all of this together so services can be built around them.
This fits wonderfully in the Model of Attraction framework by allowing people and tools to attract the information they want, in this case from all around the web far more easily than ever before.
[Update] A heads-up from Ryan pointed out this is a relaunch. Indeed, Structured Blogging is pointing out all of the groups that are supporting and integrating the effort. The newest version is of Structured Blogging is now microformat friendly (insanely important).
Yahoo! and Del.icio.us come together
Today brings wonderful news on the folksonomy front, del.icio.us is now a Yahoo! property (Yahoo! announcement). The del.icio.us tool and Yahoo! MyWeb are two of my favorite tools out there.
There are many things I would like MyWeb to do, but would be difficult as they would be treading on IP of del.icio.us, which is delicate territory (just ask Blackberry/RIM). Del.icio.us would not be able to pull off the MyWeb improvements that come in the Yahoo! search, which now kicks anything Google is doing (Google has really fallen behind with search just because of this). Having both products, with del.icio.us hopefully becoming MyWeb 3, would make it nearly untouchable. Granted there is an insane amount of fixing that Yahoo needs to do with its social networking (or community tool as it calls it) under MyWeb, but that is not rocket science and hopefully would all be fixed in the next version of MyWeb.
Congrats all around on this one.
Design Engaged and Symposium on Social Architecture
I got back home late Tuesday night from Design Engaged in Berlin and Symposium on Social Architecture in Cambridge, Massachusetts at Harvard. I had a deadline to meet by midnight Tuesday. Much of Wednesday was spent unbolding e-mail and getting essential replies out (more of this to do today) and unbolding my feed aggregator (1500+ things). I also spent time posting photos of the trip to Berlin (currently at 216 photos, possibly a few untagged).
Design Engaged
Design Engaged was somewhat different from last year's event in Amsterdam. It was still interacting with many of my favorite people, but it was a little larger, in a new space, in a new city (one I was not familiar with), and had a larger representation of women. All of these turned out good, but I felt a little more disconnected. The disconnection I think was attributable to an unfamiliar city, staying at a hotel away from where the sessions were, and not having most of the people staying at the same hotel. I tended to stick with those staying at my hotel, which was good for those relationships. But, part of this was tied to my unfamiliarity with the city.
This unfamiliarity changed for the better and I have learned something about myself, and that is all good. The unfamiliarity shifted to familiarity. I got to know some incredible people and spend time with people I knew, but now know much better. I got to know Berlin. I have not been to a completely new city that I had time alone in quite a while (Brussels last month was new to me, but I was with a large group I had become familiar with, I all were staying in the same hotel, and I had very little interaction with the city itself). My first impression of Berlin was good, nothing more and nothing less. This was formed on an outing to Potsdamerplaz and walking back through Mitte.
Part of the Design Engaged experience is interacting with the city. A group of us headed out to Friedrichshain, which was part of East Berlin and is not being torn up and made western to the degree that Mitte or Alexanderplaz have been and are going through. This was the perfect outing for me as I really wanted to understand East Berlin or get a flavor of what pre-unified Berlin was like. I was interested in the Soviet style architecture and the working neighborhoods. Why? They are something I do not understand and had not experienced. I was utterly thrilled with our exploration of the area, both on our own and with a local who life is in that neighborhood.
I also learned a fair amount about myself on the Berlin part of the trip. I use various supports to explore that which is new. I use friends to guide in new surroundings and meet new people. Familiar surroundings to best embrace new people and expand my knowledge of the surroundings. I learned that having much new causes me to fall into an observation mode and a little less interactive. There are people I really wanted to get to know better and spend more time with. I tended to spend time with the people I already know well, in part to catch-up and get to know better. I also spent a lot of transit time trying to take in as much of my surroundings as possible. Understanding the lay of the land, the flavor of the neighborhood, trying to glimpse what the neighborhood was, what that neighborhood is becoming, and the expression of the people who live in and move through that area. The architecture, design layers (planned and emergent layers -- painted and overlayed), traffic patterns, lines of sight, etc. are all important components to understanding the people, their interests, and indicators of importance. Digging through the international layers (Starbucks (particularly behind the Brandenburg Gates is problematic), Duncan Doughnuts, American brand advertising, and global mass produced products), which in my opinion are disruptive to the local culture.
After returning home I know I have a much better understanding of Berlin and it is a city I would love to return to so to spend more time and explore. Now that I have a foundation of understanding I am ready to drink in more. I also realized that observation limited my getting to know others better than I would have liked. Ever single person at Design Engaged this year was utterly fantastic. It is a very special group of people. There are no egos. There are no agendas. There are people who love sharing, learning, embracing, and exploring. This is something very special and something very different from most any other gathering. Part of it is the event is not about certainty, but exploration, asking questions, listening, and growing all in a shared experience. Unfortunately I am more ready to engage others and interact now that I am home, but hopefully there will be more time.
Symposium on Social Architecture
Counter to the Design Engaged the Symposium on Social Architecture was in a somewhat familiar place, but I only knew a few people prior. I knew many from digital interaction, but personal "in place" interactions were limited. There were more people who knew of me, than I knew of prior. I was continually having to put people in context of digital and idea spaces (some of this is now connecting). I had somewhat slept much of the journey from Berlin to Boston (transferring in Washington, DC) so I was not really dealing with jet lag. On the first night there was a reception at the Harvard Faculty Club and I met many fantastic people. I noticed there was a fair amount of clustering by gender, which was bothersome as there were a few women I wanted to chat with, but I found some very good discussions in the men's clusters and did not break free. There are many women whose work I find insanely helpful and wanted to say thanks and engage in some longer conversations.
The symposium was utterly fantastic. Every session had something I really enjoyed and there was a lot of reassurance of my own understandings and directions. I am not as fully engaged in the social software realm as I would like as it is an insanely important component of how we do things on the internet and it is growing ever more important. Much of my work discusses the Local InfoCloud as an intersection with the Personal Infocloud.
I have a lot of notes from the day (but more complete notes will be expressed in a later posting). I heard a lot of mention of local (closeness drawn through interconnection in social contexts), which was a reinforcement of my understanding as well as the language (or problems with the language) I have been dealing with at times. I heard a lot of discussion of all current social software is simple software, as it is easy to understand what the value is and the barrier to entry is a relatively painless in comparison to the reward received in the perceived value. Many also discussed building tools that got out of the way, they just let people interact. This was explicitly stated by Tina Sharkey of AOL, which made me very happy as it was a large social portal that expressed they understood what to do and have done it. It is not the tool that is important, so much as it is the social interactions that are the key. The tools should be a platform for connecting and communicating not for controlling.
I also met one of the people responsible for Steve, The Art Museum Community Cataloging Project, which could be the most important folksonomy and tagging endeavor that is ongoing. The importance is in part their work, but the research into tagging and folksonomy is insanely helpful and seems to be the best work out there at the moment. The work proves the strong positive significance that tagging and folksonomy plays in connecting people to objects and information. Having the world framed in a language or vocabulary is incredibly helpful and that is not often a result of formal taxonomies as they tend to optimize toward the norms and not embrace the edges. I will be writing about Steve more in the future, but I was so excited to meet somebody tied to the project so I could have more conversations and learn what they have found to be helpful and not so helpful.
The panel on politics and social software, particularly in relation to Katrina, was great. It highlighted the problems with politicians and their lack of understanding technology that could better connect them to their constituents, but also technology that could better enable solutions and resolution for their constituencies. I was completely moved by this panel.
The piece I had disappointment in was the closing. Er, the closing was Stowe Boyd interviewing me about what I found of interest from the day and what I would take home. Stowe asked the perfect questions, but I learned something about myself, I framed my responses literally and too personally. I let myself down in the responses as they were too general and did not capture the whole of what I got from the day nor the strong themes I noted. I was still taking in the politics panel and re-digesting the day based on that context. When I get a new perspective or new information I run the world I perceive through that lens and adjust accordingly and then emerge with a slightly reshaped or more inclusive framework. I think my closing remarks were poor, because I was integrating the last panel into my understandings. The rest of the day went largely as I expected, but the wonderful politics panel disrupted me in a positive manner. I apologize for the poor closing observations. For me it was the poorest part of a great event.
Folksonomy Definition and Wikipedia
Today, having seen an new academic endeavor related to folksonomy quoting the Wikipedia entry on folksonomy and I realize the definition of Folksonomy has become completely unglued from anything I recognize (yes, I did create the word to define something that was undefined prior). It is not collaborative, it is not putting things in to categories, it is not related to taxonomy (more like the antithesis of a taxonomy), etc. The Wikipedia definition seems to have morphed into something that the people with Web 2.0 tagging tools can claim as something that can describe their tool (everybody wanted to be in the cool crowd). I hope folksonomy still has value as a word to point something different in the world of tagging than the mess that went before it. It is difficult to lose the pointer to something distinct makes understanding what works well. Using folksonomy and defining it to include the mess that was all of tagging and is still prevalent in many new tools dilutes the value.
Folksonomy Is
Folksonomy is the result of personal free tagging of information and objects (anything with a URL) for one's own retrival. The tagging is done in a social environment (shared and open to others). The act of tagging is done by the person consuming the information.
The value in this external tagging is derived from people using their own vocabulary and adding explicit meaning, which may come from inferred understanding of the information/object as well as. The people are not so much categorizing as providing a means to connect items and to provide their meaning in their own understanding.
Deriving Value from Folksonomy
There tremendous value that can be derived from this personal tagging when viewing it as a collective when you have the three needed data points in a folksonomy tool: 1) the person tagging; 2) the object being tagged as its own entity; and 3) the tag being used on that object. Flattening the three layers in a tool in any way makes that tool far less valuable for finding information. But keeping the three data elements you can use two of the elements to find a third element, which has value. If you know the object (in del.icio.us it is the web page being tagged) and the tag you can find other individuals who use the same tag on that object, which may lead (if a little more investigation) to somebody who has the same interest and vocabulary as you do. That person can become a filter for items on which they use that tag. You then know an individual and a tag combination to follow. The key is knowing who and what specifically is being tagged.
Social Tagging
There are other tagging efforts that are done for socially connecting others and others where people are tagging their own information for others. I have been to workshops where items on the web were tagged with a term that was agreed upon for tagging these objects across tools. This allows the person to retrieve information/objects connected with that event as well as others getting access to that information/object. Does it fall into the definition of folksonomy? This gets fuzzy. It is for the retrieval of the person tagging the information, so it could fit. It gets close to people tagging information solely for others, which does not get to a folksonomy, it is what Cory Doctorow labeled Metacrap.
Academics Quoting Wikipedia
Sadly, I have had 15 to 20 academic papers sent to me or links to them sent to me in the past year. No two of them use the same definition. Everyone of them points to Wikipedia. Not one of the papers points to the version of the page.
The lack of understanding the medium of a Wiki, which is very fluid, but not forgetful, is astonishing. They have been around for three or four years, if not longer. It is usually one of the first lessons anybody I have known learns when dealing with a Wiki, they move and when quoting them one must get the version of the information. They are a jumping off point, not destinations. They are true conversations, which have very real etherial qualities.
Is there no sence of research quality? Quoting a Wiki entry without pointing to the revision is like pointing to Time magazine without a date or issue number. Why is there no remedial instruction for using information in a Wiki?
Personal Love of Wikis
Personally, I love Wikis and they are incredible tools, but one has to understand the boundaries. Wikis are emergent information tools and they are social tools. They are one of the best collaboration tools around, they even work very well for personal uses. But, like anything else it takes understanding on how to use them and use the information in them.
BBC Knocks Audio Annotating Out of the Park
Tom Coates shows off the BBC's Annotatable Audio Project. Tom gave me a preview early on Saturday and I was ecstatic. You see, what the tool does is provide an interface to annotate and segment audio on the web. Yes, podcasts can be easily segmented and annotated. This has been my biggest complaint with podcasts over the past year, okay since they started getting big (that is big for an early early adopter). I complained to people I knew at Odeo about the problem and they said they were working on it. I mentioned this to podcast enthusiasts at Yahoo! about nine months to a year ago and they said if they did podcasting that would be one of the first things in it as it was a big complaint. Did they? No, they made a product not too indistinguishable from every other product out there? Where is the innovation?.
Why is this Huge
The reason I am so excited about this is voice/audio is not easily scannable, like type. I can not easily skip ahead in a 30 or 45 minute podcasts to find that which I am interested in. Many friends will forward me links to a podcasts stating I have to hear what somebody says. Finding that segment usually means listening to much of the whole podcast.
The other downside is if I hear something stellar in a podcast my mind will mull over that item for a little bit. This means the minute to five minutes that follow in the podcast are lost on me. This is not a problem with written materials as I can skim back through the content and pick-up where my mind drifted (it is usually in these moments of drifting that I find the best solutions to things that have bugging me - the Model of Attraction came out of one of these).
A couple other items of note about this product. It is great interface design as it is interactive helps the person using the product know exactly what they are doing. The second is the segmentation is a great asset. With segmentation I can easily see writing a script to grab items of interest (27 seconds for here and 36 seconds from there, etc.) and having an automated audio stream built for me. Not only do I have a personalized audio stream, but since the originals are annotated and I can keep track of where the information is extracted from I can easily point others to the spot so they (or I) at some later point can go back and listen to more so to get better context (personally I don't think people are against attribution, it is just that we have made it so hard to do so in the past).
Voice and Audio is a Common Problem
The last couple time I have travelled in the USA I have run across people quite similar to me. None of us like voice. We are not particularly fond of the phone, for much the same reasons as I have problems with podcasts. Too much information gets lost. In phone conversations I am often saying, "I am sorry can you repeat that", in part because I did not hear, but the something that was stated just triggered a good though process for me and I missed what came after that moment. (What would be a great application is Tivo for the phone.) I continually am running new ideas and thoughts through what I believe and see how they may change it. It is the examined life - I enjoy living.
So what Tom and his cohorts did was make podcasts and audio more usable. It makes it searchable. One thing that would be a very nice addition is to have those annotating the information each have their own distinct layer. Just like with folksonomies, the broad folksonomy where each individual and each annotation on a distinct element provides a richer understanding and richer layer. (Such things would be really nice in Wikipedia so that I could remove the people who I do not think add any value to entries (in not polite terms - those who I know are wrong and are polluting the value of Wikipedia, which is far too much noise for me on the entries I would love to point to), or conversely to use a "white hat" approach and subscribe to the annotations of people and the distinct tags or terms they use in annotations. I have many people whose opinions and view I value, but on rare occasions it is everything a person has to say.
Filtering information in a world of too much information to keep track of is a necessity. Filtering is a must. It is about time we got here.
Thank you Tom. I hope your new team can innovate as much as you were allowed at the BBC, which has been the most innovative large enterprise going.
Microformats hCard and hCalendar Used for Web 2.0 Conference Speakers
Tantek has posted new microformat favelets (bookmarklets you put in your browser's toolbar). The microformat favelets available are: Copy hCards; Copy hCalendars; Subscribe to hCalendars; feed Copy hCalendars (beta); Subscribe to hCalendars feed (beta). Look at Tantek's Web 2.0 Speakers hCard and hCalendar blog post to understand the power behind this.
Microformats are one of the ways that sites can make their information more usable and reusable to people who have an interest. If you have a store and are providing the address you have a few options to make it easy for people, but a simple option seems to be using the microformat hCard (other options include vCard and links to the common mapping programs with "driving directions").
There will be more to come on microformats in the near future here.
Upcoming has gone to Yahoo!
Yahoo gets Upcoming.org. I think this is a great move on Yahoo's part as the tool Upcoming has been building is one of the best event calendar tools on the web. Hopefully it will help replace the event components in Yahoo! calendar and help Yahoo open up their calendar to read in iCal, vCal, RSS, etc. Oh, and spit out the same to use in what ever other tool somebody needs that information.
Congrats to the Upcoming guys for joining a great team.
Yahoo! MyWeb Imports Del.icio.us Bookmarks and More Observations
Yesterday's post, MyWeb 2 Grows Up Quickly into a Usable Tool, had part of my answer delivered today by e-mail. Yahoo! had already built a del.icio.us import tool (as well as an Internet Explorer bookmark, Yahoo bookmark, and RSS import tools) to grab your bookmarks and tags out from del.icio.us.
My import went well, um it took four attempts to get all 1,440 of my bookmarks into Yahoo MyWeb 2, but they are all there along with the 20 or so I had stored in MyWeb already. I wish it could have kept the dates from my del.icio.us bookmarks as the time puts those links in context for me with other things I was working on at the time I made the bookmark.
I am not abandoning my del.icio.us bookmarks and will keep feeding it as it is my only easy option at work at the moment. Now I am interested in a JavaScript bookmark that would post to both MyWeb and del.icio.us from the same form. There is community around one's social bookmarks as I know there are people that pull my del.icio.us bookmark feed into their aggregator, just I do that with other's bookmarks. This is part of their being social, yes?
Now I want to play with MyWeb with my 1,459 plus pages in it. As a personal bookmarking tool this will be a good test. I am now also curious with searching with Yahoo! if my own bookmarks will appear on the search page. This would be nice as I found Google somewhat scary when I started seeing my own blog posts showing up in searches I was doing from work. But, I started my blog (nearly five years ago) as a note to self tool, which also happened to be open to everybody else in the world. It is my outboard memory. This is also the reason I started my own personal site nearly 10 years ago, as a link tool so I could keep access to my web links from any web connection I could get. A lot has changed in these nearly 10 years, but so much has stayed the same.
I have a laundry list of interface changes I would love to see in MyWeb that I will be shooting to them that are interface related. I also have many social network improvements for their tool to get more fine grained in their connections between people in the social engine, which may take more than just a few e-mails.
MyWeb 2 Grows Up Quickly into a Usable Tool
Earlier this week I chose to use Yahoo! search rather than the default Google that I usually use. The search page on Yahoo! had sponsored links at the top of the page, but then a few other offerings followed by the usual offerings. The second set was dead on what I was seeking. What were these second set of links? They were the results of those in "My Community" in MyWeb 2 Search, which is similar to del.icio.us in that it is a social bookmarking tool with tagging.
This discovery from a community of less than 40 people really surprised me. Of those 40 people less than 15 have more than 5 pages they have bookmarked, but this community is one I share interests and vocabulary. I was partial shocked with amazement as when MyWeb 2 launched in beta a few weeks ago (or a few months at this point) I was completely under whelmed as most of the links in MyWeb 2 were for things I not only had not interest in, but did not care to have recommended.
As the net effect of more people adding their bookmarks to this socially shared tool grew the value of the tool increased. As it grows I am positive it the aspects of my community will need to get more fine grained so I can say I like the tags from person X (similar to the granular social network which would make better use of the social network for recommender systems that actually could be used and trusted). One of the benefits of MyWeb 2 is that it gets layered on top of Yahoo's search results, which is a great place for this information.
I would love to replicate my del.icio.us bookmarks and tags into MyWeb 2 at Yahoo. The next step would be to feed both systems at the same time from one central interface. There are things in del.icio.us that I really like, but the layering of the social bookmarking and with tagging on top of other tools adds greater value to the user.
User Experience Design in the Come to Me Web?
A question came up with Rashmi in the week prior to the BayCHI Web 2.0 event that I thought would definitely come up at the panel in the Q&A session, but most of the questions related to the application and technology side of things.
As content can be repurposed in and pulled into various tools with drastically different presentations than the sites they sit within. There seems to be a logical question as to the value of the user experience of the initial site. We are spending a lot of time, effort, and resources building optimal user experience, but with more and more of the content being consumed in interfaces that do not use the user experience should we spend less time and resources on perfecting it?
One answer is no, things are fine the way they are as the people that still consume the information in the traditional web manner (is it too early to call it traditional web manner?) are a narrower audience than the whole of the people consuming the information. The design of the site would have to add value, or provide additional service to continue enticing people back. I have been talking about the Perceptual Receptor in the Model of Attraction for a few years and the sensory components of design, look, and appeal should be targeted to the expected users so it fits their expectations and they are attracted to the content they are seeking in a manner that is appealing to them.
The converse to this is we are spending too much time on the ephemeral in relation to the benefit. With increasing consumption of the information done though RSS/ATOM feed readers and aggregators on the desktop, mobile, or web (as in Bloglines or My Yahoo) interfaces, which nearly all strip the presentational layers and just deliver the straight content with the option for the person to click and get to the site we developed. Information is also pulled together in other aggregators as summaries on various websites and versions e-mailed around. The control of the user experience has drifted away from the initial designer and is in the hands of the tools aggregating (some provide presentational layers from the content owners to show through on the aggregators), or the people consuming the information that choose their own presentation layer or just strip it for other uses.
With content presentations in the hands of the people consuming and not the crafting designer how does branding come through? How does the richer integrated interface we spent months designing, testing, and carefully tweaking? Branding with logos may be easier than the consistent interface we desire as the person consuming the content has a different idea of consistent interface, which is the interface they are consuming all of the information in. People have visual patterns they follow in an application and that interface helps them scan quickly for the information they desire.
Where the content creator puts their content out for aggregation in XML related feeds, they have made a decision at some level that having their content in the hands of more people who want it is more important than a unified user experience. Consumption of the media has a greater impact than fewer people consuming a preferred experience. All of the resources we put into the refined user experience is largely for the user's benefit, or at least that is what we say, but it is also for the business benefit for consistent branding and imprinting. The newer consumption models focus on the person and their getting the information and media they want in the easiest and their preferred manner for that person.
Is there an answer? One single answer, most likely not. But, I personally don't think we and crafting designer have a great say at this point. As tools people use mature, we may get more control, but optimally the person consuming is the one in control as they want to be and should in the "come to me web".
Speaking at BayCHI August 9th
I will be in the San Francisco Bay Area August 9, 2005 to speak on the BayCHI - Are you ready for Web 2.0? panel. This will be at the PARC's George E. Pake Auditorium (formerly known as Xerox PARC). I am looking forward to the panel and being back in the Bay Area.
Did I mention I am only on the ground for 12 hours? I am flying in from vacation on the New Jersey Shore, but it will be worth it. I have a couple places I need to stop, but shoot me e-mail to meet-up or let me know you will be going to the panel. I have a long string of things to get to in the Bay Area that have been building since January, but this will not be the trip to knock all of them out.
I really need to get to the Bay Area more often, it is home (well where I was born and spent much of my life there).
Say Hey - If I Knew
I have a deep love of digital technology as an assistive devise and even an enabling device. But, I need something that sits between the digital and the real so to join those worlds.
Here is the problem... I am continually not blanking at who somebody I know in a digital context (through e-mail, a social networking tool (one that works), listserves, blogs, etc.), but their face or just lack of some means of connecting those I know to who they are physically. It continually happens at conferences or when traveling. This happened three times to me at WebVisions with Matt May, Erin Kissane, and Kris Krug. With all three it took some time before it clicked, fortunately with Matt it clicked while I still had time to draw the lines. I would have loved to have chatted with Erin and Kris with the context of how I know them firmly in place. Part of the problem it did not register to me that they were going (I am not sure I checked close enough to the event Upcoming to see who was going to I could make a mental note (or otherwise) to say hey.
What would the solution be? The gap between digital and physical must close. I need my address book crossed with my digital social networks and get all of the pieces tied together with one identity that I can track. Sure everybody can keep their 16 screen names across different communities, but we need to aggregate those to one identity when it makes sense, such as meeting in person. I have been told Sxip can handle this, but I have not had the time to track that down.
The next step is to take the aggregated identity and go through events I am attending or places traveling and let me know who will be there. I am not see this as a privacy issue as there are established friend relationships and set with parameters of securely allowing access to our information, or it has be made public. I usually have a mental list of who I want to see and talk to prior to events, but that group is growing. There is also a group of people I normally only see at events and I always try to hang with that "floating island", but I am usually in contact with them long before.
It seems like a tool like Upcoming would be a perfect place to do this for a large chunk of events. It will still take aggregating the identities across all of the digital communities I belong, address books, and in-person communities. I would love for the next step to include an application in my mobile device that tipped me off to somebody on my friendly "say hey" list being with in "hey" range.
Yahoo MyWeb 2.0 Goes Beta
Yahoo has launched Yahoo MyWeb 2.0 today. It has elements of Flickr but not the polish, nor the attention to detail. There are a lot of very rough edges, but there is a lot of potential also. I may spend some time playing around with it in the next few days and weeks. I surely will be sending a ton of feedback in. Hopefully MyWeb will iterate far more rapidly than their blogging software, which had rough edges and they still exist and no noticeable improvements have been made (I don't know many that will recommend it to nubies until the rough edges are fixed).
The tool from the very little I have looked at it seems like it has the broad folksonomy executed well. This seems to have many elements of del.icio.us integrated. I am curious is there is the capability to have community around tags (be same definition).
My curiosity is really piqued with the MyRank search engine. It seems to be a predictive engine of sorts, which really has my interest.
If you want to add me I can be found at tjvanderwal there in Yahoo! type places.
Response to Usability of Feeds
Jeffrey Veen has a wonderful post about the usability of RSS/Atom/feeds on his site. I posted a response that I really want to keep track of here, so it follows...
I think Tom's pointer to the BBC is a fairly good transition to where we are heading. It will take the desktop OS or browser to make it easier. Neither of these are very innovative or quickly adaptive on the Windows side of the world.
Firefox was the first browser (at least that I know of) to handle RSS outside the browser window, but it was still done handled in a side-window of the browser. Safari has taken this to the next step, which is to use a mime-type to connect the RSS feed to the desktop device of preference. But, we are still not where we should be, which is to click on the RSS button on a web page and dump that link into ones preferred reader, which may be an application on the desktop or a web/internet based solution such as Bloglines.
All of this depends on who we test as users. Many times as developers we test in the communities that surround us, which is a skewed sample of the population. If one is in the Bay Area it may be best to go out to Stockton, Modesto, Fresno, or up to the foothills to get a sample of the population that is representative of those less technically adept, who will have very different usage patterns from those we normally test.
When we test with these lesser adept populations it is the one-click solutions that make the most sense. Reading a pop-up takes them beyond their comfort zone or capability. Many have really borked things on their devices/machines by trying to follow directions (be they well or poorly written). Most only trust easy solutions. Many do not update their OS as it is beyond their trust or understanding.
When trends start happening out in the suburbs, exurbs, and beyond the centers of technical adeptness (often major cities) that is when they have tipped. Most often they tip because the solutions are easy and integrated to their technical environment. Take the Apple iPod, it tipped because it is so easy to set up and use. Granted the lack of reading is, at least, an American problem (Japanese are known to sit down with their manuals and read them cover to cover before using their device).
We will get to the point of ease of use for RSS and other feeds in America, but it will take more than just a text pop-up to get us there.
The Art of the Pivot
We live life linearly, but there are many tangents and crossing points. Physical life makes surfing those tangents not an easy task, but it is part of the brilliance of digital life to surf serendipitously with purpose. Every now and then, with more increasing regularity I find myself in awe (yet with each occurrence with banality creeping in) of the tangential currents that draw life closer and the world smaller.
Flickr provided this evening's wonderful spark. While peering through the lens of my friends and "contacts" photos I clicked on one that had a familiar scene, it was not that I knew the people in the photo, but it was the table, cups, and feel of the place. It was a photo in the Pork Store on Haight Street. I have had so many wonderful breakfasts there from when I live behind the restaurant on Waller, to trekking over from where I lived on Arguello, to the pilgrimage on nearly every trip I make to San Francisco.
What made this particular photo special was not that I easily recognized the scene, but I double checked in Flickr's tags to see a "porkstore" tag. I clicked the tag to see if that photographer had entered more photos in the Pork Store, but no. I clicked to see "all other public photos tagged with porkstore". In doing this I saw in the thumbnail somebody I thought I recognized. I clicked to the larger photo to ensure it was somebody I had just met yesterday. The world just shrunk.
What was the point of this? It is the ability to pivot or surf in new direction that is related to where we are all thanks to the hyperlink and meta information. As the web has changed my perception of what is right and possible in the world, I increasingly find one of the major differentiators between physical life and digital experiences is the pivot. Including hyperlinks or means to pull information closer to you that is tangential to the current desire or direction. When relevant information is not hyperlinked it is lacking the pivot. Or when there is a lack of ease to find associated information that is relevant to what is in the browser and relevant to the person consuming the information or object on their screen it is frustrating for the user and disappointing as a developer knowing the ease of the solution and the great value it adds.
Oddly, one of the interfaces I love also bothers me for its lack of the pivot. The iPod is great, but it is missing one pivot option that is now driving me nuts. When in Shuffle mode and I hear a song I like by an artist I like often want to pivot and listen to more of that artist or that album. This should be an option on the center button, just like getting to add song rating, scroll through the song, etc. Not only is it in Shuffle mode it is when listening to mixed playlists or soundtracks. It should not be that difficult to implement, one of the screens clicked to from the center button, while listening to a song, should bring up a "listen to more by this artist or album" option. Then life would be so much better.
Opening Old Zips and Finding Missing Passion
Tonight I finally got my old USB Zip drive to work with my laptop (I have not tried in a couple years) and it worked like a charm. I decided to pull most of the contents of my old Zips into my hard drive, as it is backed-up.
I started opening old documents from a project from four and five years ago and the documentation is so much better and detailed that what I have these days. The difference? Focus and resources. On that project I was researching, defining, iterating, and testing one project full-time. I was working with some fantastic developers that were building their parts and a designer that could pulled everything together visually. We each had our areas of expertise and were allowed to do what we enjoyed and excelled at to the fullest. Our passions could just flow. The project was torn apart by budgets and politics with the real meat of it never going live. A small piece of it went live, but nothing like we had up and running. But, this is the story of so many killer projects and such is life.
What is different between now and then? Today there is no focus and no resources to develop and design. I am in an environment overseeing 2,000 projects a year across 15 funding areas (most of the work done centrally is done on 5 funding areas), it is project traffic management, not design, not research design, not iterating, just balancing high priority projects (mostly it is 9 of us cleaning up others poor work). The team I work with is fantastic, but we have few resources (mostly time is missing) to do incredible work.
The looking back at the volumes of documents I wrote laying out steps, outlines of design elements, content assessments, schematics, data flows, wireframes, and Flash animations demonstrating how the finished tools would function I realize I miss that, deeply. I miss the passion and drive to make something great. I miss being permitted to dream big and solve problems that were untouchable, and best of all, go execute on those dreams. When I see members that made up that old team we reminisce, much like guys do about high school sports champion teams they were on. We had a great team with each of us doing what we loved and changing our part of the world, the digital world.
It was in that project that the seeds were planted for everything I love working on now. Looking at old diagrams I see hints of the Model of Attraction. I was using scenarios around people using and reusing information, which became the Personal InfoCloud. These elements were used to let others in on our dreams for that project and it was not until my time on the project was winding down (or there was no desire to move more of the whole product live and therefore no need for my skills) that I could pull out what worked well on project that made it special. Now others are getting to understand the Personal InfoCloud and other frameworks and models I have been sharing.
State is the Web
The use and apparent mis-use of state on the web has bugged me for some time, but now that AJAX, or whatever one wants to call "XMLHttpRequests", is opening the door to non-Flash developers to ignore state. The latest Adaptive Path essay, It's A Whole New Internet, quotes Michael Buffington, "The idea of the webpage itself is nearing its useful end. With the way Ajax allows you to build nearly stateless applications that happen to be web accessible, everything changes." And states, "Where will our bookmarks go when the idea of the 'webpage' becomes obsolete?"
I agree with much of the article, but these statements are wholly naive in my perspective. Not are they naive, but they hold up examples of the web going in the wrong direction. Yes, the web has the ability to build application that are more seemless thanks to the that vast majority of people using web browsers that can support these dynamic HTML techniques (the techniques are nothing new, in fact on intranets many of us were employing them four or five years ago in single browser environments).
That is not the web for many, as the web has been moving toward adding more granular information chunks that can be served up and are addressible. RESTful interfaces and "share this page" links are solutions. The better developers in the Flash community has been working to build state into their Flash presentations to people can link to information that is important, rather than instructing others to click through a series of buttons or wait through a few movies to get to desired/needed information. The day of one stateless interface for all information was behind us, I hope to hell it is not enticing a whole new generation of web developers to lack understanding of state.
Who are providing best examples? Flickr and Google Maps are two that jump to mind. Flickr does one of the best jobs with fluid interfaces, while keeping links to state that is important (the object that the information surrounds, in this case a photograph). Google Maps are stunning in their fluidity, but during the whole of one's zooming and scrolling to new locations the URL remains the same. Google Map's solution is to provide a "Link to this page" hyperlink (in my opinion needs to be brought to the visual forefront a little better as I have problems getting people to recognize the link when they have sent me a link to maps.google.com rather than their intended page).
Current examples of a poor grasp of state is found on the DUX 2005 conference site. Every page has the same URL, from the home page, to submission page, to about page. You can not bookmark the information that is important to yourself, nor can you send a link to the page your friend is having problems locating. The site is stateless in all of its failing glory. The designer is most likely not clueless, just thoughtless. They have left out the person using the site (not users, as I am sure their friends whom looked at the design thought it was cool and brilliant). We have to design with people using and resusing our site's information in mind. This requires state.
When is State Helpful?
If you have important information that the people using your site may want to directly link to, state is important as these people will need a URL. If you have large datasets that change over time and you have people using the data for research and reports, the data must have state (in this case it is the state of the data at some point in time). Data that change that does not have state will only be use for people that enjoy being selected as a fool. Results over time will change and all good academic research or professional researchers note the state of the data with time and date. All recommendations made on the data are only wholly relevant to that state of the data.
Nearly all blogging tools have "permalinks", or links that link directly to an unchanging URL for distinct articles or postings, built into the default settings. These permalinks are the state function, as the main page of a blog is fluid and ever changing. The individual posts are the usual granular elements that have value to those linking to them (some sites provide links down to the paragraph level, which is even more helpful for holding a conversation with one's readers).
State is important for distinct chunks of information found on a site. Actions do not seem state-worthy for things like uploading files, "loading screens", select your location screens (the pages prior and following should have state relative to the locations being shown on those pages), etc.
The back button should be a guide to state. If the back button takes the user to the same page they left, that page should be addressable. If the back button does not provide the same information, it most likely should present the same information if the person using the site is clicking on "next" or "previous". When filling out an application one should be able to save the state of the application progress and get a means to come back to that state of progress, as people are often extremely aggravated when filling out longs forms and have to get information that is not in reach, only to find the application times out while they are gone and they have to start at step one after being many steps into the process.
State requires a lot of thought and consideration. If we are going to build the web for amateurization or personal information architectures that ease how people build and structure their use of the web, we must provide state.
Personal InfoCloud at WebVisions 2005
I, Thomas Vander Wal, will be presenting the Personal InfoCloud at the WebVisions 2005 in Portland, Oregon on July 15th. In all it looks to be a killer conference, just as it has been in the past. This year's focus is convergence (it is about time).
WebVisions is one of the best values in the web conference industry these days, as the early bird pricing is just $85 (US). You don't need an excuse, you just go. You spend a Friday bettering yourself and then Saturday in Powell's Books the evenings are spent talking the talk over some of the world's best beers served up fresh.
Yahoo360 and the Great Interaction Design Yardstick
Jeremy Zawodney talks about a Yahoo preview of Yahoo360 to which they invited "influencers" to provide honest feedback (Danah Boyd provides her wonderful view too).
What I really like about Jeremy's post is the repeated reference to Flickr when explaining things. The key thing is that Flickr (yes it is now owned by Yahoo) knocks the snot of of other's interaction design. Flickr set the standard and it is what many other web-based products are truly lacking. Getting the interface and interaction right is not half the battle, it is the battle. So few do it well and very few execs around the industry get that. What is lacking in so many products is design that creates, not just an ease of use, but a fun successful experience.
Flickr makes refindability of the pictures a person posts much easier by using tags that make sense to the person providing the tags. The interface for providing the tags is simple and does not take the user away from the interface (thanks to Ajax). The rest of the options are done simply from a person using the site's perspective. Everybody I know gets completely immersed in Flickr. This is something I can not say about Ofoto or other photo sharing sites, one goes to these sites to see the pictures somebody you know has taken. Flickr can be the most efficient photo sharing tool for uploading and managing one's own photos too.
Simply it is make things easy to accomplish tasks, focussing on what the person wants and need from the product. Accomplish this feat at the same time make it fun. There is no harm in making life enjoyable.
Outside of the 3rd World, Yahoo Buys Flickr
Once again we are back into living in the third world. It is the first day of Spring and we got a lightning storm and out goes the power. We have this to look forward to until Fall. Well, unless we move.
Once the power came on it was errand time, then time shout congratulations to Flickr and Yahoo!. The news was officially announced, that Yahoo! bought Flickr. The Flickr team is staying intact and in Vancouver. Flickr is one of the kick-ass products on the Web right now and with Yahoo! support it could stay at the forefront.
Folksonomy Fixed in Wikipedia
It looks like somebody finally fixed Wikipedia entry for Folksonomy, it no longer makes the mistake of calling the a folksonomy a blend of folks and taxonomy. The taxonomy has connotations of being formally structured, which as far from what is going on in del.icio.us from what I see, as the user's of del.icio.us can free tag and choose what ever they wish to tag an object with
Bless you, whom ever fixed this. It looks like it was done today. I have tried to get this fixed before, but my change was bounced, I guess I did not know enough about folksonomies. There is a lot more in the entry that has been added, including the semantic derivation. Thanks to whom ever is getting it right, finally.
This gives me less to complain about Wikipedia than I had before (I have watched entries go from being correct to wrong and stay wrong for quite some time). A co-worker stated Wikipedia is stated to be the current day Hitchhickers Guide to the Galaxy, which was wrong in spots to mortal detriment at times. I somewhat agree, although a little less so today.
Explaining and Showing Broad and Narrow Folksonomies
I have been explaining the broad and narrow folksonomy in e-mail and in comments on others sites, as well as in the media (Wired News). There has still been some confusion, which is very understandable as it is a different concept that goes beyond a simple understanding of tagging. I have put together a couple graphics that should help provide a means to make this distinction some what clearer. The folksonomy is a means for people to tag objects (web pages, photos, videos, podcasts, etc., essentially anything that is internet addressable) using their own vocabulary so that it is easy for them to refind that information again. The folksonomy is most often also social so that others that use the same vocabulary will be able to find the object as well. It is important to note that folksonomies work best when the tags used to describe objects are in the common vocabulary and not what a person perceives others will call it (the tool works like no other for personal information management of information on the web, but is also shared with the world to help others find the information).
Broad Folksonomy
Let's begin with the broad folksonomy, as a tool like del.icio.us delivers. The broad folksonomy has many people tagging the same object and every person can tag the object with their own tags in their own vocabulary. This lends itself very easy to applying the power law curve (power curve) and/or net effect to the results of many people tagging. The power terms and the long tail both work.
The broad folksonomy is illustrated as follows. 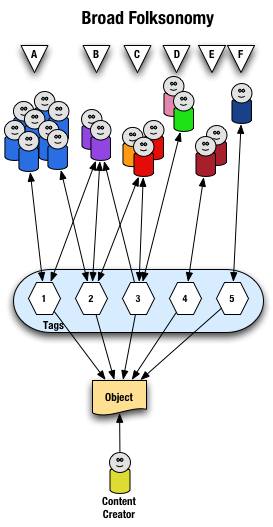
From a high level we see a person creates the object (content) and makes it accessible to others. Other people (groups of people with the same vocabulary represented people blobs and noted with alphabet letters) tag the object (lines with arrows pointing away from the people) with their own terms (represented by numbers). The people also find the information (arrows on lines pointing from the numeric tags back to the people blobs) based on the tags.
Digging a little deeper we see quite a few people (8 people) in group "A" and they have tagged the object with a "1" and a "2" and they use this term to find the object again. Group "B" (2 people) have applied tag "1" and "2" to the object and they use tag terms "1", "2", and "3" to find the information. Group "C" (3 people) have tagged the object with "2" and "3" so that they can find the object. Group "D" has also tagged the object with tag "3" so that they may refind the information this group may have benefitted from the tagging that group "C" provided to help them find the information in the first place. Group "E" (2 people) uses a different term, "4", to tag the object than others before it and uses only this term to find the object. Lastly, group "F" (1 person) uses tag "5" on the object so that they may find it.
Broad Folksonomy and the Power Curve
The broad folksonomy provides a means to see trends in how a broad range are tagging one object. This is an opportunity to see the power law curve at work and show the long-tail.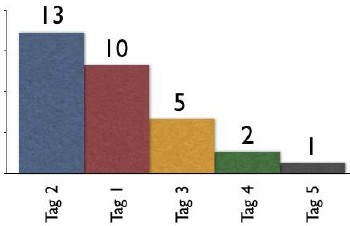
The tags spike with tag "2" getting the largest portion of the tags with 13 entries and tag "1" receiving 10 identical tags. From this point the trends for popular tags are easy to see with the spikes on the left that there are some trends, based on only those that have tagged this object, that could be used extract a controlled vocabulary or at least know what to call the object to have a broad spectrum of people (similar to those that tagged the object, and keep in mind those that tag may not be representative of the whole). We also see those tags out at the right end of the curve, known as the long tail. This is where there is a small minority of people who call the object by a term, but those people tagging this object would allow others with a similar vocabulary mindset to find the object, even if they do not use the terms used by the masses over at the left end of the curve. If we take this example and spread it out over 400 or 1,000 people tagging the same object we will se a similar distribution with even more pronounced spikes and drop-off and a longer tail.
This long tail and power curve are benefits of the broad folksonomy. As we will see the narrow folksonomy does not have the same properties, but it will have benefits. These benefits are non-existent for those just simply tagging items, most often done by the content creator for their own content, as is the means Technorati has done, even with their following tag links to destinations other than Technorati (as they initially had laid out). The benefits of the long tail and power curve come from the richness provided by many people openly tagging the same object.
Narrow Folksonomy
The narrow folksonomy, which a tool like Flickr represents, provides benefit in tagging objects that are not easily searchable or have no other means of using text to describe or find the object. The narrow folksonomy is done by one or a few people providing tags that the person uses to get back to that information. The tags, unlike in the broad folksonomy, are singular in nature (only one tag with the term is used as compared to 13 people in the broad folksonomy using the same tag). Often in the narrow folksonomy the person creating the object is providing one or more of the tags to get things started. The goals and uses of the narrow folksonomy are different than the broad, but still very helpful as more than one person can describe the one object. In the narrow the tags are directly associated with the object. Also with the narrow there is little way of really knowing how the tags are consumed or what portion of the people using the object would call it what, therefore it is not quite as helpful as finding emerging vocabulary or emergent descriptions. We do find that tags used to describe are also used for grouping, which is particularly visible and relevant in Flickr (this is also done in broad folksonomies, but currently not to the degree of visibility that it is done on Flickr, which may be part of the killer interactive environment Ludicorp has created for Flickr).
The narrow folksonomy is illustrated as follows.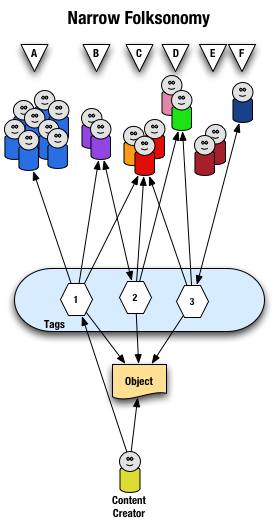
From a high level we see a person creates the object and applies a tag ("1") that represents what they call the object or believe describes the object. There are fewer tags provided than in a broad folksonomy and there is only one of each tag applied to the object. The consumers of the object also can apply tags that help them find the object or describe what they believe are the terms used to describe this object.
A closer look at the interaction between people and the object and tags in a narrow folksonomy shows us that group "A" uses tag "1" to find and come back to the object (did the creator do this on purpose? or did she just tag it with what was helpful to her). We see group "B" also using tag "1" to find the object, but they have tagged the object with tag "2" to also use as a means to find the object. Group "C" uses tag "1","2", and "3" to find the object and we also note this group did not apply any of its own tags to the object as so is only a consumer of the existing folksonomy. We see group "D" uses tags "2" and "3" to find the objects and it too does not add any tags. Group "E" is not able to find the object by using tags as the vocabulary it is using does not match any of the tags currently provided. Lastly, group "F" has their own tag for the object that they alone use to get back to the object. Group "F" did not find the object through existing tags, but may have found the object through other means, like a friend e-mailed them a link or the object was included in a group they subscribe to in their feed aggregator.
We see that the richness of the broad folksonomy is not quite there in a narrow folksonomy, but the folksonomy does add quite a bit of value. The value, as in the case of Flickr, is in text tags being applied to objects that were not findable using search or other text related tools that comprise much of how we find things on the internet today. The narrow folksonomy does provide various audiences the means to add tags in their own vocabulary that will help them and those like them to find the objects at a later time. We are much better off with folksonomies than we were with out them, even if it is a narrow folksonomy being used.
Conclusion
We benefit from folksonomies as the both the personal vocabulary and the social aspects help people to find and retain a tether to objects on the web that are an interest to them. Who is doing the tagging is important to understand and how the tags are consumed is an important factor. This also helps us see that not all tagging is a folksonomy, but is just tagging. Tagging in and of its self is a helpful step up from no tagging, but is no where near as beneficial as opening the tagging to all. Folksonomy tagging can provide connections across cultures and disciplines (an knowledge management consultant can find valuable information from an information architect because one object is tagged by both communities using their own differing terms of practice). Folksonomy tagging also makes up for missing terms in a site's own categorization system/taxonomy. This hopefully has made things a little clearer for all in our understanding the types of folksonomies and tagging and the benefits that can be derived.
This entry first appeared at Personal InfoCloud and comments are open for your use there.
Technorati Opens Spam Tagging - Updated
The talk this past week was all about Technorati and their tagging tool, but the tool offers very little value and may be an incubator for spam more than a folksonomy tool.
Where del.icio.us gets folksonomy right (I know this is reflexive) by having many people tag online objects, Technorati gets folksonomy backwards with one user spitting tags into an aggregator. The only link I would trust in Technorati's tool is one that I also found on del.icio.us.
Why so harsh? Technorati has created a tool not from social interaction and using the internet to build value through the network effect (Technorati made the power curve popular, which is the visualization of the net effect). Technorati has no moderating the content that can be dumped in my any slimy spammer that now has a ripe new target. Lacking moderation and any socially derived checks to the system I am quite disappointed with Technorati and this effort.
I use Technorati keywords to track things I have an interest in and their tool does a great job pulling in information (I also use Feedster for the same purpose) and find it to be the top of its class in this effort.
Updated
Eric Scheid provides an excellent suggestion, which made me realize it is easy for Technorati to get it right and much of my problem was the links went in the wrong direction. Eric states...
I have a suggestion for another link format for "technorati" tags which would turn things around ... it would look like this:
<a href="http://whatever.bloghost.com/page/etc" rel="tag.TAGNAME1 tag.TAGNAME2">descriptive text for the link</a>This way I can tag the pages I *link* to, and not just the pages I publish.
I'm also able to assign multiple tags to the linked page, and of course since other people could well be linking to that same page they can apply their own tags too. Think of the social tagging nature of del.icio.us without the intermediary of del.icio.us.
All we need is the "tag." prefix to identify the tagging relationship, as distinct from other relationship types (eg. vote-for, XFN, the usual W3C things, etc).
Yes, this modification would make Technorati tags a true folksonomy. Will they fix it to get it right?
Flickr and the Future of the Internet
Peter's post on Flickr Wondering triggers some thoughts that have been gelling for a while, not only about what is good about Flickr, but what is missing on the internet as we try to move forward to mobile use, building for the Personal InfoCloud (allowing the user to better keep information the like attracted to them and find related information), and embracing Ubicomp. What follows is my response to Peter's posting, which I posted here so I could keep better track of it. E-mail feedback is welcome. Enjoy...
You seemed to have hit on the right blend of ideas to bring together. It is Lane's picture component and it is Nadav's integration of play. Flickr is a wonderfully written interactive tool that adds to photo managing and photo sharing in ways that are very easy and seemingly intuitive. The navigations is wonderful (although there are a few tweak that could put it over the top) and the integration of presentational elements (HTML and Flash) is probably the best on the web as they really seem to be the first to understand how to use which tools for what each does best. This leads to an interface that seems quick and responsive and works wonderfully in the hands of many. It does not function perfectly across platforms, yet, but using the open API it is completely possible that it can and will be done in short order. Imagine pulling your favorites or your own gallery onto your mobile device to show to others or just entertain yourself.
Flickr not only has done this phenomenally well, but may have tipped the scales in a couple of areas that are important for the web to move forward. One area is an easy tool to extract a person's vocabulary for what they call things. The other is a social network that makes sense.
First, the easy tool for people to add metadata in their own vocabulary for objects. One of the hinderances of digital environments is the lack of tools to find objects that do not contain words the people seeking them need to make the connection to that object they are desiring. Photos, movies, and audio files have no or limited inherent properties for text searching nor associated metadata. Flickr provides a tool that does this easily, but more importantly shows the importance of the addition of metadata as part of the benefit of the product, which seems to provide incentive to add metadata. Flickr is not the first to go down this path, but it does it in a manner that is light years ahead of nearly all that came before it. The only tools that have come close is HTML and Hyperlinks pointing to these objects, which is not as easy nor intuitive for normal folks as is Flickr. The web moving forward needs to leverage metadata tools that add text addressable means of finding objects.
Second, is the social network. This is a secondary draw to Flickr for many, but it is one that really seems to keep people coming back. It has a high level of attraction for people. Part of this is Flickr actually has a stated reason for being (web-based photo sharing and photo organizing tool), which few of the other social network tools really have (other than Amazon's shared Wish Lists and Linkedin). Flickr has modern life need solved with the ability to store, manage, access, and selectively share ones digital assets (there are many life needs and very few products aim to provide a solution for these life needs or aims to provide such ease of use). The social network component is extremely valuable. I am not sure that Flickr is the best, nor are they the first, but they have made it an easy added value.
Why is social network important? Helping to reduct the coming stench of information that is resultant of the over abundance of information in our digital flow. Sifting through the voluminous seas of bytes needs tools that provide some sorting using predictive methods. Amazon's ratings and that matching to other's similar patterns as well as those we claim as our friends, family, mentors, etc. will be very important in helping tools predict which information gets our initial attention.
As physical space gets annotated with digital layers we will need some means of quickly sorting through the pile of bytes at the location to get a handful that we can skim through. What better tool than one that leverages our social networks. These networks much get much better than they are currently, possibly using broader categories or tags for our personal relationships as well as means of better ranking extended relationships of others as with some people we consider friends we do not have to go far in their group of friends before we run into those who we really do not want to consider relevant in our life structures.
Flickr is showing itself to be a popular tool that has the right elements in place and the right elements done well (or at least well enough) to begin to show the way through the next steps of the web. Flickr is well designed on many levels and hopefully will not only reap the rewards, but also provide inspiration to guide more web-based tools to start getting things right.
Web 2.0: Source, Container, Presentation
At Web 2.0 Jeff Bezos, of Amazon stated, "Web 2.0 is different. It's about AWS (Amazon Web Services). It's not on the web site for users to see. It's about making the internet useful for computers.". This is very appropriate today as it breaks the information model into at least three pieces: source, container, and presentation. Web 1.0 often had these three elements in one place, which really made it difficult to reuse the information, but even use it at times.
The source is the raw information or content from the creator or main distributor. The container is the means of transporting the information or content. The container can be XML, CSV, text, XHTML, etc. The presentation is what is used to make the information or content human consumable. The presentation can be HTML with CSS, Flash, PDF, feed reader, mobile application, desktop application, etc.
The importance of the three components is they most valuable when they stand alone. Many problems and frustrations for people trying to get information and reuse it off the web has been there has not been a separation of the components. Take most Flash files, which tie the container and the presentation in one object that is proprietary and can be extremely difficult to extract the information for reuse. The same also applies to PDF files as they too are less than optimal for sharing information for anything other than reading, if the PDF can be read on the device. As mobile use of the internet increases the separation is much more valuable. The separation has always been the smart thing to do.
Today Google launched a beta of their Google SMS for mobile devices. The service takes advantage of the Google web services (source) and allows mobile users to send a text message with a query (asking "pizza" and providing the zip code) and Google responds with a text message with information (local pizzerias with their address and phone numbers). The other day Tantek demonstrated Semantic XHTML as an API, which provides openly accessible information that is aggregated and reused with a new presentation layer, Flash.
More will follow on this topic at some point in the not too distant future, once I get sleep.
Feed On This
The "My" portal hype died for all but a few central "MyX" portals, like my.yahoo. Two to three years ago "My" was hot and everybody and their brother spent a ton of money building a personal portal to their site. Many newspapers had their own news portals, such as the my.washingtonpost.com and others. Building this personalization was expensive and there were very few takers. Companies fell down this same rabbit hole offering a personalized view to their sites and so some degree this made sense and to a for a few companies this works well for their paying customers. Many large organizations have moved in this direction with their corporate intranets, which does work rather well.
Where Do Personalization Portals Work Well
The places where personalization works points where information aggregation makes sense. The my.yahoo's work because it is the one place for a person to do their one-stop information aggregation. People that use personalized portals often have one for work and one for Personal life. People using personalized portals are used because they provide one place to look for information they need.
The corporate Intranet one place having one centralized portal works well. These interfaces to a centralized resource that has information each of the people wants according to their needs and desires can be found to be very helpful. Having more than one portal often leads to quick failure as their is no centralized point that is easy to work from to get to what is desired. The user uses these tools as part of their Personal InfoCloud, which has information aggregated as they need it and it is categorized and labeled in a manner that is easiest for them to understand (some organizations use portals as a means of enculturation the users to the common vocabulary that is desired for use in the organization - this top-down approach can work over time, but also leads to users not finding what they need). People in organizations often want information about the organization's changes, employee information, calendars, discussion areas, etc. to be easily found.
Think of personalized portals as very large umbrellas. If you can think of logical umbrellas above your organization then you probably are in the wrong place to build a personalized portal and your time and effort will be far better spent providing information in a format that can be easily used in a portal or information aggregator. Sites like the Washington Post's personalized portal did not last because of the cost's to keep the software running and the relatively small group of users that wanted or used that service. Was the Post wrong to move in this direction? No, not at the time, but now that there is an abundance of lesson's learned in this area it would be extremely foolish to move in this direction.
You ask about Amazon? Amazon does an incredible job at providing personalization, but like your local stores that is part of their customer service. In San Francisco I used to frequent a video store near my house on Arguello. I loved that neighborhood video store because the owner knew me and my preferences and off the top of his head he remembered what I had rented and what would be a great suggestion for me. The store was still set up for me to use just like it was for those that were not regulars, but he provided a wonderful service for me, which kept me from going to the large chains that recorded everything about me, but offered no service that helped me enjoy their offerings. Amazon does a similar thing and it does it behind the scenes as part of what it does.
How does Amazon differ from a personalized portal? Aggregation of the information. A personalized portal aggregates what you want and that is its main purpose. Amazon allows its information to be aggregated using its API. Amazon's goal is to help you buy from them. A personalized portal has as its goal to provide one-stop information access. Yes, my.yahoo does have advertising, but its goal is to aggregate information in an interface helps the users find out the information they want easily.
Should government agencies provide personalized portals? It makes the most sense to provide this at the government-wide level. Similar to First.gov a portal that allows tracking of government info would be very helpful. Why not the agency level? Cost and effort! If you believe in government running efficiently it makes sense to centralize a service such as a personalized portal. The U.S. Federal Government has very strong restriction on privacy, which greatly limits the login for a personalized service. The U.S. Government's e-gov initiatives could be other places to provide these services as their is information aggregation at these points also. The downside is having many login names and password to remember to get to the various aggregation points, which is one of the large downfalls of the MyX players of the past few years.
What Should We Provide
The best solution for many is to provide information that can be aggregated. The centralized personalized portals have been moving toward allowing the inclusion of any syndicated information feed. Yahoo has been moving in this direction for some time and in its new beta version of my.yahoo that was released in the past week it allows the users to select the feeds they would like in their portal, even from non-Yahoo resources. In the new my.yahoo any information that has a feed can be pulled into that information aggregator. Many of us have been doing this for some time with RSS Feeds and it has greatly changed the way we consume information, but making information consumption fore efficient.
There are at least three layers in this syndication model. The first is the information syndication layer, where information (or its abstraction and related metadata) are put into a feed. These feeds can then be aggregated with other feeds (similar to what del.icio.us provides (del.icio.us also provides a social software and sharing tool that can be helpful to share out personal tagged information and aggregations based on this bottom-up categorization (folksonomy). The next layer is the information aggregator or personalized portals, which is where people consume the information and choose whether they want to follow the links in the syndication to get more information.
There is little need to provide another personalized portal, but there is great need for information syndication. Just as people have learned with internet search, the information has to be structured properly. The model of information consumption relies on the information being found. Today information is often found through search and information aggregators and these trends seem to be the foundation of information use of tomorrow.
Webmonkey Comes Back To Life
Oddly, Webmonkey seems to have come back to life today. There is a new articles on Contribute2 dated June 18, 2004. Just below that is a note stating it is back alive and kicking (not dated). Anybody have the scoop?
Amazon Plog
Amazon is offering a "Plog" (personalized weblog) of offerings and order information as my front page to their site. I have a link to an order and offerings, which tell me what I rated or ordered in the past to get the offering.
I sort of like this front page as it has the info I am interested in, particularly why I am recommended a product and order info. I am not a fan of the "Plog" moniker. It is too much trying to "be" something, which it is not. Now if they could not return Dummies books when I search for DVDs or CDs.
E-mail I Can Use
I picked up a Gmail account over this long weekend. What , how did I get it? I bought it. Yes, I know they are free and I know it is still in beta. Yes, I got it from an auction site. No I do not think I am crazy.
- I subscribe to a lot of lists and I also get an incredible amount of e-mail to my personal address
- I do not have external SMPT access during the work day to post queries to lists or to quickly respond to mail.
- I did not have a Web mail account that allowed me to search or organize the e-mail as I wanted (searching through months if not years of list services is very helpful)
- I wanted to make sure I got a specific name
- I can use my mobile account to deal with personal e-mail and forward all other e-mail to Gmail
- I don't mind the advertising and having targeted ads is better than the garbage I don't care about
So far I am quite impressed with the interface. There are some things with the application that I was not expecting, such as spelling. I was also not expecting the labels for e-mails rather than silly folders. The labels allow for more than one category for each e-mail and the mail is not buried in a folder somewhere.
Amazon Offers Alexa Augmented Search
Adam pointed out that Amazon is offering a Web search engine A9, which uses ancillary information from Alexa. I offer vanderwal.net/random/ as your jumping off point to explore (leave a review if you wish). I am please with the related sites that are offered as similar sites, not that I am trying for anything in particular.
I agree with Adam that Amazon is offering intriguing integration of information and services, which is the position Google is working to fill. Some of the personal portal sites, like Yahoo, more so than MSN or AOL, have done a good job at innovating in this space.
Rael on Tech
Tech Review interviews Rael about rising tech trends and discusses alpha geeks. This interview touches on RSS, mobile devices, social networks, and much more.
Taking Site Headers to the Next level
Dunstan (a fellow WaSP) has done a great job with his new site header at 1976design, his personal site. Dunstan explains that the header is made up of 90 image and uses scripts to drive the weather and time relative header image. The sheep in the header move depending on the weather conditions at Dunstan's farm as well as change based on the time of day (they have to sleep sometime).
Tog explains good design on bad products
Bruce 'Tog' Tognozzini writes When Good Design is => a Bad Product.
You take a mediocre product and rework the design to make it better. Your design is a success, by any reasonable measure, but the resulting new release is actually worse. You redouble your efforts and matters become untenable. It doesnÃt matter how brilliant and effective your designs, the more they improve the product, the less usable the product becomes.
The article is filled with wonderful illustrations that will help us better understand how to make better products.
Testing the Three Click Rule
Josh Porter of UIE test the Myth of the Three Click Rule. Josh finds out that users will continue seeking what the want to find after three clicks as long as they feel they are on the right track and getting closer. Most users will not abandon their quest after three clicks as had been suggested.
Oddly I remember this three click rule from four to five years ago and when we tested it we found the users we tested did not give up. There were other studies at that time that backed up what we were finding. Now in the last couple of years folks that are new to the Web are pontificating the three click rule again.
As always it is always best to test and just follow blindly.
Information structure important for information reuse
John Udell's discussion of Apple's Knowledge Navigator is a wonderful overview of a Personal Information Cloud. If the tools was more mobile or was shown synching with a similar mobile device to have the "knowledge" with the user at all time it is would be a perfect representation.
Information in a Personal Information Cloud is not only what the user wants to have stored for retrieval when it is needed (role-based information and contextual) but portable and always accessible. Having tools that allow the user to capture, categorize, and have attracted to the user so it is always with them is only one part of the equation. The other component is having information that is capable of being captured and reused. Standards structures for information, like (X)HTML and XML are the beginnings of reusable information. These structures must be open to ensure ease of access and reuse in proper context. Information stored in graphics, proprietary software, and proprietary file formats greatly hinders the initial usefulness of the information as it can be in accessible, but it even more greatly hinders the information's reuse.
These principle are not only part of the Personal Information Cloud along with the Model of Attraction, but also contextual design, information architecture, information design, and application development.
Building Web pages for crippled IE browser
Microsoft and others are posting the work arounds needed for the Web pages you build if they require plug-ins. Java and Active Script seem to been the focus at this point. Here we go: Microsoft guide for building to the new neutered IE browser, Apple developer guide for post EOLA development, Real Networks guide for embedded, and Macromedia guide. [hat tip Craig Salia]
Hyper Text 2003 Papers posted
The Hyper Text 2003 Conference has posted the Hyper Text 03 Papers online. There are some great reads in the pile, if you enjoy theoretical and future-current uses of hyper text as a tool and theory.
Typeface indicates nice weather
The New York TImes Circuits section covers weather sensitive typefaces. The Dutch designers Erik van Blokland and Just van Rossum of LettError developed a malleable typeface that changes the form based on weather conditions. This would enable a person to perceive changes in the weather as they were reading their news or other information, all this done to changes in the typeface, which is being read for other content.
Samples of this work can be seen at the University of Minnesota Design School where a twin typeface demo is available as well as the temperature sensitive typeface.
These tools are not innately learned but would take time and instruction to get the user to the sensing ability. This type of secondary communication (the primary channel of information expression is the information being communicated in the content that the typeface is spelling out. Those of us that use and are attuned to our computer's audible cues do not have to think there is an error in the system, but it is conveyed in an audible tone that we recognize and associate with some state of being or in condition. Changing typefaces would be another cue to the world around us.
Bray on browsers and standards support
Tim Bray has posted an excellent essay on the state of Web browsers, which encompasses Netscape dropping browser development and Microsoft stopping stand alone browser development (development seemingly only for users MSN and their next Operating System, which is due out in mid-2005 at the earliest).
Tim points out users do have a choice in the browsers they choose, and will be better off selecting a non-Microsoft browser. Tim quotes Peter-Paul Koch:
[Microsoft Internet] Explorer cannot support today's technology, or even yesterday's, because of the limitations of its code engine. So it moves towards the position Netscape 4 once held: the most serious liability in Web design and a prospective loser.
This is becoming a well understood assessment from Web designers and application developers that use browsers for their presentation layer. Developers that have tried moving to XHTML with table-less layout using CSS get the IE headaches, which are very similar to Netscape 4 migraines. This environment of poor standards compliance is a world many Web developers and application developers have been watching erode as the rest of the modern browser development firms have moved to working toward the only Web standard for HTML markup.
Companies that develop applications that can output solid standards compliant (X)HTML are at the forefront of their fields (see Quark). The creators of content understand the need not only create a print version, but also digitally accessible versions. This means that valid HTML or XHTML is one version. The U.S Department of Justice, in its Accessibility of State and Local Government Websites to People with Disabilities report advises:
When posting documents on the website, always provide them in HTML or a text-based format (even if you are also providing them in another format, such as Portable Document Format (PDF)).
The reason is that HTML can be marked-up to provide information to various applications that can be used by those that are disabled. The site readers that read (X)HTML content audibly for those with visual disabilities (or those having their news read to them as they drive) base their tools on the same Web standards most Web developers have been moving to the past few years. Not only to the disabled benefit, but so do those with mobile devices as most of the mobile devices are now employing browsers that comprehend standards compliant (X)HTML. There is no need to waste money on applications that create content for varied devices by repurposing the content and applying a new presentation layer. In the digital world (X)HTML can be the one presentation layer that fits all. It is that now.
Tim also points to browser options available for those that want a better browser.
Tantek on handrolling weblogs and hand built CMS
Tantek discusses Jeffrey Zeldman handrolling his own RSS feeds (as well as his own site). Tantek also discusses those who still handroll their own weblogs as well as those that have built their own CMS to run their blogs. This was good to see that there are many other that still build their own and handroll (I stopped handrolling October 2001 when I implimented my own CMS that took advantage of a travel CMS I had built for myself).
Great news for Anil as he joins Type Pad and Movable Type company
There was great news this week from Anil who has recently become a member of Six Apart, which was recently funded (yes, great products do still get funded and money is still around for great products). Six Apart are the makers of Movable Type, and just introduced, Type Pad. This was the best string of news I have heard in a long time.
Veen crankin' with OS X
Jeffrey Veen offers his views on Web development on Mac OS X. He discusses using PHP, MySQL, Perl 5.8, CVS, and BBEdit, which in my opinion are excellent choices and some of the reasons I moved over. Jeffrey offers some great links also... (the version control with Mac OS X is a new favorite as is the blog Forwarding Address: OS X
Mobile use of Amazon Wish List and other adventures with mobile gadgets
Tonight was a mobile/portable device adventure. Joy and I had a wonderful dinner at Thyme Station in Bethesda. A Japanese couple sat down next to us and we could see that they were having trouble with the menu. The guy has a tiny Sony device, about the size of an Altoids tin, but a third of the height and finished like an Apple TiBook. He was using the translator and not finding what he was looking for and Joy nudged me and asked if I thought if we should help. Joy asked the couple if they needed a little help the couple giggled and then nodded. The seemed to be having the most problem with the sirloin kabob and did not know what it was. We explained it was beef cooked on a stick. They returned to tapping in word and getting translations on their device and passing it back and forth. They also seemed to have some entertainment on the device. I really am kicking myself for not getting a picture and talking with them a little more.
Joy and I tried to figure if we could catch a movie and checked the movies and listings from the Hiptop. The couple next to us seemed equally interested. We were had just missed the start times for the movies and were going to have to wait for the next round at 10 or so.
We settled on going to Barnes and Noble instead. I found a book I had read about in some RSS feed this past week and really liked it. I was not ready to spring for the book at full price, so I pulled up Amazon and checked the price on the book (Stop Stealing Sheep and Find Out how Type Works). I found the book and a 30 percent discount. But the best part is I dropped it in my Amazon Wish List, which is where I keep track of such things. I then check other items in my Wish List to see if they were in stock at Barnes and Noble. I could not find the two books I really have been wanting and could be willing to pay full price, which means I may buy off of Amazon with a couple other items that will bring me enjoyment.
My Amazon Wish List is one information store that I like having at my side. This really highlights the element of the Model of Attraction that focusses on the user being able to have information be attracted to themselves and have this rough cloud of information follow the user for use when needed. The user works to find information they are attracted to, by searching or reading articles or blogs that the user has an affinity for. Once the information is found most metaphors and models stop working (navigation, information foraging, etc.) but the MoA keeps on working. If the user has a strong enough attraction she may want a method to store the information for further access. How and where become the next questions. The next step is accessing from storage (or your personal information cloud that follows the user). Mobile devices are tools that allow for this attraction to continue, but how do we ease this use? Personalization adds another layer to the user setting attraction (like Amazon's wish list).
Extending Dreamweaver MX for PHP
O'Reilly Net offers Getting Dreamweaver MX Up to Speed with PHP, which discusses how to get and build the Dreamweaver extension you need to build PHP-based sites. Macromedia is now charging for the newest extensions (their perogative), but this article points out how to get the extensions you need for sessions and authentication.
Posting from Hiptop
This is a test post from my Hiptop. This post was done from my regular management page.
Ticketstub memory shares lives
Matt shares a little bit of what the Web can provide, a resting place for open memories. This medium provides a place for connecting people through common understanding and interests as well as shared moments.
Sort your Amazon wish list
Sort your Amazon wishlist by items you want most is an app I have been really wanting. Well second to dumping my Amazon wishlist into my Palm and having the ability to add or delete items from the wish list from my Palm or other mobile device.Yahoo does PHP
Yahoo presentation on why they are moving to PHP. This would make a great interview of write-up as PowerPoint presentations are largely worthless with out the speaking that accompanies them. This is one presentation that has a tiny bit of information that makes me crave for more. I use PHP here as a scripting language of choice. I love being able to use it at work for many of the reasons outlined by Yahoo. It is better than ColdFusion, ASP, or JSP as far a server requirements, secure, and time to market. The flexability and speed which one can develop is tough to beat, except for the flexability of Perl (there is a reason it is called the duct tape of the Internet). The maxim has been use PHP where you can and Perl where you must. Other languages pale in comparison, but have marketing dollars, which drive the hype. [hat tip Cam and Anil]Mail that has problems other than errors
I am giving up on what seems like living in a block of ice, where I can see out and what what is happening but can not communicicate. I have been playing with Web mail that has taken sometime to set up to seemingly work, but I get a humorous error message at logout:Important! This system is beta and not production-ready. You may experience errors and other problems!It seems to remember that there are other problems than errors. (?)
Amazon
Yeah, Amazon's Gold Box is back. One of the items was a Barbie airplane.Apache 2.0 builds for OS X
Hmmm... Yesterday I was looking at Apache and the other two pieces of the triumvirate PHP and MySQL. Today I ran across what could be an improved option, Server Logistics' Apache 2.0 along with Perl, PHP, MySQL, and Postgres. Apache 2.0 provides multithreading and other improvements to the incredibly stable and supreme Web server All of this is set to build and run on Mac OX 10.Microsoft embraces Apache Web server
CNet News discusses Microsoft's .Net set to link to Apache, which is a great step as the Microsoft IIS web server is increasingly being dropped as a viable option because of never ending security problems. This would literally doom Microsoft's .Net initiative as it would not be usable on the Internet without their Microsoft Internet server. By moving the ability to run the .Net framework on an Apache server Microsoft not only extends their ability to run their services on a superior Web server with far fewer security problems, but Apache is now recognized as a viable Web server by Microsoft. Apache owns the majority share of the Web server business and those of use that have had the ability to use it prefer it hands down to Microsoft's IIS.Adaptive Path to DC
Last September I attended a two day User Experience Workshop put on by Adaptive Path. This was one of the most conprehensive sessions/classes I had ever been to on the approach and skills needed to develop a usable Web site. As many of us know the Adaptive Path folks are taking this great session on the road and adding a third day using a local professional to help bring it all home. This may be the most productive money you spend all year. Those that come to your sites and pay for your work with receive an even greater benefit. Do it for yourself and for the users of what you produce.
The following is a better description by the Adaptive Path folks describing the Washington, DC (actually held in Arlington, Virginia) sessions:
Design theories don't help if you can't make them work in actual day-to-day practice. Increasingly, sites must respond to the realities of scant budgets and greater financial return. Adaptive Path's User Experience Workshops will prepare you to meet these challenges with usable tools for putting design theory into practice today. You'll spend the first two days with Adaptive Path partners Jeffrey Veen, Peter Merholz, and Lane Becker. They'll show you how to incorporate user goals, business needs, and organizational
awareness into your design process. You'll develop a project plan, learn methods for research and design, and create clear documentation. You'll learn the same strategies Adaptive Path has successfully practiced for a wide range of companies, including Fortune 500s, startups, and not-for-profits.
Additionally, on day 3 we will be joined by information architect extraordinaire Thom Haller, who will talk about "The Value of Structure." In this workshop, he'll draw on twenty years experience in professional communication to explore the possibilities inherent in structure, and its value to others. As participants, you'll have the opportunity to see structure through users' eyes. You'll learn a measurements-based, performance-focused structure for gathering, evaluating, chunking, knowing, and organizing content. You'll have a chance to "sample" different structures (such as narrative) and see how they offer value to organizations and their constituencies.
You'll leave the workshop inspired and equipped with design techniques and a library of documentation templates that you can use right away -- so that your web site will satisfy your users, your management and you! But wait--there's more! Or, rather, less! As in--DISCOUNTS! If you sign up with the promotional code "FOTV" (without the quotes), we'll knock the price down from $1,195 to $956 -- a 20% discount.
For more information: http://www.adaptivepath.com/events/wdc.phtml
Glasshaus developers books
A stop in to the local bookstore today has been strongly considering Constructing Accessible Web Sites and Usability: The Site Speaks for Itself both are Glasshaus imprints and seemingly very well written and well produced. The accessibility book covers a topic that is tough to get ones mind around initially and the book handles the topic wonderfully. I have been working with the accessibilty issue for a few years now and the book points out some areas that were of a help to me.
I balk a little at the hefty price of the books, which means I will be buying them on discount or sale. I know some of the folks that have contributed to the books, which helps me justify the costs, but not everybody is me. If the cost were a little lower, say a 30 U.S. dollar price point, it would be easier to buy a couple or more and hand them out to folks that really need them. The accessibility issue book is one that really needs a lower price point, but I know there are solid methods for pricing the books just under 50 U.S. dollars.
Baking versus frying CMS
Aaron discusses baking versus frying with content management and updates bake and fry CMS ideas. The idea is to bake content, which is using your content management system to produce static pages. The alternative is to fry from the CMS by providing truely dynamic content. There are a few reasons why one should choose the frying method:
- Frequent (hourly or semi-daily) updates of informaiton
- Multiple dependancies (information linking to and from many points)
- Unlimited resources
- Many variation of presentation of the data
- Providing user slicing and dicing of informaiton capabilities
- Many external content providers
This list does not capture everything, but also provides maleable guidelines. There are many advantages to baking (publishing static content pages) from a CMS:
- Speed of delivery
- Archievable version
- Ease of troubleshooting and maintenance
- Editable output pages
- Use templates to generate valid mark-up and perfect 508 compliant pages
- Using reusable content pieces that provide consistancy and accuracy of information on all presentation layers
- Keeping various application elements well maintained
Aaron provides good links for further discovery of your own.
Usability review of online mapping sites
The Wall Street Journal provides a review of online mapping directions and lists how helpful each of them were with regards to mapping, accuracy, and written directions. These applications are one service that blossomed on the Internet, but the usefullness of the sites and the usability of the sites varies. Reviewed are: AAA.com, MapBlast.com, MapQuest.com, RandMcNally.com, and Hertz NeverLost II GPS. The usability and accuracy of the online maps and their printout versions are key to how well the site gets you to where you are going. One of the items this review required was finding an exact restaurant by name, which there are other methods of finding a restaurant's address to look up on a map. Over all the review is a good read.Content Inventory from a master
Jeffery Veen provides doing a content inventory (or a mind-numbingly detailed odessey through your Web site) over at Adaptive Path. The article comes with an Excel template to get you started. Keep in mind this is a painful task, but one that will reap incredible rewards.PHP and MySQL for managing images on the Web
Managing Images With a Web Database Application with PHP and MySQL and nothing up the sleeves. The folks from O'Reilly Net offer this one, which is not in the Web Database Applications with PHP and MySQL. The book is one of my favorite information application development books at the moment for a variety of reasons: ease of coding principles, explaining application development, explaination, then using what is learned and implementing it.Story of information
Information wants to be found. Somebody created the information to be used (including the coding of an application to extract data to form information). Information (both good and bad) has inherent value. Information that can not be found or used is wasted money and wasted time. Information requires a structure around it to increase its findability. Attempting to make information available with out a usable structure around it is a recipe for failure. Information without a usable structure surrounding it wastes the time of the person (or worse, persons) who created the information, prepared the info for dissemination, and the person/persons/application looking for that information. The waste of time and money by not having a usable information structure or not having any information structure is problematic and, in this day and age, inexcusable waste of vast money, time, and other resources.
The solution lies in working with people who understand information structure. Often these folk are called "information architects". Technology should not be the first step to solving information capturing, storing, structuring, and presentation needs. Human minds are the best first step. Human minds that have training and experience in solving these problems is the best bet. These humans are often called information architects, which:
- Understand that most often the users of information are not the person in the cube or office next door
- Know the users of the information often do not know the creator of the information
- Know the users of the information may not understand the structure of the organization that created the information
- Know the user wants to find the information
- Know the user wants read and use the information in a format they can access
- Know the user will want to consume the information and repurpose that information
- Know that if the user finds what they are looking for and you are providing it the user will often be interested in finding other related or similar information
- Know how to work with designers and technical developers to ensure the needs of your information and the user are joined together
- Know there are many methods of finding information (search, navigation, etc.) and none of these are perfect on their own, but know how to best augment the technologies to provide the best result
- Know that at the heart of this information transaction is the information and the user, which is where the focus belongs
- Know how to increase findability and make the attraction between the user and the information stronger
- Know in the long run their work saves money and time because their experience has proven what they know works
MS security causes sad day
Life sucks when: You have to pull an e-mail account that you manage from service. Particularly when this account is for your Dad. My Dad can be reached at Tom and I will be keeping Thomas. The TJV account is closed.
Why you ask? The account was hacked with the klez virus. He cleaned his hard drive, as he had no choice it or another virus took the hard drive out. He took another hard drive and put it in that machine and started fresh. This may have also infected his new laptop. Yes, all of these machines run Windows (the swiss cheese security system). My dad is more than computer savvy and Windows is not a consumer OS, as it is nothing more than an e-mail away from destroying everything digital you own (among many other issues, which I spend hours assisting friends and relatives with their continual problems with the MS OS). Microsoft continues to lie about its focus on security and the basic problem is the OS itself, it is not secure and it seems it will never be secure. UNIX has some issues, but has many more years of development under its belt, which is why is far more secure. UNIX variants (Apple Mac OS X, Linux, BSD, etc.) all have the advantage of years of experience and advanced developers working on the OS.
Keeping a MS box secure requires somebody with a lot of experience and they are not cheap. The MS total cost of ownership being lower than UNIX is a myth and unfounded. If you have MS open to the outside world (Internet server, DSL at home, or unfiltered (through virus scanner) e-mail, etc.) you need an MS security expert focussed on ensuring the sanctity of whatever is considered valuable on the MS boxes. This person will cost as much, if not more, than a senior UNIX systems administrator (who are, by and large, veterans in UNIX security also as it comes with the territory).
Too many folks (that are near and dear to me) have had MS servers hacked or been victims of viruses in the past couple of weeks. Granted the MS boxes hacked may not have been watched over by MS security experts, but that is what it takes.
Making choices, as far as what language to develop Internet applications, should keep in mind lock in factors. A UNIX only or a Microsoft only solution that requires the application be only run on a certain type of server has never been a great idea. This becomes even more apparent now. In my opinion this has never been a good option. Fortunately, there are many more options available that run on nearly all OS platforms. These include: Perl, PHP, Java (JSP), Python, ColdFusion, etc. Each of these languages have their own plusses and minuses, but if a certain OS platform becomes an unavailable option the applications can relatively easily be moved to another OS. This is not the case with ASP, and even less so the .Net framework (as noted before. Sure ASP can use ChiliSoft, but that is a very short term solution (as you know if you have ever had to use it, it buys you time to recode everything into a portable application language) and requires double to triple the hardware resources to run it compared to ASP on MS or any other language running natively.
All of this is just the beginning of the reasons why I most likely have bought my last Windows machine. The other reasons fall into the areas of trust and pricing. This explanation may follow soon.
.Net lock in
Eric (glish) Costello brings Chris Laco's comments about .Net to his own site as Chris' comments reflect Eric's comments. The main issue is lock in and severe lack of choice. No the security issue that plagues Microsoft at every turn did not show up. The speed improvement in .Net over the current ASP/VB/C development is noticed and raved about. With security a growing concern on many folks minds building applications with a system that only will run on one operating system, which has the worst security record hands down, is not a great option. There are other options available.WYSIWYG in browser part two
The second part to theWYSIWYG editor in a Web browser is available. This section gets into implementing the HTML portion from the first section into the storage components of this article.Paul gets SCRAPI
Paul is on a streak with his rogue API explaination and Bookwatch. The API discussion is very intriguing. Paul has build an Amazon information scraper to add information to his bookwatch. A great idea. The downside is Amazon is always changing its interface, but the current version of the scraper seems to work well for Paul. This shows what can be done with a machine readable Website.CompUSA no sale
Need to have an example of not thinking through all the steps when building a Web application? Macwhiz tries to buy a monitor with good money, but bad application does not allow it. Having the credit from CompUSA on a CompUSA card and using to buy from CompUSA does not mean a thing. The buyer wanted it delivered to his office (always a logical option), but had his home address listed on the credit card (another logical option). CompUSA needed him to add his office address to the card (another logical option), but does not offer any mechanism to doing so (somebody will get fired).
When building applications there needs to be processes put into place to handle the needed options. Many times this requires a phone call to people trained in customer service. Not understanding processes before building an application or have ALL parties talking while developing an application will save embarrassment.
You should never start building before drawing a blueprint that takes into account all the options and needs. There is too much experience around to really have this happen with out a conscious decision being made (usually up the food chain) that stopped the options from being developed (if this is not the case they have the wrong developers or not enough time to have the processes worked out). These reasons are very close to why I will never buy from Barnes and Noble on line again. Ever.
Opening an application to the Internet opens the application to real people and real people provide a wide variety of aberrations to the planned uses for any application. Not having the time, resources, or approval to build in processes for easily handling these aberrations or spending time developing the application using user centered design/development skills will sink even the best funded applications. The user is always right and the real users must be a part of the development.
Philip Greenspun also provides his Software Engineering of Innovative Web Services course materials online. The Problem set 4 is a wonderful section that covers metadata and its uses. As the overview states:
Teach students the virtues of metadata. More specifically, they learn how to formally represent the requirements of a Web service and then build a computer program to generate the computer programs that implement that service.
The fine folks at Q42 have a color blindness check tool. This works to change your Web pages into a palette that a color blind person would perceive.
So you want to build your own weblog tool like the one here? Start with PHP and MySQL with a little Apache and a sprinkling of arrays and script code. Yes, this is basically what is under this puppy.
PHP with Java tutorial over at Dev Shed. Why not JSP? PHP is quicker to write and quicker to run.
Being April 1st, Josh at Praystation turns back the clocks for just one day.
Extranet overview
John Rhodes provides an overview of extranets and hits some great points.
...most people like self-service. An extranet facilitates this activity, if you design it correctly.
Web robots
Want to explore Web robots? The Database of Web Robots is a great starting place. This is also a good place to find information about those robots you find in your access logs. [hat tip Cam]Perl to parse weblogs
Looking to parse your Web logs to gain those wonderful nuggets of information regarding those that visit your site? If you have perl at your fingertips (those of you with OS X do natively) check out Perl for Web Site Management's sample chapter, Parsing Web Access Logs. This will be a very good start, if not exactly what you need.AOL and browser selection
I knew somebody would see the bright side of AOL switching to Mozilla browser, (for those who don't know Mozilla is what is under Netscape and it is Open Source). I personally could not see the dark side to the switch. I guess there might be a few poor souls that don't know how to code by the standards, or may not know there are standards. I feel even worse for the fools that paid money for insipid Web pages that are not coded properly. If it is built in a browser and the developer does not know the interface (in the browser case the document object model (DOM) they are getting paid too much).Yesterday was all about getting the synapses to fire in the right order at SXSWi. I was running on sever sleep deprivation from phones and alarm clocks ringing when I had not finished my needed sleep cycle. None-the-less I had a great time. I greatly enjoyed Steve Champeon's peer panel on Non-Traditional Web Design, as it focussed on the fine art of tagging content, understanding the uses of information, and the true separation of content, presentation, and application controlling the information. The Web Demo panel I was on seemed to go rather well as there were a broad spectrum of sites reviewed and the information from the panel to the developers was of great use (I hope) as I think we all learned something.
The evening provided good entertainment, a wonderful gattering at the EFF party. Once again many folks adjourned to the Omni Hotel lobby for the after-hours social gathering. I spent much of the time just listening to conversation and occasionally partaking. Of intrigue was Rusty of Kuro5hin and Adam of Brian of Slashdot discussion development of site tools that will help a dynamic site fly, keep in mind all these tools are in Perl.
I keep finding Metastatic in my access log. I am loving the app as I find it very cool.
Have you ever wish to build your own WYSIWYG tool in all within a browser? Mitchell Harper for Devarticles shows us how to build a DHTML WYSIWYG tool, aren't we glad we withed for it?
I think a note of clarification is needed regarding the frames comments from the other day. I am a huge fan of the Content Management Bible and have been perusing it for a couple months (or so) now. The use of frames is not all bad, if used in a proper context.
One reason to use frames is using the browser client as an application interface and there are distinct sections with quasi-interrelated functionality. A mapping application (select any one of these elements on the page to see the use of frames - keep in mind there is a heavy use of JavaScript that requires a version 4.5 browser or higher). The application interface often has command elements that are essentially toolbars and definition selection elements that set the metadata layers of the information to be displayed. These toolbars direct the actions of the other frames or provide tools to be used in other frames (a zoom tool, etc.). The functionality in a toolbar is not an element of the map display and it should not be an incorporated element of the map as it has a much different functionality from the map display. Conversely, our users are familiar with navigation being incorporated into the Webpage and that is now a common and preferred construct. But, we are looking at an application being displayed in a Web browser, which requires a different mind set.
Another use of frames is in a controlled environment that has a plethora of distinct content items that are within a contiguous text, such as an extensive table of contents. Here the Metatorial CM Bible is a good example of when to use frames. There table of contents is a helpful information tool to quickly scan through the information to place the reader at distinct point in a larger body of text. The table of contents is a large (long) element of text that could work as an element is one distinct page, but that would require rebuilding those elements of the page with every snippet of information delivered to the browser.
Frames should be used when the distinct content elements require each other. The table of contents and the page display elements should not work with out the other components (if they can we really have to ask ourselves why we are using frames). If we can enter a page in the CM Bible without the table of contents the functionality of the site is broken. The navigation is not available and the assistive information (navigation and/or metadata elements) is not available.
The last item is to ensure that if a frame can stand alone as its own page, please ensure there are the needed navigational elements on the page. In the example that drove my frames rant (largely because the CM folks understand information and its need to be used, but the site breaks information use constructs we know from experience and research to be proper and needed) the thing that was disconcerting was each of the frame elements needed the other to provide complete information for the user. The user needs context. We need to provide the user a means to get to our front page or to other areas within our sites, because if they like our information we should offer them more. If we build a site using framed elements and these elements can be used on their own (no JavaScript sniffers to ensure the other frames are open as a requirement for displaying the content, or other similar technique) the content must have navigation elements (the footer is an unobtrusive placement) and really should have some branding or other statement of ownership.
We know that users of information have varied purposes and methods of using our information. We need to provide the users the tools to help the user provide this information. We are often proud of our information work, but if a user does not know it is us or we do not want to claim our work is decreases credibility.
We need to embrace functional information architecture to ensure proper information use. This bleeds in to user experience design, but understanding how information is used and the information interface is used must be integrated into the IA. Proper functional IA should keep improper use of frames from occurring. Functional IA would walk through a string of questions using a wireframe of a site and ask how the frame sections would interact. We would ask what information is lost if not all the frames function (a surprisingly common occurrence). We would ask if frames maintain context for the information. We would look at methods of insuring the whole of the frames remains so to provide proper navigation, proper context, and proper metadata to help understand the information provided. Not asking these questions is not being responsible to the information, those that collected the metadata and spent time understanding how the information is to be used, and is not responsible to the consumers of the information.
Scott offers a great rant on understanding the Web client. Scott is not a generalist, he understands the details of the interface. Did I mention he is providing specialist information in the Dynamic HTML Bible? Bow down and be a sponge when Scott speaks as you will learn a lot.
What Does Usability Mean: Looking Beyond ëEase of Useà from the fine folks at Cognetics. This solid overview focuses on the Five E's: Efficient, effective, engaging, error tolerant, and easy to learn. The toughest hurdle from my view is error tolerant, which is an often overlooked element in application and Web development. Planning early and knowing the user will help incorporate error tolerance into the development plans. One of the toughest areas to accommodate error tolerance is during feature creep as features grow and interact with various elements the probability for errors that do not have corrective paths accounted for rises greatly.
The solution to the = in the link is to use  in its place. This may require a solid tweak to my home-rolled weblog application so to sniff, parse, and replace the symbol prior to inserting into the database.
I have posted a quick photo journal of this recent trip to NYC. The slide show is a presentation built with PB's SnapGallery. The images were cleaned-up and reduced in PhotoShop prior to moving them in to the SnapGallery. I found SnapGallery very quick and easy to use. I have a strong feeling I will be playing with it some more.
Do you build Web pages? Do you have Mac? Do you have to convert text to HTML/XHTML? If you answered yes (if you didn't you should see what you are missing) please go check out Dean Allen's AppleScript for writing on the Web. These should be wonderful additions to our tool belt.
Matt makes observations of the state of severs and scripting deployments. I agree with nearly all of what Matt point out. Some of the reasoning behind the varying set-ups is for security reason's, others are to mirror configurations on other servers that had slightly different purposes. In all, what this needs is a solid documentation tool. PHP provides some of this with a function that prints out the build of the server that script resides on, this is usually the first task many of us perform on a machine. This however, is just the tip of the iceberg of the information we need.
This is part of the second and fourth element of the cornerstones of information application development (info apps need to be usable, maintainable, reliable, and repeatable). If a task is difficult to maintain and even harder to repeat there is some work that needs to be done to change the environment or the application.
Heard about Apache 2.0 and want to learn more? Internet News has a good write-up on what Apache 2 will offer (the IIS information information is not completely correct in is reasoning, but the facts of non-inclusion in XP Home is).
Content management is back at the forefront of every aspect of my digital life again. Content management revolves around keeping information current, accurate, and reusable (there are many more elements, but these cut to the core of many issues). Maintaining Websites and providing information resources on the broader Internet have revolved around static Web pages or information stored in MS Word, PDF files, etc. Content management has been a painful task of keeping this information current and accurate across all these various input and output platforms. This brings us to content management systems (CMS).
As I pointed to earlier, there are good resources for getting and understanding CMS and how our roles change when we implement a CMS. Important to understanding is the separation of content (data and information), from the presentation (layout and style), and from the application (PDF, Web page, MS Word document, etc.). This requires an input mechanism, usually a form that captures the information and places it in is data/information store, which may be a database, XML document, or a combination of these. This also provides for a workflow process that involved proofing and editing the information along with versioning the information.
Key to the CMS is separation of content, which means there needs to be a way to be a method of keeping links aside from the input flow. Mark Baker provides a great article, What Does Your Content Management System Call This Guy about how to handle links. Links are an element that separates the CMS-lite tools (Blogger, Movable Type, etc.) from more robust CMS (other elements of difference are more expansive workflow, metadata capturing, and content type handling (images, PDF, etc. and their related metadata needs)). Links in many older systems, often used for newspaper and magazine publications (New York Times and San Francisco Chronicle) placed their links outside of the body of the article. The external linking provided an easy method of providing link management that helps ensure there are no broken links (if an external site changes the location (URL) it there really should only be one place that we have to modify that link, searching every page looking for links to replace). The method in the Baker article outlines how many current systems provide this same service, which is similar to Wiki Wiki's approach. The Baker outlined method also will benefit greatly from all of the Information Architecture work you have done to capture classifications of information and metadata types (IA is a needed and required part of nearly every development process).
What this gets us is content that we can easily output to a Web site in HTML/XHTML in a template that meets all accessibility requirements, ensures quality assurance has been performed, and provides a consistent presentation of information. The same information can be output in a more simple presentation template for handheld devices (AvantGo for example) or WML for WAP. The same information can be provided in an XML document, such as RSS, which provides others access to information more easily. The same information can be output to a template that is stored in PDF that is then sent to a printer to output in a newsletter or the PDF distributed for the users to print out on their own. The technologies for information presentation are ever changing and CMS allows us to easily keep up with these changes and output the information in the "latest and greatest", while still being able to provide information to those using older technologies.
Troy Janish's XML tutorial for A List Apart is a great resource. The elements for implementing XML are rather solid now. Knowing how to make use of XML is going to be a needed skill set for many. The debate over database storage of content objects over XML storage of the same will continue for quite some time. I have my leaning for database storage, given their data storage and manipulation functionality built in, but outputing XML documents to share the information seems to be a better option than providing authorized access to the database.
Grokdotcom provides a good overview of the methodologies of Web application development. The modular approach is provided as the best methodology, go figure with an open methodology that is based on published/documented standard set of processes. The article ends up discussing Fusebox, which is new to me, but seems to be a rather straightforward approach to modular software development.
An USA Today article on poor product design provides insight that is helpful not only to product development, but also application development. The insights (while not new to most of us, but most likely very new to USA Today readers) include not including the consumer early enough in the process, product design team not well balanced, and technology runs amok.
These very closely apply to Web/Internet/Application development's downfalls. Not including the user in the development phases and/or testing with users early and throughout the development process. Having a development team that does not have a balance of visual, technical, and production skills can be problematic. Lastly, projects that are technology for technology's sake, very rarely offer success.
Conversely, success comes from getting these things right, involving the user and understanding how users would interact and use what you are building. Having a balanced team so that visual, technical, and production issues can be addressed and solved appropriately. And lastly knowing when and how to best use what technologies will drive success.
This last element, understanding the technologies, will help you get over the hurdle of accessibility/508 compliance. It will also help you find the best tools to interact with the users of the site/application. Having DHTML elements to provide action on a site or to serve information, when the user audience does not fully have the capability of addressing or handling the presentation, will have detrimental effects. Know what your elements your users have turned on and off in their browsers and what versions they are using. It is important to know what threshold of user profile can be the cut-off for developing a site. If 10% of your users have JavaScript turned off should you still develop elements of your site that are JavaScript dependant without providing an alternate service? Know and set this percentage threshold, as it will help understand why you can and can not use certain technologies.
Google shares its 10 things they found to be true, which starts off with, "focus on the user and all else will follow". There are many other truths in this list. [hat tip eleganthack and Digital-Web New]
There is nothing like starting the New Year coding a time rollover code to pull the current information out of your weblog. This means I now have fully functioning code for month and year change overs in my personally built weblog tool. This also means I still love PHP more than any other scritping/Web coding language.
It is getting to be time to pull the code out of the PHP templates and make it more modular/object based. The site is built on a handful of templates that reuse about 75% of the same code to build the pages. From this stage it is time to pull out classes and functions and have each page point to the proper elements. This enables me (or who everelse is getting this code) to be able to make modifications in one place rather than many.
Why modular/object-based? This is how the world works. This is how things are done efficiently. This is the non-foolish way of building applications. (Looks like I am starting this year on a testy note).
Meg is sharing the wonders of a professional looking toolbar in a Web interface in her Using JavaScript to Create a Powerful GUI on O'Reilly Net. Her Blogger interface really awed me. I kept having to remind myself that it was a browser based tool, but it performed like a desktop app (that is until they were down to one employee and the gremlins kept popping up). I have always wanted to add a more professional look to my personal apps, but it has been functionality over beauty for them. Now I may no longer have that excuse.
WebTechniques provides a wonderful overview of the changing Web teams. I have been finding much of what this article points out, the Web it still a valid element, but people have build more efficient tools to manage the content and to help reuse that content. The traditional Web teams have been changing and the skills are widening for those with a passion for building the Web. Read the article as this piece it the tip of the iceberg for what many folks have been watching happen or experienced in the past year or two.
37signals' design not found offers an example of letting your users know restrictions. This is not only important for restrictions, but letting users know which are required fields. Users are not mind readers, so don't treat them like Uri Geller or David Blaine. [hat tip Christina]
Seach Not and Find the Answer
Peter Morville explains why search doesn't suck, but is just not great. I completely agree. Search by itself misses much of the information, unless the site is well written (which provides a cohesive use of terms) or is augmented with metadata.Let me explain, as Doug Kaye uses in his quest to find what is wrong with searching, a person six months or more ago could have been writing about IT as the possible wave of the future. More recently the same person could have been writing about Ginger. This past week the writer would have started writing about Segway. All were the Dean Kamen invention, but a user searching for a the breadth of our writing on Segway could easily miss our mention of IT or Ginger. The user would have to know to search on these other terms, if they did not they may not find our work. We loose.
This is where metadata helps out. If the information is tagged with a term that classifies this information or could have synonymous relationships established from that metadata item (personal powered transportation = IT, Ginger, Segway...) would greatly help the search. Most of us have been worked on projects that have had searches yet we constantly had users asking us were our information on "xyz" could be found, as they did not find it in the search and they know they read it on our site. That is a large persistent problem. Searching is not a solution only a patch that leaks.
By the way taxonomies can be fluid, they have to be as usage changes.
After reading Nick Finck's notes from the Web Design World 2001 in New Orleans and reading the Web Design World 2001 Agenda I think I may have to make the trip next year. I am very intrigued with the Open Source elements of the conference combined with the Web design/development aspects. Open Source tools have treated me far better than any proprietary tool ever has in the past. I am not interested in the cost as much as how solid the tools are, which leads me to Open Source.
Needing to write a functional spec? Just want to learn what a functional spec is to know if you should write one? A functional spec tutorial is what is needed.
[hat tip Jay and Cam]
I am really looking forward to South by Southwest (SXSW) Interactive as I am now a confirmed speaker. There are many other wonderful speakers on fantastic panels that will spark wonderful conversation, and share knowledge and experience.
Jim Jagielski writes about It Don't Amount to Beans, which discusses Java 2 Enterprise Edition (J2EE) application servers. This article states what many complain about, that Java Web solution is not for everything. Knowing your needs, knowing your resources, knowing what you need to process, and knowing the speed and efficiency of scripting languages (Perl, PHP, etc) will greatly help your overal project and application. The article gets at poorly implementing JSP where it is not needed or where it performs poorly. Java can kick some serious behind when used properly and with enough resources behind it. This article helps to sharpen minds.
Finally Web Techniques posts its current issue online, at least the one I have been reading for a week and wanting to share.
If you have Windows XP and are running ClearType (if you have not given it a try you should) Microsoft has a Web tool to tune your ClearType settings. [hat tip Anil]
Matt points out a Web-based bookmarking tool b.. This can be collaborative in nature if you should so choose.
ASP2PHP does a solid job handling converting ASP (active server pages) to PHP. The report that Sun sponsored to hopefully show JSP (java server pages) taking over the site scripting market, not only showed JSP had shrunk in market share, but ASP had dropped drastically. The big winner in this survey was Perl with about 40 percent of the market and PHP was ahead of ASP.
Microsoft has given itself problems with ASP this past year or so as the next generation of ASP requires complete rewrites of your ASP code to work on the next version of server. The code is different enough that it will not port, it must be rewritten. This stopped ASP development to a large degree. Some folks have tried running ASP on UNIX with ChiliSoft, but that is only advisable as a patch until you can recode the application, as it is quite resource intensive and you adding another layer of interpretation, which never helps.