Off the Top: Knowledge Management Entries
Showing posts: 1-15 of 68 total posts
Weeknote - 3 September 2022
You are asking, “Where are you? Are you okay? Are you still blogging?”
In TikTok parlance, “Great questions. Let me tell you.” First, this standard TikTok pattern is one I find really interesting. It fills in he politeness / nicety gap that has become common in the last decade or two, where people jump into answering questions. This nod to thanking the person asking encourages questions and puts people at ease who asked a question (speaking up is often not something most people are comfortable with). But, the pattern has been used so much and is just a common / required custom, it starts to come off as forced or canned, much like required legal disclaimers. None-the-less, it is a good practice.
Well this was a long “week” (parts of this were in an end of March weeknote that needed finishing, so now edited and updated). Things on the work front got incredibly busy and hectic. I’m going to treat this “weeknote” as a catch-up of things that have held my attention over the past year.
I’m hoping to get back to posting regular weeknotes and blogging. My other blog Personal Infocloud has been quite for a long time, but been waiting for about 2 years for SquareSpace to fix a defect that impacted styling and showing full posts. I have a lot of older content I’ve long used in presentations and workshops, that I’m working to turn into videos of some of the pieces of them that are clearer for understanding in video / animated form. I’m also back working on the 70 plus set of social / complexity lenses I’ve been working on for around 14 years with that label, but around 20 years all together going back to the Model of Attraction (still a foundation for a lot of thinking and framing).
With my son off to college, I may have a little more time to write and share. I’m also looking at a digital garden model (see the last section) and as of recently Massive Wiki for a collaborative or commons approach of moving the Lenses forward (well outward).
Note Taking
I have been deep into cataloging, reading, and using the heck out of Obsidian since trying it out in June of 2020 and going all in at the end of July 2020 and it is now second nature. But, this built on my 10 or so years of taking markdown notes in a directory, which I had 8 to 10 year of text notes in that same directory (which were bulk renamed to markdown). My approach and use of aliases and front matter have changed how I do things, but more on that in the Productivity section below. Many of my issues in a quick test of Roam proved to save me from that path and set of problems, Notion not being mine and not a standard file format so I can reuse the notes easily has stopped being used, I use DevonThink but its backlinking and attempt at other Obsidian functionality was clumsy in my source archive (and I just pull in my directory that Obsidian sits on top of so search is relevant with resources saved), and with Obsidian now having iOS capability I’m really using it a lot on the go. I have a seriously strong preference for having the notes be separate from a system that wrangles and provides organizing for and around them. Having used nvAlt for nearly 10 years when it broke badly and wouldn’t open, all of the 2,500 or so markdown (and text) notes that sat under the app in a directory (and linked with file metadata tags). Putting Obsidian in the same notes directory and crating that directory as a vault things just continued on, but now with far more functionality.
One irony is my use of Obsidian, and in particular my daily notes (Daily Dump), has me posting and sharing here less. It is ironic as I write in the Daily Dump as if I am writing to others, but the notes are just to myself (for now - this may change if I can sort out how to keep some of the reading, learning, observations, etc. separate from work or formative observations. The Daily Dump was partly intended to capture things that could be shared back out in a weeknote. Things like the Personal Operating System, which I found insanely insightful (read below), things from Sentiers and The Near Future Lab (particularly around Generalists, which I find quite similar to a bumping into a brightline for polymaths, but also bumps up against Jane McConnell’s book The Gig Mindset Advantage (more on these later as well).
With Obsidian having tags (used to aggregate related things, as a hook metaphor I’ve used for 18 years or more) and the backlinks to use as bridges to move to related materials and ideas much in the way any hypertext environment functions. I used VooDoo Pad on my Macs for roughly 15 years, but it not easily working across iPad and phone to easily read, edit, or add to the corpus had it shift out of my main workflow. I also use Drafts for quick input from mobile and sometimes iPad.
Obsidian has been amazing with its pace and quality of development over the last 2 years. The iPad version is pretty solid, but I’m usually in reach of my iPad so I’m not leaning on it all that much at the moment. This past week there were large changes to the insider build for 0.16 (it was reworking some underpinnings to improve many of community built plug-ins, themes, and templates), but it was the first time the updates broke things in my workflow rather badly. Normally updates cause no problems, but only offer benefits and improvements, with occasional bumps that are resolved in 5 to 10 minutes. But, with the bump this week, I still love it for thinking through writing and note capturing and interlinking. There isn’t anything out there that is close to it.
Read
I have been reading a lot, with a good portion coming through me trusty RSS feed reader, NetNewswire, which echoes my vanderwal.net links page.
Newsletters
While I am not a huge fan of newletters (mostly the part that they arrive in email and not RSS, but the ones that also have RSS feeds are the ones I have been sticking to). Many of these arrive on Sunday, but I really wish it were Friday night or early Saturday morning so I have Saturday and Sunday mornings to get through them and follow the links and devour what is there, but Sunday mornings many arrive and I spend the week going through them.
The one that I am a huge fan of from a general purpose is Patrick Tanguay’s own newsletter Sentiers, which I find to be a real gem. I lost track of Patrick for a while after his Alpine review stopped publishing. I would love to see his Sentiers grow to be a bit more as I find it to be such a good offering. I have been reading it regularly for about a year or a bit more and Patrick has been popping up on podcasts I follow (Near Future Lab (now mostly moved to a Discord for and The Informed Life - more on these later).
Jorge Arango’s newsletter, Informa(c)tion, is an information and organization focussed gem that arrives every other Sunday. There are always good pieces and the links are gems.
Others I really enjoy and tend to link to things that open more browser tabs are: The Marganilian by Maria Popova; Curtis McHale’s PKM newsletter; and Monocle Weekend Edition newsletter (there are many times of late were the newsletter is a bit off target, but the balance for me mostly entertainment).
Books
The Gig Mindset Advantage has been a gem, mostly as it is very familiar as it is pretty much my natural (unintended) MO (modus operendi).
The Map of Knowledge, by Violet Moller has become one of my favorite books. It quickly turned into a slow meditative read as it broke some of my prior understanding of the world of knowledge and creation of advanced math, sciences, and philosophy. This refactoring of my understanding was around the realization that most of the “great books” and works that are the foundations are just very tiny slivers of knowledge that made it through an insanely fragile process of keeping paper copies. A book would need to be hand-written to create a copy and that copy on paper would only last 50 to 80 years before it would heavily decay. I knew well that most of what Western Europe used as fodder in the Renaissance for advancement were works from ancient Greece that had been kept alive through the great libraries and education systems in Persia, Near East, Middle East, Arabian regions, North Africa, and Moorish efforts in Spain. The realization that were may not be looking at the best thinking from the “classics”, but just those that made it through time.
While I had a decent understanding of the vast contributions advancing math, sciences, medicine, and philosophy that are the foundations of much of western thinking, I didn’t know much of the who, when, and where. The Map of Knowledge goes into these areas with a very good level of understanding. The book also does a great job laying out the cycle of life for advanced learning and libraries in each of the regions and progressions through time. One of the common cycles that causes the downfall in many regions was gap in the civilization between those with advanced knowledge and learning and those in power, as well as regular poeple. That chasm between the advanced and those not caused a lot of friction, most often leading to the destruction of libraries and institutions. Many of the civilizations never returned to anything close to the advancements. But, the libraries and learning institutions dispersed and found new benefactors and locations to continue moving forward.
Violet Moller has certain given me a good foundation to learn more.
Gillian Tett’s Anthro-Vision was a book, well a chapter in that book, I’ve been waiting for for many years. The chapter on “Financial Crisis” where Tett had been researching financial markets using her background as an anthropologist for a new role at The Financial Times. Tett followed the paths of understanding in the way a good ethnographer / anthropologist does looking to understand the quiet, and seemingly foundational, areas that seem to be out of focus. This area was that of credit swaps in financial loan markets, which were what caused the 2007 housing market collapse and in 2008 at the massive meltdown of the financial markets. The model for building understanding is one that should be common, but sadly isn’t. The remainder of the book is quite good as well.
Productivity
The biggest thing around productivity is my use of Obsidian continues, as mentioned above. In a couple chats recently I have found other have brought up the backlinking / crosslinking as the most valuable feature. For those of us who have been using Macs for a while we find it reminiscent of not only wikis and their power, but in particular VooDoo Pad, which was light weight and everything was easily interlinked and backlinked and search was incredibly good. VooDoo Pad ran locally on your Mac (eventually it also could sync and run on iOS devices, but it needed a special application to run it). The genius bit about Obsidian is it is just markdown notes with an app that acts as an over watcher to connect and index things, but leaves the markdown notes fully usable by any other app or service that can use Markdown.
Having been taking notes in one directory (and its sub-directories) for some 20 years the ability to always get to my notes and use them is highly valuable. I have run through numerous other apps (particularly cloud based) that just die or go away as they are no longer popular or the owners have the wonderfully tragic combination of being ignorant and arrogant. I can pick-up any of my notes in markdown that have backlinks and they also function in Drafts or other programs. The principle of Small Apps Loosely Joined still has resonance and deep value.
Along with Obsidian and the backlinked notes, I have also been keeping a keen eye on Digital Gardening (Maggie Appleton explains this really well and had links to others also diving deeply). At some point I also stumbled upon Software for your second brain - The Stack Overflow Podcast with Alexander Obenauer talking about his quest for creation of a “personal operating system”, which he shares out in his Lab Notes. Much of Alexander’s quest became refocussed on Obsidian as it was doing a lot of what he needed and was trying to frame out so to build it. He has crated extensions to Obsidian to close some of his perceived gaps, but the underlying principle is data portability and a concept incredibly close to the Small Apps Loosely Joined.
20 Years of Blogging and Wrapping Up the Year 2020
Happy New Year (the 307th day of March in the Year of Covid). As of December 31, 2020 this blog is 20 years old. It started sort of on a whim in Blogger. I find a lot of things that stick start on a whim around here, either as a quick experiment (there are a lot always running) or just fed-up to the point of just do something. Curiosity strikes hard, but it does for most of the people who I spend time with and who do well around tech and digital systems.
There are now 2,103 blog posts. All but a handful are still around. The first one is gone, as it was a “Hello Squirrel!” post (20 years ago I was already insanely tired of hello world and switched some where in 1999 or 2000 and it stuck. I’ve thought about running stats to look at years of activity (in 2004 or 2005 I started Personal InfoCloud as my more work focussed blog and vanderwal.net stayed as my random thoughts and rarely edited brain dump. The top 5 used categories for this blog since its start are Personal, Information Architecture, Web, User-Centered Design, and Apple / Mac. The whole list can be found at vanderwal Off the Top Categories List - By Use. I really need to get a sparkline placed next to each as that would be really helpful to see what is popular when and something I’ve wanted to do for 15 or so years, but never got around to.
I haven’t really kept track of analytics. I would look at analytics on a weekly or monthly basis, but I really haven’t done that in a long while. I do know some of the folksonomy posts drew a lot of attention (the main defining folksonomy post was moved to a static HTML page at the strong urging of academics who needed that for citation purposes. I know a few posts drew a lot of attention inside some companies which were posted here and cross-posted at Personal InfoCloud.
I’ve used blogging to think out loud so to make sense of things, but also for refinding for myself, but also to connect with others who have insights or similar interests.
Wrapping Up 2020
This also is sort of Best of 2020, or things that I spent enjoyable time on or changed me in some good way. I don’t think I’ve ever done a year end wrap as I always feel I’m in the middle of things and a wrap isn’t really fitting when in the midst of things.
Podcasts
Postlight / Track Changes podcast over the last two or three years has become the conversation I’m missing. It is the conversations I miss having and sort of work I’ve been missing at times (I’ve had good stretches of moving things forward to help organization avoid the missing manhole covers or recover through helping understand need, gaps, and pain points to create vastly improved paths forward. Paul and Rich, as well as when Gina gets to play along have been great moments of agreement and a handful of, “ooh, that is good!” as well.
Dear Hank and John from brothers (vlog brothers) Hank Green and John Green, was one of the Year of Covid’s great find as refinding the vlog brothers YouTube channel and their books was comforting and grounding during this odd and rough year. In 2007 time frame with Hank and John were starting out I saw them as Ze Frank copycats, which admittedly they were, and I was a big fan of Ze (particularly after meeting him and having some great winding down rabbits holes of philosophy around content, community, and connection). I was entertained with the vlog brothers 2007 to around 2009, but didn’t overly seek them out and they fell off my radar. This year during the start of lock down they came back into to focus and stayed.
99% Invisible is a weekly breath of fresh air that digs into just one more subject from beautiful Downtown Oakland California. I am continually learning from it and go digging for more information after their podcast.
Matt Mullenweg’s Distributed isn’t quite regular, but I make room for it. Matt has had some really insightful podcasts that also have me digging for more and really am happy to see all that Matt has built so far. It is great that Matt is largely open with his sharing insights and information about they do things at Automattic, but also the guests from outside are really good.
Dave Chang Podcast seems like has a ton of content coming out and I can’t keep up. My favorites are when he is talking with other chefs and restaurant owners. The podcast was really good to listen to during the pandmic as Dave and guests dug deep into the challenges and economics around the effects of the shutdowns.
No Such Thing as a Fish is often my weekend morning listen. Last winter I caught their live DC show, which was great to see after many years. A show where you can get informed and laugh like crazy is always a win in my book.
Newsletters
Newsletters are a love / hate thing for me. The hate mostly is that they are in mail apps where doing useful things with content in them in my information capture for refinding, connecting with other similar things, giving attribution, and coalescing into something new or an anchor point for exploration is tough when in any mail app or service. But, I love a lot of the content. The best newsletters have HTML pages that are easy to search, find things, and interconnect ideas in. The Tiny Newsletter newsletters do this fairly well, Substack does this quite well (and can be RSS feeds), some custom solutions (like Stratechery) do this insanely well, while Mailchimp is miserable with this in so many ways (sadly none of my favorite sources is in Mailchimp, which is ironic and also frustrating).
The perennial favorite for years is Stratechery and keeping up with Ben Thompson’s take and really well thought through explanations are one of the few things I intentionally track down and at least skim (some of the subjects I know really well and look to see where Ben has a different take or a better framing for understanding).
This year perennial favorite New York Times columnist David Leonhardtt (whom I in only recently in the past year or two realized I know and see regularly) took over the daily news summary, New York Times Morning newsletter and it has become what I read as I’m getting up. The insights and framing are really good. But, also pulling things into focus in the NT Times that I may have missed is an invaluable resource with an incredibly smart take no it all.
One added midway this year is the daily MIT Technology Review’s own MIT TR Download that is edited by Charlotte Jee. The intro section and daily focussed editorial is always good, but equally as good are the daily links as I always find something that was well off my radar that I feel should be drawn closer.
My guilty pleasure that I read each morning on my coffee walk (I walk to get coffee every morning as working remotely I may not make it out the front door that day) is the Monocle Minute and Weekend Edition newsletter. Which during the week is quick, informative, breezy in a familiar tone, that cover international business, politics, global focus, travel, and more. I’ve long had a soft spot for Monocle since the started. The Weekend Edition newsletters are longer and have a highlight of someone, which I deeply enjoy, and focus on food, travel, media, the good things in life. The recipes on Sunday are also something I look out for.
The non-regular Craig Mod newsletters, Ridgeline, Explorer, and general newsletter are a good dose of calm and insight.
One of my favorite voices on systems, design, and information architecture is Jorge Arango and his biweekly Jorge Arango Newsletter is a gem of great links. I’m always finding smart and well considered content from this newsletter.
Music
I changed up my listening setup for headphones a bit swapping some things around and now enjoying things quite a bit.
I’ve been writing a bit about music in my weeknotes, but Lianne I don’t think has made the write-ups as I seem to be listening to her music during work wind down as it draws my attention and focus.
Books
2020 was a year of picking up books, but given the state of things reading wasn’t fully functional.
There are two books, which I am still working through, or more akin to meditating through that really struck me in 2020.
The first is Violet Moller’s The Map of Knowledge about a stretch of about 1,000 years and how classical books and knowledge were lost and found. She focusses on nine different periods. The background for how books were copied to stay alive (with far more frequency than I imagined), how the big libraries of the world were kept, whom they served, and how they went away and their collections lost or destroyed. This book deeply challenged a lot of underlying beliefs and, looking back, silly assumptions about keeping knowledge and the vast knowledge we have (which is only a tiny slice of what has gone before us). Reading this book, sometimes just a few pages at a time, causes long walks and deep consideration. It has been a while since I have reworked a lot of foundations for beliefs and understandings so profoundly. A lot of this book also reminds me of my time at the Centre for Medieval and Renaissance Studies that also challenged me and pushed me in similar ways, but that was more of setting foundations and extending them than reworking them.
The other book, which I’m still working through is Eddie S. Glaude, Jr.’s Begin Again: James Baldwin’s America and its Urgent Lessons for Our Own that I had been looking forward to it since I heard about it late in 2019. As we hit summer in 2020 and the murder of George Floyd sparked a deep reawakening of the realities of race issues in the United States it brought back memories of the 1980s and 1990s and thinking and working through similar ideas. That deep caring and belief that things were better and had improved were shattered as reality reared its head. I had stumbled onto James Baldwin after returning from living in England and France for the last semester of undergrad and a little bit more. I returned to the U.S. with really bad reverse culture shock and one of those challenging understandings I had was around race and very little in the U.S. felt right nor on inline with a united anything. This bothered me deeply for a lot of reasons, but part was being threatened just by hanging out with good friends who were running errands and they were verbally abused (and I feared worse was coming) by just walking in a store and I was a target of the same because I was with him. There were many times like this. After living in England and France this was clear it was mostly an American thing, particularly in educated circles where skin color wasn’t the first consideration it was who you are and what you believe and do. Baldwin echoed these vibrations of reality that trembled through me, it made me feel not alone in this, but he also gave urgings to stand up and be a different way. Over the years this faded, until the torch march on Charlottesville, Virginia and then the long series of murders at the hands of people who should be protecting not wrongly dishing out their perverted mis-understanding of justice. Begin Again has had me thinking again, believing again, and acting again, but taking it in small meditative steps and also reworking my foundation.
William Gibson’s Agency was a good romp and included a handful of places I know quite well, which really help me see it. I hadn’t finished reading Peripheral, but have it on the list to do.
John Green’s Paper Towns was a wonderful read and his view on the world and use of language is one I find comforting, insightful, and delightful. I have The Fault in Our Stars queued up. I also picked up his brother Hank Green’s An Absolutely Remarkable Thing and made it about a third to half way through and it was reminding me a lot of 2005 to 2010 or so and things I hadn’t fully unpacked, so set it aside for a bit. I really enjoyed the characters and storyline, but I needed something that was a little more calm for me.
Lawrence Levy’s To Pixar and Beyond which was an interesting take on one person’s interactions with Steve Jobs and Pixar, which I found incredibly insightful and enjoyable. I’ve read a lot of books on Steve Jobs, Apple, and Pixar over the last 20 to 25 years and this added new insights.
James and Deborah Fallows’ Our Towns: A 100,000-Mile Journey into the Heart of America has been a really good read to help understand and get insights into where America is today with what are the thinking and beliefs.
The Monocle Book of Japan is really enjoyable as it is beautifully make. It is part picture book with the great photography that is in Monocle(https://monocle.com) as well as brief well written insights into many different facets of Japan and life in Japan.
Games
Ghost of Tsushima is one of the best games I’ve run across in a long time. It is utterly beautiful, the transitions are quick, and the game play (while quite bloody) is fun and not over taxing nor complicated. I’ve really enjoyed prior Sucker Punch Production’s games, I the Infamous series has been a real favorite (although hearing a slow moving empty garbage truck with rumbling diesel engine still puts me on edge as it sounds like the Dustmen from the first Infamous game). The storyline in Ghosts is really good as well and has kept me moving through the game after taking a break. I love the open map as well, which sizable and insanely beautiful.
MLB the Show is continually one of my favorite sport sim games as the game play is quite good, the visuals are amazing, and the team management and different ways to play through a season are really enjoyable. It gets so many things right that most other sport simulations don’t. I quite like sport sims as they have a fixed time, which makes it easy to stop or at least consider how long you have been playing and then get back to other things.
Fifa 20 and 21 continued to be really fun and enjoyable. The graphics and game play improves quite a bit each iterations and this last entry was no different. Much like the Show I find Fifa really relaxing to play and fun to manage teams and work through improving them.
Others I’ve enjoyed and played Death Stranding, No Man Sky, Journey, and Grand Tourismo. Death Stranding I didn’t finish even though I was enjoying it, the theme wasn’t really working well with the Covid–19 pandemic, but I know I will return to it. I’ve sunk a fair amount of time exploring in No Man Sky again and really enjoy it. I’m still playing Journey after all these years and still like it a lot as it is calming, familiar, and time limited. Grand Tourimso is still one of the most gorgeous games and fun to just drive around in.
Watching
I’ve written a fair amount in weeknotes about these three. There is more I liked, but I I haven’t really kept good track of those things.
* The Crown
* Ted Lasso
* Mandalorian
Productivity
The big shift has been Obsidian, which has become the layer over my existing notes that are in markdown and already in directories. I looked at Roam Research, but quickly realized it is most everything I try to stay far from, which is the content isn’t in my possession (if anything goes south I’m stuck), there are no APIs to extend use, the subscription is expensive for something not fully built and not well thought through, and a whole lot of arrogance from the developers (this is something to steer very far from, particularly if things aren’t well thought through).
Obsidian has me not only finding things in my existing notes, but allowing for interconnecting them and adding structure to them. The ability to have block level linking is really nice to have as well, but I haven’t really made use of that yet. I have been writing a lot more notes and pulling notes and highlights out of books. In the past I have used VooDoo Pad wiki on Mac and loved it and Obsidian gives me that capability and with storing the notes on Dropbox I can search, edit, and add from mobile as well.
Obsidian may be my one of my favorite things from 2020 and one that will keep giving for years to come.
Rebuilding My Note Taking and Management System and Model
The past many weeks I have been digging into a better note taking and management method, while also embracing what I have and my core underlying principles. A continual genre in YouTube I watch is around productivity, particularly around personal knowledge management methods and tools. A couple years back I ran into Zettelkasten Method, that comes from Niklas Luhmann, which focuses on his prolific reading and his card catalogue and related note taking system. Then a few months back I heard Jorge Arango’s interview with Beck Tench it drew Zettelkasten back into focus. The interview with Beck focussed on Tinderbox, which I love, but I also want mobile access to my notes from phone and tablet.
Early Exploration
I have been using Notion a little bit, but my only use the last few months is as an interstitial capture for YouTube and some other rich media. [I like Notion and it seems like a modern take on Podio and has a similar downfall of not sorting out an adaptive data structure for interoperability and consistency.] But, the communities that are interested in Notion became obsessed with Roam Research, so I looked at Roam. Roam and Notion are two vastly different approaches, which can complement each other but in to way replace each other. But, each has a similar faults, no API, no standard export for structured information, and fully cloud based. That is too many common failure points wrapped into one product (Notion is working on and API, which is really good). Roam bugged me most because it relies on an outline format but has no clue about OPML exporting, but worse has no good export model. The cloud based, which requires being connected and online is a model I really don’t like as, particularly if their isn’t a local sync nor standard data format model. What I really like about Roam is its block focussed format, that is akin to purple numbers model of small chunks that are addressable and reusable.
In this time of looking what a next generation of quick note taking would look like, but long used tool, NValt failed spectacularly, in that it would not find my directory where my 1,200+ notes were stored, nor could I add new notes. Fortunately all of my notes are in plain markdown text files, so all I was missing was my tagging of the files in NValt (Brett Terpstra who created NValt has been working on a new tool that can replace NValt but has been taking forever to show up and my need became immediate). This is one of the common reasons for owning my own notes and having them locally and not using somebody else’s model and framework. But, also using the [small apps loosely joined] model where many tools pointing at well formatted / structured data / information can function to their best ability and can use their strengths without breaking anything with the information / data.
Seriously Looking at Note Taking and Management Tools
I started looking at about five or six different note taking tools. I was building out a rough attribute model of tools to help see what each offered or didn’t. I am needing to write this up, but it started with watching Mike and Matty’s, Notion vs Roam vs Obsidian vs Remnote - How to best fit note taking app for you and using their criteria as a base, then building on it. Obsidian and Remnote were already on my list, but also included Zettelnote, Zettlr, and a couple that extended Tidlywiki for a Zettelkasten type model. I also included OmniOutliner as that has been (and will be) my core outlining tool that interplays well with OPML and I can back and forth with good mind mapping tools that also output and import OPML data standard. I also included DevonThink Pro as it is my long used (since 2005) note and information storage and smart search tool (it already was indexing my notes directories) that there is no chance I’m going to give up, but also knew it didn’t have the core functionality I was seeking, wiki-style back linking.
I did a quick test or Roam and ruled it out as it broke rules I try not to break, and it broke many of them (biggest one is know now you are going to exit before you enter anything and a lack of any structure nor API made it a giant risk I’ve been burned by too many times, but the developers have a lot of arrogance about their approach that far too often leads to disasters - sometimes the kindest, smartest, and solid planning people end up with disasters that I feel very badly about but arrogance and ignorant I don’t).
Zettlr and Remnote were next. But the setup took a bit more of me managing and building things and I know when I lose focus those may not be best choices for myself (my past self 15 years ago or more would have loved it and done well with it, but those days are not now).
Obsidian Ticks the Right Boxes and Adapts to My Existing Model
Obsidian is where I put some time. I pointed its “Vault” to my notes directory (and sub-directory) where I had my 1,200 markdown notes already (some of them were .txt extensions, which I did bulk extension swap on) and it could read everything perfectly. One of my first tests was adding backlinks to some of my social lenses and social scaling notes, which worked really well by making related elements connected. I started capturing my notes about what I was doing in Obsidian and the ease of not only connecting things with backlinks, but having the ability to set empty node wiki links (many notes with the same link to a note / page that doesn’t exist yet, but have the same link to it) and then being able to use backlink following from that non-existent notes link list of things pointing to it was insanely valuable.
I have quite a few book list and book note pages already and I started linking them and linking authors and making author pages. I also found I was wanting note page templates for simple book pages in a Zettelkasten model, a book notes template, author / creator template, and a few others. I created these from existing structured notes I’ve used for years and put the outlines in TextExpander using a simple input line or two to label all of the headers with author name or other name.
I started typing out my notes and highlights from books I’ve read and annotated over the years and after the first three or so books I was deeply hooked.
The Use Where Obsidian Showed I was Hooked
Where I knew I was sold was this last weekend I went back to one of Matt Webb’s blog posts on Small Groups that is dense and has links out to great resources. I captured my initial notes on Matt’s post, and annotated relating to his sections. But, I also quickly dug through the linked materials and created and filled out structured note pages for those as well. The James Mullholland post on Small Groups was fantastic and it spidered out to more related resources, so I followed those and took notes. All of this was cross-linked and back-linked and fleshed out small group notes that I have been building as part of social scaling I’ve been writing on and presenting (talks and workshops) for years. The small group size they focus on is roughly team size, but not a team. Both of these are cooperative social models, which scale from teams, groups (small to large groups with similar social interaction models, but the dynamics shift quite a bit around 75 people and break fully about 300 to 500 people), community (everybody inside a firewall or inside an walled off construct), and network (inside and outside a firewall - so for business it is customers, contractors, consultants, vendors, etc. where there needs to be a safe model for sharing information with shared goals as different roles with their purpose come together for back and forth exchange) - more can be found in my related write-up 5 Core Insights for Community Platforms Today.
This note taking and contextualizing and cross linking to rip through and gut a series of related and interrelated pieces has been something I’ve long looked for and wanted. Many dog years ago in college I took reading notes on note cards with citations and context. When writing a paper / essay I would assemble the note cards in an order that could tell a story. Then I would build an outline in WordStar and type in the quotes. Then I would write the narrative and wrapper. Obsidian is starting to get at that, but ripping through a resource to pull out highlights, quotes, annotations, and notes is utterly fantastic. It gives me a solid resource to easily pull together ideas and supporting information.
Other Obsidian Capabilities
Obsidian can show two note pages at once so to easily copy book citation information from the structured book note file into the book note page. The multiple notes in panels also works well for copying quotes to quote pages and cross linking.
Using Obsidian and Still Working from Mobile and Tablet
The mobile use essential had been broken for a bit after Dropbox stopped supporting softlinks in Mac and requiring that to be native in Dropbox and doing the softlink from the Mac to Dropbox. I moved the directory to Dropbox, which leaves a copy locally usable should something happen to Dropbox and added a softlink for local backups. I pointed DevonThink to this directory to index and I was back running. Now I can use Drafts to take a quick note from my iOS devices and push it to the notes directory (later go back and fix the file name) and I have good inbound notes and can use backlinks (which I test later). This method also works for share sheet to Drafts from Overcast or YouTube and having the link to the media and the notes all pulled in.
Happiness with notes has been missing for a while, perhaps happiness has returned.
Resources
PubPub from MIT Media Lab
I just stumbled into MIT Media Lab’s PubPub service that is an open platform for writing new research journals. It has some nice collaborative features, versioning, embraces markdown at its core, and inline discussions.
Social Circles
One of the pieces I really want to explore is how its social dimensions work. My my take on different things I write and have interest in have different social circles that I want to ping and get feedback from. But, there are subjects and groups / communities that I really would like to participate in as well. This is a more complicated and complex area that really needs work and focus. Google+ tried this but deeply flubbed it as their circles are based on individual’s perspectives and not socially constructed realities (knowing the boundaries of who is involved in a circle and having really solid social interaction design around that is a basic requirement, something nobody at Google seemed to consider nor have basic foundations in social sciences to understand this basic need). For PubPub, getting these constructs right would be really helpful and make it a really powerful service and platform.
Other than PubPub
PubPub is fairly close to what I was hoping Poetica would become and Draft app. I’ve been thinking about this for The Lenses and its subset, Social Lenses writings. Also just being able to write blogs and get knowledgeable sanity checks on them from others before posting. This is something I was trying to do with Draft app and had some success with people who are familiar with markdown (which is most people I interact with), but alerting people or subsets of groups that there is something I would really like early looks at and feedback is where it falls a bit short. It also seems like Nate Kontny is now more focussed on Highrise (light CRM service that he took over and now is CEO) than Draft. Also with the purchase of Poetica and its imminent shuttering, I’m looking at other options.
Some of what I have interest in can be found in Medium, but I’d rather just syndicate there, given their use policy. Medium is a really nice content creation platform, with some okay drafting with feedback capabilities, but I’m looking for a bit more. I also really prefer Markdown approach these days as it keeps things really light and I can edit and work on writing from most any platform I have with me or at my access, even if I’m lacking a network connection (which is something that is really helpful for focus for me actually).
One PubPub Wish
The one thing I wish PubPub had was an open source version where I owned the platform and could run it on a server of my choosing. But, it looks like this is in the plans (a few bugs need to be squashed on their way to this), as the PubPub About page states.
Happy New Year - 2016 Edition
Happy New Year!
I’m believing that 2016 will be a good year, possibly a quite good year. After 7 years of bumpy and 2015 off to a rough start on the health front it stayed rather calm.
I don’t make resolutions for the new year. It is a practice that always delayed good timing of starting new habits and efforts when they were better fits. The, “oh, I start doing this on on New Years” always seemed a bit odd when the moment something strikes you is a perfectly good moment to start down the path to improvement or something new.
This blog has been quiet for a while, far too long in fact. Last year when I was sick it disrupted a good stretch of posting on a nearly daily basis. I really would like to get back to that. I was planning to start back writing over the past couple weeks, but the schedule was a bit filled and chaotic.
Digging Through Digital History
This past year I did a long stretch working as expert witness on a social software case. The case was booted right before trial and decided for the defense (the side I was working with). In doing this I spent a lot of time digging back through the last 5 to 10 years of social software, web, enterprise information management, tagging / folksonomy, and communication. Having this blog at my disposal and my Personal InfoCloud blog were a great help as my practice of knocking out ideas, no matter how rough, proved a great asset. But, it also proved a bit problematic, as a lot of things I liked to were gone from the web. Great ideas of others that sparked something in me were toast. They were not even in the Ineternet Archive’s Wayback Machine. Fortunately, I have a personal archive of things in my DevonThink Pro repository on my laptop that I’ve been tucking thing of potential future interest into since 2005. I have over 50,000 objects tucked away in it and it takes up between 20GB to 30GB on my hard drive.
I have a much larger post brewing on this, which I need to write and I’ve promised quite a few others I would write. The big problem in all of this is there is a lot of good, if not great, thinking gone from the web. It is gone because domains names were not kept, a site changed and dropped old content, blogging platforms disappeared (or weren’t kept up), or people lost interest and just let everything go. The great thinking from the 90s that the web was going to be a repository for all human thinking with great search and archival properties, is pretty much B.S. The web is fragile and not so great at archiving for long stretches. I found HTML is good for capturing content, but PDF proved the best long term (10 years = long term) digital archive for search in DevonThink. The worst has been site with a lot of JavaScript not saved into PDF, but saved as a website. JavaScript is an utter disaster for archiving (I have a quite a few things I tucked away as recently as 18 months ago that are unreadable thanks to JavaScript (older practices and modifications which may be deemed security issues or other changes of mind have functional JavaScript stop working). The practice of putting everything on the web, which can mean putting application front ends and other contrivances up only are making the web far more fragile.
The best is still straight up HMTL and CSS and enhancing from there with JavaScript. The other recent disaster, which is JavaScript related, is infinite scroll and breaking distinct URLs and pages. Infinite scroll is great for its intended use, which is stringing crappy content in one long string so advertisers see many page views. It is manufacturing a false understanding that the content is valued and read. Infinite scroll has little value to a the person reading, other than if the rare case good content is strung together (most sites using infinite scroll do it because the content is rather poor and need to have some means of telling advertisers that they have good readership). For archival purposes most often capturing just the one page you care about gets 2 to 5 others along with it. Linking back to the content you care about many times will not get you back to the distinct article or page because that page doesn’t actually live anywhere. I can’t wait for this dim witted practice to end. The past 3 years or so of thinking I had an article / page of good content I could point to cleanly and archive cleanly was a fallacy if I was trying to archive in the playland of infinite scroll cruft.
Back to Writing Out Loud
This past year of trying to dig out the relatively recent past of 5 to 10 years with some attempts to go back farther reinforced the good (that may be putting it lightly) practice of writing out loud. In the past few years I have been writing a lot still. But, much of this writing has been in notes on my local machines, my own shared repositories that are available to my other devices, or in the past couple years Slack teams. I don’t tend to write short tight pieces as I tend to fill in the traces back to foundations for what I’m thinking and why. A few of the Slack teams (what Slack calls the top level cluster of people in their service) get some of these dumps. I may drop in a thousand or three words in a day across one to four teams, as I am either conveying information or working through an idea or explanation and writing my way through it (writing is more helpful than talking my way through it as I know somebody is taking notes I can refer back to).
A lot of the things I have dropped in not so public channels, nor easily findable again for my self (Slack is brilliantly searchable in a team, but not across teams). When I am thinking about it I will pull these brain dumps into my own notes system that is searchable. If they are well formed I mark them as blogfodder (with a tag as such or in a large outline of other like material) to do something with later. This “do something with later” hasn’t quite materialized as of yet.
Posting these writing out loud efforts in my blogs, and likely also into my Medium area as it has more constant eyes on it than my blogs these days. I tend to syndicate out finished pieces into LinkedIn as well, but LinkedIn isn’t quite the space for thinking out loud as it isn’t the thinking space that Medium or blogs have been and it doesn’t seem to be shifting that way.
Not only have my own resources been really helpful, but in digging through expert witness work I was finding blogs to be great sources for really good thinking (that is where really good thinking was done, this isn’t exactly the case now, unless you consider adding an infinitely redundant cat photo to a blog being really good thinking). A lot of things I find valuable still today are on blogs and people thinking out loud. I really enjoy David Weinberger, Jeremy Keith, and the return of Matt Webb to blogging. There are many others I read regularly (see my links page for more).
Blogfodder and Linkfodder
Not only do I have a blogfodder tag I use on my local drive and cross device idea repositories and writing spaces, but I have a linkfodder marker as well.
Blogfodder
Blogfodder are those things that are seeds of ideas for writing or are fleshed out, but not quite postable / publishable. As I wrote in Refinement can be a Hinderance I am trying to get back to my old pattern of writing regularly as a brain dump, which can drift to stream of consciousness (but, I find most of the things that inspire me to good thoughts and exploration are other’s expressions shared in a stream of consciousness manner). The heavy edit and reviews get in the way of thought and sharing, which often lead to interactions with others around those ideas. I am deeply missing that and have been for a few years, although I have had some great interactions the last 6 months or so.
I also use blogfodder as a tag for ideas and writing to easily search and aggregate the items, which I also keep track of in an outline in OmniOutliner. But, as soon as I have posted these I remove the blogfodder tag and use a “posted” tag and change the status in OmniOutliner to posted and place a link to the post.
Linkfodder
Linkfodder is a term I am using in bookmarking in Pinboard and other local applications. These started with the aim of being links I really want to share and bring back into the sidebar of this blog at vanderwal.net. I have also hoped to capture and write quick annotations for a week ending links of note post. That has yet to happen as I want to bring in all the months of prior linkfoddering.
I have been looking at Zeef to capture the feed from my Pinboard linkfodder page and use a Zeef widget in my blog sidebar. I have that running well on a test sight and may implement it soon here (it is a 5 minute task to do, but it is the “is it how I want to do it” question holding me back). In the past I used Delicious javascript, which the newest owners of Delicious gloriously broke in their great unknowing.
The Wrap
Both of these are helping filter and keep fleeting things more organized. And hopefully execution of these follows.
KM World 2014 Wrap
I spent much of this week at KM World 2014 in Washington, DC and the past few days I was working on notes and blog posts for here, but time to get them in readable form and posted wasn’t quite there, so today they became a Personal InfoCloud post, KM World 2014 is a Real Gem.
I had a great time with fantastic people whom I’ve known and people new to me. I spent a lot of time talking about work projects and being back on the consulting side again, but also getting content out and what makes sense with prioritization. I had a lot of great meetings and less formal chats about the state of things as well as trying out some metaphors for framing some things to gage how well they hold up.
I have a lot of snippets to explore and post that have come out of this past week, but I’m digging out of email, notes, snippets, and other things tucked away from this past week.
Pear Note Updates to v3 Now with Skype Support
This morning’s email notification that Pear Note, a note taking and recording app for Mac OS, updated to version 3. I’ve used Pear Note for meetings to record the audio and take note and the text syncs to a timestamp in the audio, which is incredibly helpful and reduces the notes I have to take so I spend more time listening.
The best part of the news of this update for me is that it can now grab Skype recorder. I use Skype recorder a lot so I can pay attention to the conversation and not focus on note taking. Now having Pear Note tied in I can mark quick annotations on the Skype call and then go back later and fill the notes in (if you are listening to the recording while updating your notes it will continue to timestamp).
Pear Note 3 is now optimized for Lion, includes higher bit rate audio recording and HD 720p video recording. This is paired with the updated Pair Note for iOS, which updated today as well.
Where Good Ideas Come From - Finally Arriving
I don't think I have been awaiting a book for so long with so much interest as I am for Steven Berlin Johnson's (SBJ) new book, Where Good Ideas Come From: The Natural History of Innovation.
Why?
Ever since I read SBJ's book Emergence: The Connected Lives of Ants, Brains, Cities, and Software I was impressed how he pulled it together. I was even more impressed with how the book that followed, Mind Wide Open: Your Brain and the Neuroscience of Everyday Life (my notes from one piece of this book that really struck me is found in the post The User's Mind and Novelty). During all of this SBJ was writing about how he was writing and pulling notes together. On his personal blog he has talked often about DevonThink and how he uses it (this greatly influenced my trying it and purchasing it many years back and is the subject of a recent post of mine As If Had Read). This sharing about how he keeps notes of his own thoughts and works though ideas that go from tangents and turn into solid foundations for great understanding. It was this fascination that I included Steven as one of the people I would really like to meet, with the reasoning, "I like good conversation and the people that have provided great discovery through reading their writings often trigger good conversation that drives learning." (from Peter J. Bogaards interview with me for InfoDesign in July 2004).
The Sneak Preview Webinar
Today (Thursday 30 September 2010 as of this writing) Steven provided a webinar for those who had pre-ordered copies of his new book. It contains everything I have been expecting the book to have and have wished he would right up and put in a book over the last 6 to 7 years of wishing. He brings into the book the idea of the commonplace book, which I have been mulling over since I read it (I may be a bit obsessed with it as it ties in neatly with some other things I have been mulling about for a long time, like the Personal InfoCloud as written up in It is Getting Personal and many presentations going back into 2003, if not farther).
One of the great ideas that came out in the webinar was the idea of taking reading vacations to just take time off and read and focus on the reading and the ideas that come out of that reading and the ideas that are influenced by it. Steven talked about companies like Google and their 20% projects. But, what if companies gave employees paid time to read and focus on that. Read, learn, challenge what you know, expand your own understanding, mix what you have known and challenge it with new ideas and challenges and viewpoints. I think this is not only a good idea, but a great idea. Too many ideas have yet to be born and far too many "thought leaders" haven't evolved or challenged their thoughts in a long long time.
Yes, I can not wait to get this book in my hands and read. I am hoping the webinar will be made available more broadly as it is a gem as well.
As If Had Read
The idea of a tag "As If Had Read" started as a riff off of riffs with David Weinberger at Reboot 2008 regarding the "to read" tag that is prevalent in many social bookmarking sites. But, the "as if had read" is not as tongue-in-cheek at the moment, but is a moment of ah ha!
I have been using DevonThink on my Mac for 5 or more years. It is a document, note, web page, and general content catch all that is easily searched. But, it also pulls out relevance to other items that it sees as relevant. The connections it makes are often quite impressive.
My Info Churning Patterns
I have promised for quite a few years that I would write-up how I work through my inbound content. This process changes a lot, but it is back to a settled state again (mostly). Going back 10 years or more I would go through my links page and check all of the links on it (it was 75 to 100 links at that point) to see if there was something new or of interest.
But, that changed to using a feedreader (I used and am back to using Net News Wire on Mac as it has the features I love and it is fast and I can skim 4x to 5x the content I can in Google Reader (interface and design matters)) to pull in 400 or more RSS feeds that I would triage. I would skim the new (bold) titles and skim the content in the reader, if it was of potential interest I open the link into a browser tab in the background and just churn through the skimming of the 1,000 to 1,400 new items each night. Then I would open the browser to read the tabs. At this stage I actually read the content and if part way through it I don't think it has current or future value I close the tab. But, in about 90 minutes I could triage through 1,200 to 1,400 new RSS feed items, get 30 to 70 potential items of value open in tabs in a browser, and get this down to a usual 5 to 12 items of current or future value. Yes, in 90 minutes (keeping focus to sort the out the chaff is essential). But, from this point I would blog or at least put these items into Delicious and/or Ma.gnolia or Yahoo MyWeb 2.0 (this service was insanely amazing and was years ahead of its time and I will write-up its value).
The volume and tools have changed over time. Today the same number of feeds (approximately 400) turn out 500 to 800 new items each day. I now post less to Delicious and opt for DevonThink for 25 to 40 items each day. I stopped using DevonThink (DT) and opted for Yojimbo and then Together.app as they had tagging and I could add my context (I found my own context had more value than DevonThink's contextual relevance engine). But, when DevonThink added tagging it became an optimal service and I added my archives from Together and now use DT a lot.
Relevance of As if Had Read
But, one of the things I have been finding is I can not only search within the content of items in DT, but I can quickly aggregate related items by tag (work projects, long writing projects, etc.). But, its incredible value is how it has changed my information triage and process. I am now taking those 30 to 40 tabs and doing a more in depth read, but only rarely reading the full content, unless it is current value is high or the content is compelling. I am acting on the content more quickly and putting it into DT. When I need to recall information I use the search to find content and then pull related content closer. I not only have the item I was seeking, but have other related content that adds depth and breath to a subject. My own personal recall of the content is enough to start a search that will find what I was seeking with relative ease. But, were I did a deeper skim read in the past I will now do a deeper read of the prime focus. My augmented recall with the brilliance of DevonThink works just as well as if I had read the content deeply the first time.
Social Design for the Enterprise Workshop in Washington, DC Area
I am finally bringing workshop to my home base, the Washington, DC area. I am putting on a my "Social Design for the Enterprise" half-day workshop on the afternoon of July 17th at Viget Labs (register from this prior link).
Yes, it is a Friday in the Summer in Washington, DC area. This is the filter to sort out who really wants to improve what they offer and how successful they want their products and solutions to be.
Past Attendees have Said...
"A few hours and a few hundred dollar saved us tens of thousands, if not well into six figures dollars of value through improving our understanding" (Global insurance company intranet director)
From an in-house workshop:
"We are only an hour in, can we stop? We need to get many more people here to hear this as we have been on the wrong path as an organization" (National consumer service provider)
"Can you let us know when you give this again as we need our [big consulting firm] here, they need to hear that this is the path and focus we need" (Fortune 100 company senior manager for collaboration platforms)
"In the last 15 minutes what you walked us through helped us understand a problem we have had for 2 years and a provided manner to think about it in a way we can finally move forward and solve it" (CEO social tool product company)
Is the Workshop Only for Designers?
No, the workshop is aimed at a broad audience. The focus of the workshop gets beyond the tools' features and functionality to provide understanding of the other elements that make a giant difference in adoption, use, and value derived by people using and the system owners.
The workshop is for user experience designers (information architects, interaction designers, social interaction designers, etc.), developers, product managers, buyers, implementers, and those with social tools running already running.
Not Only for Enterprise
This workshop with address problems for designing social tools for much better adoption in the enterprise (in-house use in business, government, & non-profit), but web facing social tools.
The Workshop will Address:
Designing for social comfort requires understanding how people interact in a non-mediated environment and what realities that we know from that understanding must we include in our design and development for use and adoption of our digital social tools if we want optimal adoption and use.
- Tools do not need to be constrained by accepting the 1-9-90 myth.
- Understanding the social build order and how to use that to identify gaps that need design solutions
- Social comfort as a key component
- Matrix of Perception to better understanding who the use types are and how deeply the use the tool so to build to their needs and delivering much greater value for them, which leads to improved use and adoption
- Using the for elements for enterprise social tool success (as well as web facing) to better understand where and how to focus understanding gaps and needs for improvement.
- Ways user experience design can be implemented to increase adoption, use, and value
- How social design needs are different from Web 2.0 and what Web 2.0 could improve with this understanding
More info...
For more information and registration to to Viget Lab's Social Design for the Enterprise page.
I look forward to seeing you there.
Tale of Two Tunnels: Web 2.0 and Enterprise 2.0
Yesterday I made a few comments in Twitter that prompted a fair amount of questions and requests for more information. The quips I made were about the differences between Web 2.0 (yes, an ambiguous term) and Enterprise 2.0 (equally ambiguous term both for the definition of enterprise and the 2.0 bit). My comments were in response to Bruce Stewart's comment The whole "Enterprise 2.0" schtick is wearing thin, unless you've been monitoring real results. Otherwise you're just pumping technology.. In part I agree, but I am really seeing things still are really early in the emergence cycle and there is still much need for understanding of the social tools and the need for them, as well as how they fit in. There are many that are selling the tools as technologies with great promise. We have seen the magic pill continually pitched and bought through out the history of business tools. (For those new to the game or only been paying attention for the last 15 years, a huge hint, THERE IS NO MAGIC PILL).
Tale of 2 Tunnels
One comment I made yesterday is, "the difference between Web 2.0 and Enterprise 2.0 is like the difference building a tunnel through rock and tunnel under water".
That this is getting at is Web 2.0 takes work to build to get through the earth, but once built it can suffer from imperfections and still work well. The tunnel can crack and crumble a little, but still get used with diminished capacity. We can look at Facebook, which has a rather poor interface and still gets used. Twitter is another example of a Web 2.0 solution that has its structural deficiencies and outages, but it still used as well as still loved (their Fail Whale is on a t-shirt now and a badge of pride worn by loyal users).
The Enterprise 2.0 tunnel is built under water. This takes more engineering understanding, but it also requires more fault testing and assurances. A crack or crumbling of a tool inside an organization is not seen kindly and raises doubts around the viability of the tool. The shear volume of users inside an organization using these tools is orders of magnitude less than in the open consumer web world, but faults are more deadly.
The other important factor is perceived fear of the environment. Fewer people (by pure numbers - as the percentages are likely the same, more on this later) are fearful of tunnels through land, they may not have full faith in them, but they know that they will likely make it safely on all of their journeys. The tunnels under water have greater fears as one little crack can cause flooding and drowning quickly. Fears of use of social tools inside an organization is often quite similar, there may be many that are not fearful, but if you spend time talking to people in organizations not using tools (it is the majority at this point) they are fearful of open sharing as that could lead to trouble. People are not comfortable with the concept as they are foreign to it as they are lacking the conceptual models to let them think through it.
Enterprise 2.0 is not Web 2.0
Another statement yesterday that garnered a lot of feedback was, "Web 2.0 does not work well in enterprise, but the approaches and understandings of Web 2.0 modified for enterprise work really well." The web is not enterprise or smaller organizations for that matter. The open consumer web has different scale and needs than inside organizations and through their firewalls. A small percentage of people using the web can get an account on a tool have have appear to be wildly successful correctly claiming 70 million or 100 million people are or have used their tool. But, even 100 million people is a small percentage of people using the web. Looking at real usage and needs for those tools the numbers are really smaller. Most darlings of the Web 2.0 phase have fewer than 10 million users, which is about 5% of the open consumer web users in the United States. On the web a start-up is seen as successful with 500,000 users after a year or two and is likely to have the capability to be self sufficient at that level too. Granted there are many players in the same market niches on the web and the overall usage for link sharing and recommending for Digg, Mixx, or Reddit is much higher across the sum of these tools than in just one of these tools (obviously).
These percentages of adoption and use inside organizations can make executives nervous that their money is not reaching as many employees as they wish. The percentages that can be similar to the web's percentages of high single digit adoption rates to the teens is seen as something that really needs more thinking and consideration.
Enterprise 2.0 is more than just tools (see my Enterprise Social Tools: Components for Success for better understanding) as it also includes interface/interaction design for ease of use, sociality, and encouragement of use. The two biggest factors that are needed inside an organization that can receive less attention on the web are the sociality and encouragement of use.
Understanding sociality is incredibly important inside an organization as people are used to working in groups (often vertical in their hierarchy) that have been dictated to them for use. When the walls are broken down and people are self-finding others with similar interests and working horizontally and diagonally connecting and sharing with others and consuming the collective flows of information their comfortable walls of understanding are gone. A presentation in Copenhagen at Reboot on Freely Seeping Through the Walls of the Garden focussed just on this issue. This fear inside the enterprise is real. Much of the fear is driven by lacking conceptual models and understanding the value they will derive from using the tools and services. People need to know who the other people are that they are sharing with and what their motivations are (to some degree) before they have comfort in sharing themselves.
Encouraging use is also central to increased adoption inside organizations. Many organizations initial believe that Web 2.0 tools will take off and have great adoption inside an organization. But, this is not a "build it and they will come" scenario, even for the younger workers who are believed to love these tools and services and will not stay in a company that does not have them. The reality is the tools need selling their use, value derived from them, the conceptual models around what they do, and easing fears. Adoption rates grow far beyond the teen percentages in organizations that take time guiding people about the use of the tools and services. Those organizations that take the opportunity to continually sell the value and use for these tools they have in place get much higher adoption and continued engagement with the tools than those who do nothing and see what happens.
Gaps in Enterprise Tools
The last related statement was around the gaps in current and traditional enterprise tools. At the fantastic Jive Enterprise UI Summit in Aspen a few weeks ago there was a lot of discussion about enterprise tools, their UI, and ease of use for employees by the incredible collection of people at the event. One of the things that was shown was a killer path of use through a wide encompassing enterprise toolset that was well designed and presented by SAP's Dan Rosenberg who has done an incredible job of putting user experience and thinking through the needed workflows and uses of enterprise tools at the forefront of enterprise software planning. Given the excellent design and incredible amount of user experience thought that went into the tools behind the SAP toolset in the scenario (one of the best I have seen - functioning or blue sky demoed) there are still gaps. Part of this is identifying of gaps comes from traditional business thinking around formal processes and the tools ensure process adherence. But, the reality is the tools are quite often inflexible (I am not talking about SAP tools, but traditional enterprise tools in general), the cost of time and effort is beyond the gain for individuals to document and annotate all decisions and steps along the way. The hurdles to capture information and share it are often too large for capturing one to 10 quick sentences of information that can be retained for one's own benefit or shared with other where it is relevant.
There is another gap in business around the collective intelligence that is needed, which can lead to collaboration. Most businesses and their tools focus on collaboration and set groups, but at the same time wonder why they do not know what their company knows and knowledge is not all being captured. First there is a difference between collective and collaborative activities and the tools and design around and for those different activities is more than a nuance of semantics it is a huge barrier to capturing, sharing, and learning from information that leads to knowledge if it is not understood well. Enterprise has gone through its phases of knowledge management tools, from forms for capturing information, forums for sharing, and up to enterprise content management systems (ECM) that encompass document management, content management, knowledge management, and information harvesting. But, the gaps still exist.
These existing gaps are around conversations not being captured (the walls of the halls have no memory (well today they do not)) and increasingly the ubiquitous communication channel in organizations, e-mail, is being worked around. Quick decisions are not being documented as it is not enough for a document or worth completing a form. As the iterative processes of development, design, and solution engineering are happening at quicker and smaller increments the intelligence behind the decisions is not being captured or shared. This is largely because of the tools.
As has always been the case large enterprise systems are worked around through the use of smaller and more nimble solutions that augment the existing tools. Even in Dan's incredible demo I saw gaps for these tools. The quick tools that can fill these gaps are blogs, wikis, social bookmarking, tagging, Twitter type sharing, Veodia type video sharing, instant messaging, etc. There are many avenues to quickly capture information and understanding and share it. These tools get out of the way and allow what is in someone's head to get digitized and later structured by the individual themselves or other people whom have had the information shared with them in a community space. This turns into flows through streams that can be put into many contexts and needs as well as reused as needed.
Another point Dan stated at the Enterprise UI Summit that is dead on, is organizations are moving out of the vertical structures and moving to the horizontal. This is having a profound effect on the next generation of business tools and processes. This is also an area for Enterprise 2.0 tools as they easily open up the horizontal and diagonal prospects and tie into it the capability for easily understanding who these newly found people are in an organization through looking at their profiles, which eases their fears around sharing and unfamiliar environments as well as their related tasks.
[Comments are open and moderated at Tale of Two Tunnels: Web 2.0 and Enterprise 2.0 :: Personal InfoCloud]
Speaking at the International Forum on Enterprise 2.0 Near Milan, Italy
Under a month from now I have the wonderful pleasure of speaking at the International Forum on Enterprise 2.0, this is just outside of Milan in Varese, Italy on June 25, 2008. I am really looking forward to this event as there are many people whom I chat with on Skype with and chat with in other ways about enterprise and the use of social tools inside these organizations. It is a wonderful opportunity to meet them in person and to listen to them live as they present. Already I know many people attending the event from the United Kingdom, Switzerland, Germany, Austria, Spain, and (of course) Italy. If you are in Europe and have interest this should be a great event to get a good overview and talk with others with interest and experience. Oh, did I mention the conference is FREE?
I will be presenting an overview on social bookmarking and folksonomy and the values that come out of these tools, but also the understanding needed to make good early decisions about the way forward.
I look forward to meeting those of you who attend.
Enterprise 2.0 Boston - After Noah: What to do After the Flood (of Information)
I am looking forward to being at the Enterprise 2.0 Conference in Boston from June 10 to June 12, 2008. I am going to be presenting on June 10, 2008 at 1pm on After Noah: Making Sense of the Flood (of Information). This presentation looks at what to expect with social bookmarking tools inside an organization as they scale and mature. It also looks at how to manage the growth as well as encourage the growth.
Last year at the same Enterprise 2.0 conference I presented on Bottom-up Tagging (the presentation is found at Slideshare, Bottom-up All the Way Down: How Tags Help Businesses Organize, which has had over 8,800 viewing on Slideshare), which was more of a foundation presentation, but many in the audience were already running social bookmarking services in-house or trying them in some manner. This year my presentation is for those with an understanding of what social bookmarking and folksonomy are and are looking for what to expect and how to manage what is happening or will be coming along. I will be covering how to manage heavy growth as well as how to increase adoption so there is heavy usage to manage.
I look forward to seeing you there. Please say hello, if you get a chance.
Enterprise Social Tools: Components for Success
One of the things I continually run across talking with organizations deploying social tools inside their organization is the difficultly getting all the components to mesh. Nearly everybody is having or had a tough time with getting employees and partners to engage with the services, but everybody is finding out it is much more than just the tools that are needed to consider. The tools provide the foundation, but once service types and features are sorted out, it get much tougher. I get frustrated (as do many organizations whom I talk with lately) that social tools and services that make up enterprise 2.0, or whatever people want to call it, are far from the end of the need for getting it right. There is great value in these tools and the cost of the tools is much less than previous generations of enterprise (large organization) offerings.
Social tools require much more than just the tools for their implementation to be successful. Tool selection is tough as no tool is doing everything well and they all are focussing on niche areas. But, as difficult as the tool selection can be, there are three more elements that make up what the a successful deployment of the tools and can be considered part of the tools.
Four Rings of Enterprise Social Tools
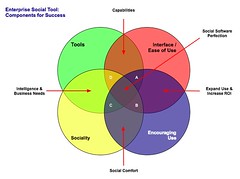 The four elements really have to work together to make for a successful services that people will use and continue to use over time. Yes, I am using a venn diagram for the four rings as it helps point out the overlaps and gaps where the implementations can fall short. The overlaps in the diagram is where the interesting things are happening. A year ago I was running into organizations with self proclaimed success with deployments of social tools (blogs, wikis, social bookmarking, forums, etc.), but as the desire for more than a simple set of blogs (or whichever tool or set of tools was selected) in-house there is a desire for greater use beyond some internal early adopters. This requires paying close attention to the four rings.
The four elements really have to work together to make for a successful services that people will use and continue to use over time. Yes, I am using a venn diagram for the four rings as it helps point out the overlaps and gaps where the implementations can fall short. The overlaps in the diagram is where the interesting things are happening. A year ago I was running into organizations with self proclaimed success with deployments of social tools (blogs, wikis, social bookmarking, forums, etc.), but as the desire for more than a simple set of blogs (or whichever tool or set of tools was selected) in-house there is a desire for greater use beyond some internal early adopters. This requires paying close attention to the four rings.
Tools
The first ring is rather obvious, it is the tools. The tools come down to functionality and features that are offered, how they are run (OS, rack mount, other software needed, skills needed to keep them running, etc.), how the tools are integrated into the organization (authentication, back-up, etc.), external data services, and the rest of the the usual IT department checklist. The tools get a lot of attention from many analysts and tech evangelists. There is an incredible amount of attention on widgets, feeds, APIs, and elements for user generated contribution. But, the tools do not get you all of the way to a successful implementation. The tools are not a mix and match proposition.
Interface & Ease of Use
One thing that the social software tools from the consumer web have brought is ease of use and simple to understand interfaces. The tools basically get out of the way and bring in more advanced features and functionality as needed. The interface also needs to conform to expectations and understandings inside an organization to handle the flow of interaction. What works for one organization may be difficult for another organization, largely due to the tools and training, and exposure to services outside their organization. Many traditional enterprise tools have been trying to improve the usability and ease of use for their tools over the last 4 to 5 years or so, but those efforts still require massive training and large binders that walk people through the tools. If the people using the tools (not administering the tools need massive amounts of training or large binders for social software the wrong tool has been purchased).
Sociality
Sociality is the area where people manage their sharing of information and their connections to others. Many people make the assumption that social tools focus on everything being shared with everybody, but that is not the reality in organizations. Most organizations have tight boundaries on who can share what with whom, but most of those boundaries get in the way. One of the things I do to help organizations is help them realize what really needs to be private and not shared is often much less than what they regulate. Most people are not really comfortable sharing information with people they do not know, so having comfortable spaces for people to share things is important, but these spaces need to have permeable walls that encourage sharing and opening up when people are sure they are correct with their findings.
Sociality also includes the selective groups people belong to in organizations for project work, research, support, etc. that are normal inside organizations to optimize efficiency. But, where things get really difficult is when groups are working on similar tasks that will benefit from horizontal connections and sharing of information. This horizontal sharing (as well as diagonal sharing) is where the real power of social tools come into play as the vertical channels of traditional organization structures largely serve to make organizations inefficient and lacking intelligence. The real challenge for the tools is the capability to surface the information of relevance from selective groups to other selective groups (or share information more easily out) along the way. Most tools are not to this point yet, largely because customers have not been asking for this (it is a need that comes from use over time) and it can be a difficult problem to solve.
One prime ingredient for social tool use by people is providing a focus on the people using the tools and their needs for managing the information they share and the information from others that flow through the tool. Far too often the tools focus on the value the user generated content has on the system and information, which lacks the focus of why people use the tools over time. People use tools that provide value to them. The personal sociality elements of whom are they following and sharing things with, managing all contributions and activities they personally made in a tool, ease of tracking information they have interest in, and making modifications are all valuable elements for the tools to incorporate. The social tools are not in place just to serve the organization, they must also serve the people using the tools if adoption and long term use important.
Encouraging Use
Encouraging use and engagement with the tools is an area that all organizations find they have a need for at some point and time. Use of these tools and engagement by people in an organization often does not happen easily. Why? Normally, most of the people in the organization do not have a conceptual framework for what the tools do and the value the individuals will derive. The value they people using the tools will derive needs to be brought to the forefront. People also usually need to have it explained that the tools are as simple as they seem. People also need to be reassured that their voice matters and they are encouraged to share what they know (problems, solutions, and observations).
While the egregious actions that happen out on the open web are very rare inside an organization (transparency of who a person is keeps this from happening) there is a need for a community manager and social tool leader. This role highlights how the tools can be used. They are there to help people find value in the tools and provide comfort around understanding how the information is used and how sharing with others is beneficial. Encouraging use takes understanding the tools, interface, sociality, and the organization with its traditions and ways of working.
The Overlaps
The overlaps in the graphic are where things really start to surface with the value and the need for a holistic view. Where two rings over lap the value is easy to see, but where three rings overlap the missing element or element that is deficient is easier to understand its value.
Tools and Interface
Traditional enterprise offerings have focussed on the tools and interface through usability and personalization. But the tools have always been cumbersome and the interfaces are not easy to use. The combination of the tools and interface are the core capabilities that traditionally get considered. The interface is often quite flexible for modification to meet an organizations needs and desires, but the capabilities for the interface need to be there to be flexible. The interface design and interaction needs people who have depth in understanding the broad social and information needs the new tools require, which is going to be different than the consumer web offerings (many of them are not well thought through and do not warrant copying).
Tools and Sociality
Intelligence and business needs are what surface out of the tools capabilities and sociality. Having proper sociality that provides personal tools for managing information flows and sharing with groups as well as everybody as it makes sense to an individual is important. Opening up the sharing as early as possible will help an organization get smarter about itself and within itself. Sociality also include personal use and information management, which far few tools consider. This overlap of tools and sociality is where many tools are needing improvement today.
Interface and Encouraging Use
Good interfaces with easy interaction and general ease of use as well as support for encouraging use are where expanding use of the tools takes place, which in turn improves the return on investment. The ease of use and simple interfaces on combined with guidance that provides conceptual understanding of what these tools do as well as providing understanding that eases fears around using the tools (often people are fearful that what they share will be used against them or their job will go away because they shared what they know, rather than they become more valuable to an organization by sharing as they exhibit expertise). Many people are also unsure of tools that are not overly cumbersome and that get out of the way of putting information in to the tools. This needs explanation and encouragement, which is different than in-depth training sessions.
Sociality and Encouraging Use
The real advantages of social tools come from the combination of getting sociality and encouraging use correct. The sociality component provides the means to interact (or not) as needed. This is provided by the capabilities of the product or products used. This coupled with a person or persons encouraging use that show the value, take away the fears, and provide a common framework for people to think about and use the tools is where social comfort is created. From social comfort people come to rely on the tools and services more as a means to share, connect, and engage with the organization as a whole. The richness of the tools is enabled when these two elements are done well.
The Missing Piece in Overlaps
This section focusses on the graphic and the three-way overlaps (listed by letter: A; B; C; and D). The element missing in the overlap or where that element is deficient is the focus.
Overlap A
This overlap has sociality missing. When the tool, interface, and engagement are solid, but sociality is not done well for an organization there may be strong initial use, but use will often stagnate. This happens because the sharing is not done in a manner that provides comfort or the services are missing a personal management space to hold on to a person's own actions. Tracking one's own actions and the relevant activities of others around the personal actions is essential to engaging socially with the tools, people, and organization. Providing comfortable spaces to work with others is essential. One element of comfort is built from know who the others are whom people are working with, see Elements of Social Software and Selective Sociality and Social Villages (particularly the build order of social software elements) to understand the importance.
Overlap B
This overlap has tools missing, but has sociality, interface, and encouraging use done well. The tools can be deficient as they may not provide needed functionality, features, or may not scale as needed. Often organizations can grow out of a tool as their needs expand or change as people use the tools need more functionality. I have talked with a few organizations that have used tools that provide simple functionality as blogs, wikis, or social bookmarking tools find that as the use of the tools grows the tools do not keep up with the needs. At times the tools have to be heavily modified to provide functionality or additional elements are needed from a different type of tool.
Overlap C
Interface and ease of use is missing, while sociality, tool, and encouraging use are covered well. This is an area where traditional enterprise tools have problems or tools that are built internally often stumble. This scenario often leads to a lot more training or encouraging use. Another downfall is enterprise tools are focussed on having their tools look and interact like consumer social web tools, which often are lacking in solid interaction design and user testing. The use of social tools in-house will often not have broad use of these consumer services so the normal conventions are not understood or are not comfortable. Often the interfaces inside organizations will need to be tested and there many need to be more than one interface and feature set provided for depth of use and match to use perceptions.
Also, what works for one organization, subset of an organization, or reviewer/analyst will not work for others. The understanding of an organization along with user testing and evaluation with a cross section of real people will provide the best understanding of compatibility with interface. Interfaces can also take time to take hold and makes sense. Interfaces that focus on ease of use with more advanced capabilities with in reach, as well as being easily modified for look and interactions that are familiar to an organization can help resolve this.
Overlap D
Encouraging use and providing people to help ease people's engagement is missing in many organizations. This is a task that is often overlooked. The tools, interface, and proper sociality can all be in place, but not having people to help provide a framework to show the value people get from using the tools, easing concerns, giving examples of uses for different roles and needs, and continually showing people success others in an organization have with the social tool offerings is where many organization find they get stuck. The early adopters in an organization may use the tools as will those with some familiarity with the consumer web social services, but that is often a small percentage of an organization.
Summary
All of this is still emergent and early, but these trends and highlights are things I am finding common. The two areas that are toughest to get things right are sociality and encouraging use. Sociality is largely dependent on the tools, finding the limitations in the tools takes a fair amount of testing often to find limitations. Encouraging use is more difficult at the moment as there are relatively few people who understand the tools and the context that organizations bring to the tools, which is quite different from the context of the consumer social web tools. I personally only know of a handful or so of people who really grasp this well enough to be hired. Knowing the "it depends moments" is essential and knowing that use is granular as are the needs of the people in the organization. Often there are more than 10 different use personas if not more that are needed for evaluating tools, interface, sociality, and encouraging use (in some organizations it can be over 20). The tools can be simple, but getting this mix right is not simple, yet.
[Comments are open and moderated at Enterprise Social Tools: Components for Success :: Personal InfoCloud